Contextual Word Embedding
This post is mainly based on
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2018
- RoBERTa: A Robustly Optimized BERT Pretraining Approach, 2019
A Word Embedding maps words to vectors in the embedding space. One problem with this approach is it cannot properly represent words with multiple meanings. The word “bank” could mean a financial institution or an area bordering a lake or river. The semantics of “bank” is determined by the words around it, namely its context.
Contextual Word Embedding solve this problem by mapping words to vectors using Attention Mechanism. The semantics of “bank” is determined by itself and the words around it. There are several ways to implement this idea:
- BERT: bidirectional transformer
- GPT: unidirectional transformer
- ELMo: two independent LSTM trained in opposite direction
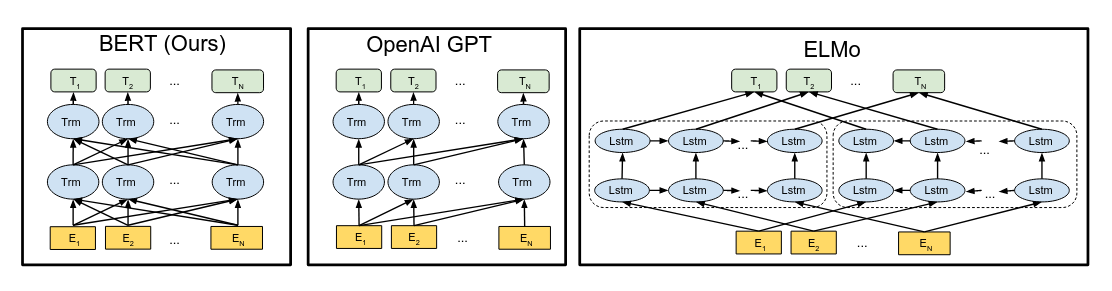
BERT and GPT are more widely used today. GPT is more suitable for sequence generation tasks due to its unidirectional architecture. BERT has better performance in language understanding tasks.
BERT
BERT is the abbreviation for Bidirectional Encoder Representations from Transformers. It is a pre-train deep bidirectional representation for words. At the time of publishing, BERT outperformed all SOTA results on 11 NLP tasks (which is quite impressive) and improved the GLUE score to 80.5% (7.7% point absolute improvement). Personally, I think the key to its success is:
- Trained on very large data
- Bidirectional architecture
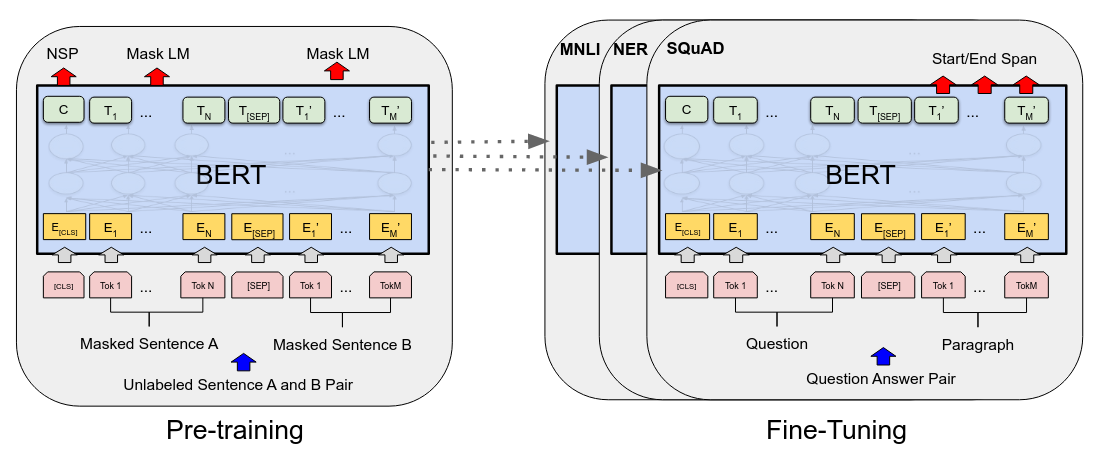
Masked Language Model
BERT is trained by masked language model (MLM). The MLM randomly masked some input tokens and the task of BERT is to predict the masked tokens. This pre-training objective have one major advantage: it allows a bidirectional architecture.
A regular transformer or GPT is trained on masked self attention: given a sequence of tokens, the model can only observe the tokens to the left of the next word (otherwise the prediction task will be trivial to solve). The problem with this approach is that the model can only incorporate information to each word’s left to the contextual word embedding, which is sub-optimal. BERT’s pre-training task is not limited by this problem, which permits a bidirectional architecture.
BERT randomly “masks” 15% of the input tokens during pre-training. To keep consistency between pre-training and fine-tuning (there is no masked tokens in fine-tuning), each would be “masked” token will be further processed:
- Still be masked with [MASK] token 80% probability
- Replaced by a random token with 10% probability
- Replaced by the correct input token with 10% probability
Regardless of further processing result, the 15% “masked” token will be predicted with cross entropy loss.
Next Sentence Prediction
Apart from the MLM task, BERT also trained on next sentence prediction (NSP) task. Two sentence (sentence A & B) will be chosen as the input:
- Sentence B is the next sentence of A with 50% probability
- Sentence B is randomly sampled from corpus with 50% probability
- According to RoBERTa, the A and B part are segment of multiple sentences, instead of one sentence
The goal is
- For the model to learn long range dependency between sentences
- For the model to properly distinguish <Source text, Question> in tasks like SQuAD
Input/Output Representations
The goal is to unambiguously represent both a single sentence and a pair of sentences in one token sequence. BERT use WordPiece with a 30,000 token vocabulary as its tokenizer.
Special tokens
- [CLS] token
- The first token of every sequence
- The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks (e.g., for sentiment analysis)
- [SEP] token
- Separate the pair of sentence
- [MASK] token
- for MLM masking input
Output
- [C] hidden vector (beginning of sequence ask [CLS] token)
- Output for classification task (e.g., True or False in NSP task)
- Depending on tasks, subsequent tokens may or may not be useful
- For classification tasks, subsequent tokens is not useful and no gradient is computed
- For SQuAD, subsequent tokens will be used to predict [Start] [End] position for the answer
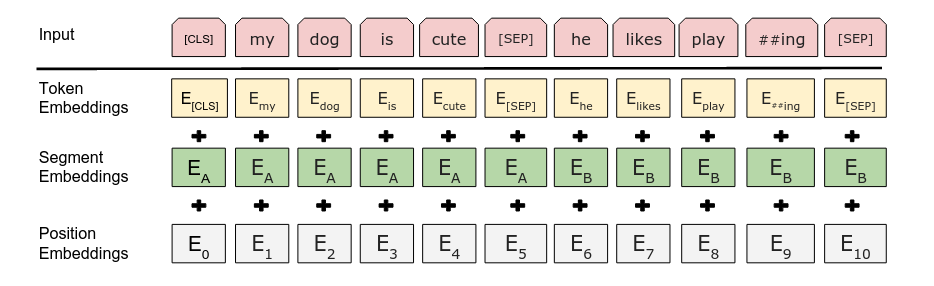
Embeddings
BERT maps a sequence of input tokens to 3 embedding: Token Embedding, Segment Embedding, Position Embedding. The input representation is constructed by summing the corresponding token, segment, and position embeddings.
- Token Embedding
- Just a trainable look up dictionary of embedding vectors
- Segment Embedding
- Used to differentiate two sentences
- Consists of two learnable vectors
- Position Embedding
- Used to encode positional information
- A key difference between BERT and Transformer is that
- BERT uses a learnable Position Embedding
- Transformer uses a deterministic sin/cos Positional Encoding
Model Architecture
- Multi-layer bidirectional Transformer
- Definition
- L = number of layers / Transformer blocks
- H = hidden size
- A = number of self-attention heads
- Configuration
- BERT BASE: L=12, H=768, A=12, Total Parameters=110M (same model size as OpenAI GPT)
- BERT LARGE: L=24, H=1024, A=16, Total Parameters=340M
- Optimizer: Adam
- $\beta_1 = 0.9$, $\beta_2 = 0.999$, $\epsilon = 1e-6$,
- L2 weight decay = $0.01$
- Learning rate is warmed up over the first 10,000 steps to a peak value of $1e-4$ and then linearly decayed
- Pretrained for $S = 1,000,000$ updates
- Regularization
- Dropout of 0.1 on all layers and attention weights
- Batch
- Batch size = 256
- Maximum sequence length = 512 tokens
Pre-training / Fine-tuning
Pre-training data
- BooksCorpus (800M words)
- English Wikipedia (2,500M words)
- Totals 16GB of uncompressed text
For fine-tuning speed, the author stated that using a pre-trained model, all of the results in the paper can be replicated in at most 1 hour on a single Cloud TPU, or a few hours on a GPU.
Experiments
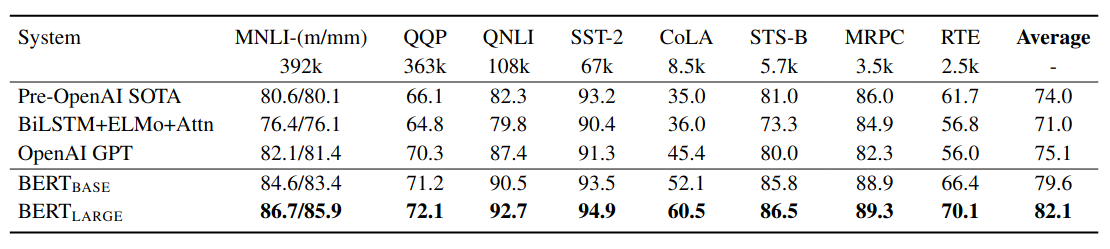
GLUE Test results, scored by the evaluation server
BERT also achieve SOTA result on SQuAD:
- SQuAD 1.1
- Human test F1: 91.2
- SOTA model F1: 91.7
- BERT F1: 93.2
- SQuAD 2.0
- Human test F1: 89.5
- SOTA model F1: 78.0
- BERT F1: 83.1
Ablation Studies
Ablation studies suggest that NSP task and bidirectional architecture has improve performance on downstream tasks. However, further studies in RoBERTa suggests that NSP task is not necessary when trained with a modified input data schema.
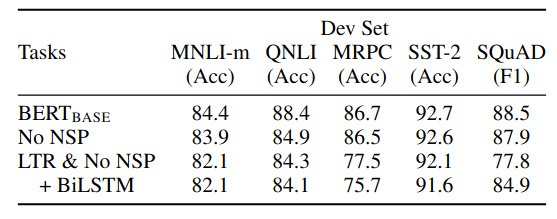
BERT BASE architecture. “No NSP” is trained without the next sentence prediction task. “LTR & No NSP” is trained as a left-to-right LM without the next sentence prediction. “+ BiLSTM” adds a randomly initialized BiLSTM on top of the “LTR + No NSP” model during fine-tuning.
RoBERTa
RoBERTa is the abbreviation for Robustly Optimized BERT Pretraining Approach. This paper could be viewed as a ablation study of BERT. The authors demonstrated that with correct hyperparameter, input format, larger data and longer pretraining, BERT LARGE can achieve same performance as its variants like XLNet LARGE.
The authors conclude that the original BERT was significantly undertrained and the proposed Robustly Optimized BERT, or RoBERTa, is competitive with all other recently published methods (in 2019).
Larger Data and Longer Pretraining
- BERT: BooksCorpus + English Wikipedia (16GB)
- Additional data for RoBERTa
- CommonCrawl News dataset (76GB after filtering)
- OPEN WEB TEXT (38GB)
- STORIES (31GB)
Scale of experiment: We pretrain our model using 1024 V100 GPUs for approximately one day.
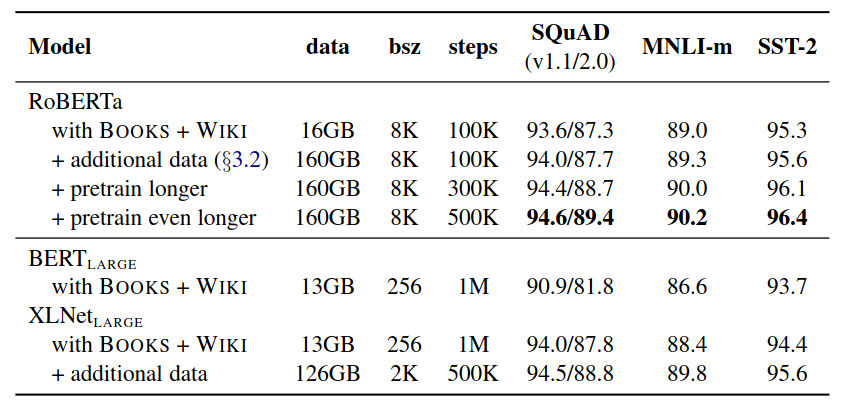
More data: 16GB -> 160GB of text. Pretrain for longer: 100K -> 300K -> 500K steps.
Static vs Dynamic Masking
- BERT uses static masking
- Masking occurred during data preprocessing and updated periodically (40 epochs)
- Training data was duplicated 10 times, hence each sequence is masked in 10 different ways
- A single static mask is used for 4 times in training
- RoBERTa uses dynamic masking
- Masking occurred when the data is fed to the model
Result: dynamic masking is slightly better in 2 tasks and slightly worse in 1 task
Input Format and NSP Task
- BERT’s input is sentence pair
- SEGMENT-PAIR: pair of segments, each contain multiple natural sentences
- SENTENCE-PAIR: pair of natural sentences
- RoBERTa’s input is continue to feed sentence until the length reach 512 tokens
- FULL-SENTENCES: full sentences sampled contiguously until max length
- DOC-SENTENCES: full sentences sampled contiguously until max length, without crossing document boundaries
Removing NSP does not hurt RoBERTa’s performance.
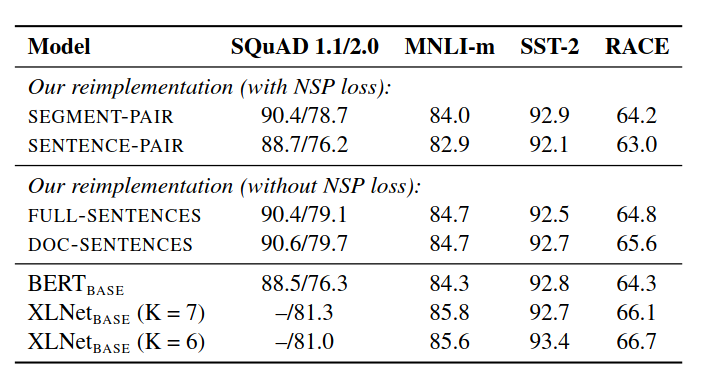
Base models pretrained over BOOKCORPUS and WIKIPEDIA
Batch size
- BERT’s batch size: 256
- RoBERTa’s batch size: 2K, 8K
Larger batch result in better performance.
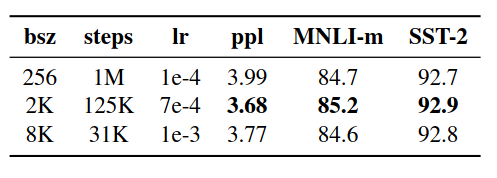
ppl: Perplexity on held-out training data
Hyperparameters
- Adjusted peak learning rate and number of warmup steps
- Training to be very sensitive to the Adam epsilon term
- $\beta_2 = 0.98$ improves stability when training with large batch sizes