NLP Evaluation
This post is mainly based on
- Dr. Brendan O’Connor’s slides
- Chip Huyen’s Blog
- BLEU: a Method for Automatic Evaluation of Machine Translation
- SQuAD: 100,000+ Questions for Machine Comprehension of Text
- GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
NLP evaluating is a complicated topic. One problem is there are many NLP tasks: sentiment analysis, machine translation, text summarization, question answering, etc. One metric that is appropriate to evaluate one task may fails at other tasks.
There is also a distinction between the language model and downstream tasks. A language model is a probability distribution over sequences of words. Given a sequence of $m$ tokens, a language model assigns a probability $P( w_1, … , w_m )$ to the sequence. Equipped with a language model, we can generate language: compute the conditional probability $P(w_{m+1} | w_1, … , w_m) = \frac{P( w_1, … , w_m, w_{m+1} )}{P (w_1, … , w_m )}$ for all possible words, and then sample from this distribution to generate the next word. A metric can evaluate the language model itself or evaluate the downstream tasks:
- Intrinsic Evaluation
- Measure how well the model approximates unseen language.
- Given a corpus, compute the probability of each sentence using to the language model.
- Extrinsic Evaluation
- Apply the language model in an application and then evaluate the application.
- Classification tasks (e.g., sentiment analysis) are easy to evaluate.
- One-to-one sequence modelling (e.g., speech recognition) can be evaluated by word error rate (WER).
- Machine translation is more complicated (e.g., need to evaluate both syntax and semantics).
If the intrinsic evaluation score is correlated with the extrinsic evaluation score is an open questions as improved performance on the language model does not always lead to improvement on the downstream tasks.
Perplexity
Definition
Given a corpus of $m$ sentences $\mathcal{S} = \{s_1, …, s_m\}$. Let $M$ be the total number of tokens in the corpus. Perplexity is defined as
\[\operatorname{PP} = 2^{-l}\]where
\[l = \frac{1}{m} \sum_{i=1}^m \log p(s_i)\]The short answer is: perplexity (per word) measures how well the n-gram model predicts the sample. Lower perplexity = better model.
- Assume we are predicting one word at a time
- A bad language model
- Does not learn the structure of the language and assume all successor words are equally likely
- It predict next word with with uniform distribution
- Perplexity is equal to vocabulary size
- A good language model
- Learn the structure of the language, both syntax and semantics, and assume some successor words are more likely
- It predict next word with with skewed distribution
- Perplexity is lower
The long answer requires cross entropy. If you are not familiar with cross entropy, check out this post.
The definition of perplexity can be write in another way: consider a language with ground truth distribution $p(s)$ and a language model which learns a distribution $q(s)$. The cross entropy $H(p,q)$ is:
\[H(p,q) = \sum_{s \in \mathcal{S}} p(s) \log q(s) = \mathbb{E}_{s \sim \mathcal{S}}[ \log q(s)]\]and the perplexity can be written as
\[\operatorname{PP} = 2^{H(p,q)}\]The reason why Lower perplexity = better model is obvious:
- A good language model learns the distribution $q(s)$ that closely approximate $p(s)$
- $H(p,q)$ is lower, hence \(\operatorname{PP} = 2^{H(p,q)}\) is lower
However, we need to be careful when comparing two language model using the perplexity metric, due to:
- Need to check the base of $\log$, modern deep learning framework compute entropy $\ln$ base instead of $\log_2$ base
- Need to check if the model is character-level or word-level, as their perplexity are not comparable
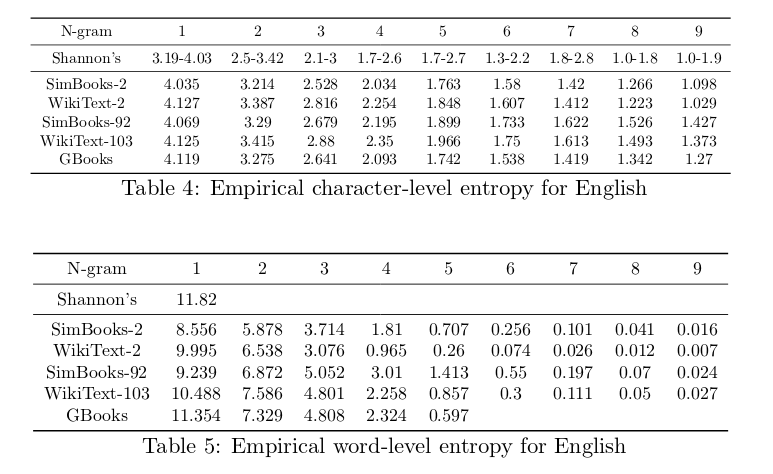
Figure from Chip Huyen’s Blog
An interesting paper to read is Shannon’s 1951 paper Prediction and entropy of printed English
BLEU
BLEU stands for BiLingual Evaluation Understudy. It is a metric for machine translation (MT) evaluation.
MT evaluation is complicated, due to
- There is no single correct output (typically use multiple reference translations)
- Need to evaluate faithfulness and fluency, but both are subjective
BLEU evaluate a target translation with geometric average of modified n-gram precision from multiple reference translation, and penalize the translation if it exceed certain length. Recall is not considered.
Modified n-gram precision
To avoid overgenerate “reasonable” words.
- Counts the maximum number of times a word occurs in any single reference translation
- Clip the count of each candidate word by its maximum reference count

The modified unigram precision in Example 2 is 2/7, even though its standard unigram precision is 7/7.
Geometric average
Let $N$ be the maximum length of n-gram to be averaged and let the uniform weights $w_n = 1 / N$.
\[\begin{align} \operatorname{Geometric average} &= \exp(\sum_{n=1}^N w_n \log p_n ) \\ &= \prod_{n=1}^N p_n^{\frac{1}{N}} \end{align}\]Sentence brevity penalty
Let $c$ be the total length of the candidate translation corpus and $r$ be the effective reference length. The effective reference length is calculated as summing the best match lengths for each candidate sentence in the corpus.
- If $c > r$, $\operatorname{BP} = 1$
- If $c \leq r$, $ \operatorname{BP} = e^{1−r/c}$
BLEU
\[\operatorname{BLEU} = \operatorname{BP} \cdot \exp(\sum_{n=1}^N w_n \log p_n )\]Advantages
- Quick, inexpensive, and language independent
- Correlates highly with human evaluations
Problems
- Bias against synonyms and inflectional variations (same word expressed different grammatical categories such as tense, case, voice, aspect, person, number, gender, mood, animacy, and definiteness)
- Does not consider syntax
- Does not consider recall (missing subject, object or semantically important words)
Question Answering
SQuAD Dataset
SQuAD stands for Stanford Question Answering Dataset. It is a Reading Comprehension test: a model is presented with a text and several associated questions. Each question contains more than one correct answer (SQuAD2.0 also contains unanswerable questions and the model need to determine if the question is answerable based on the text). The model is evaluated based on precision of its answer.

A dataset explore tool is available here
CoQA Dataset
CoQA is a large-scale dataset for building Conversational Question Answering systems.
CoQA tasks are generally harder than SQuAD tasks, due to:
- Longer documents (CoQA passage average words = 271, compared to SQuAD = 117)
- A richer variety of questions
- Q&A spread over multiple turns (change over reference entity)

For details, check CoQA paper: CoQA: A Conversational Question Answering Challenge
A dataset explore tool is available here
A survey over 3 Q&A datasets: A Qualitative Comparison of CoQA, SQuAD 2.0 and QuAC
GLUE
GLUE stands for General Language Understanding Evaluation. The raise of neural language model like BERT stress the importance of transfer learning evaluation. To compute a GLUE score, the language model need to be trained on different datasets and evaluated on 9 different task. The average score is the final performance.
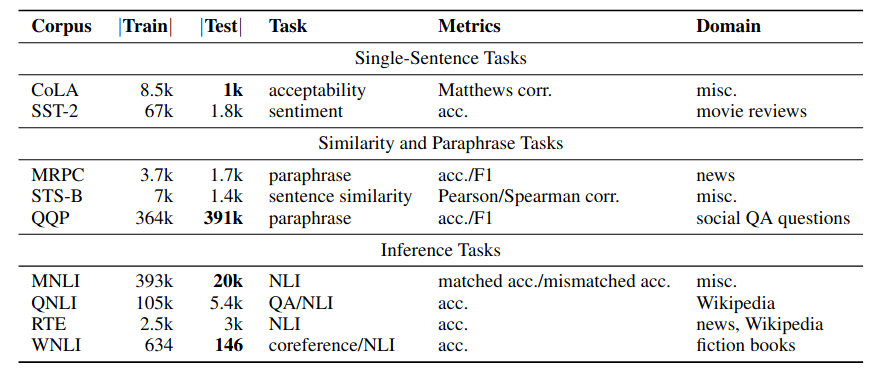
Task descriptions and statistics. All tasks are single sentence or sentence pair classification, except STS-B, which is a regression task.