GPT-1, GPT-2 and GPT-3
This post is mainly based on
- GPT-1: Improving Language Understanding by Generative Pre-Training, 2018
- GPT-2: Language Models are Unsupervised Multitask Learners, 2019
- GPT-3: Language Models are Few-Shot Learners, NIPS 2020
Overview
GPT is abbreviation for Generative Pre-training Transformer. While BERT is stacks of Transformer Encoders, GPT is stacks of Transformer Decoders.
The architectural difference between BERT and GPT:
- BERT: Masked Language Model (MLM)
- A Masked Language Model is trained by predicting masked tokens
- Cannot natural perform next word prediction / text generation
- GPT: Language Model
- A Language Model is a conditional distribution over vocabulary: $P(w_{t} \mid w_{t-1}, \dots , w_{t-k})$
- Can perform next word prediction & text generation
What makes GPT a game changer is its unique approach toward multi-task learning.
Prior to GPT, ML research focused on the old paradigm of “pre-training + fine tuning”. Example of those models include ResNet and BERT. The problem of this paradigm is it still requires collecting a task dataset and an ML engineer to fine tune the model. Removing the “fine-tuning” step would be desirable.
GPT took a different approach: few-shot learning (this term may be referred to meta-learning or in-context learning, see page 4 footnote of GPT-3 paper for details). Researchers believe that model can obtain certain degree of understanding of the world solely by language modeling / learning the conditional distribution of natural language. The model thus can achieve multi-tasking by leveraging the statistical dependency between the task and the desirable output.
To perform a specific task using GPT, you prompt the model (establish the statistical dependency) by a special sequence of tokens or purely by natural language. (e.g., “[French sentence], translate into English:” ). This natural language prompt + multi-tasking ability give GPTs the capacity to seamlessly interact with human. GPT-3’s zero-shot reason capacity (e.g., common sense reasoning, doing arithmetic) indicate that it may has some degree of understanding of the world.
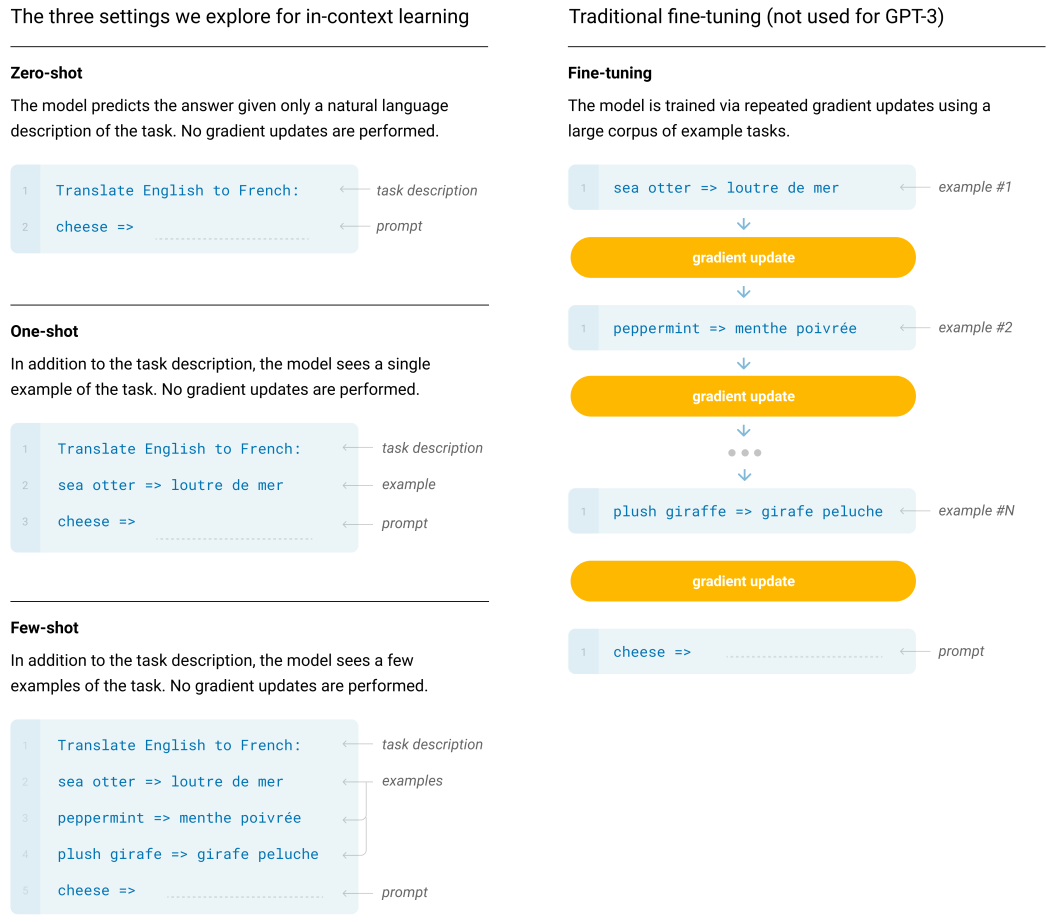
GPT Size and Capacity
| model params | layers | model dimension | Few-shot capacity | |
| GPT-1 | 117M | 12 | 768 | Limited |
| GPT-2 | 1.5B | 48 | 1600 | Lag behind supervised SOTA |
| GPT-3 | 175B | 96 | 12888 | Competitive to supervised SOTA |
Few-shot Capacity
- GTP-1
- Requires prompt and some engineering on output
- Sentiment analysis
- Multiple choice question answering
- GTP-2
- Requires prompt in certain format
- Generally lag behind supervised SOTA
- Reading Comprehension: $F_1 = 0.55$ (SOTA supervised BERT $F_1 = 0.89$)
- Summarization: barely outperform random selection 3 sentences
- Translation: 11.5 BLEU on French to English (SOTA unsupervised model 33.5 BLEU)
- Close Book Question Answering: 4.1% accuracy (Human: 17%, open book system: 30-50%)
- GPT-3
- Surpass or competitive to supervised SOTA on a wide range of tasks
- Can perform tasks that requires reasoning
- Answer questions that requires physical or scientific reasoning
- Performing arithmetic
- Using novel words in a sentence after seeing them defined only once
GPT-1
The first GPT paper still follow the pre-training + fine-tuning paradigm. Note that the Transformer paper publish in 2017 does not focus on multi-task learning and generalization. The original transformer is specifically trained for machine translation (although the paper briefly mentioned that the trained model can generalized to other tasks).
The authors of GPT-1 focus on multi-task learning / foundation model. Their goal is to demonstrate SOTA multi-task learning can be achieved by generative pre-training of a language model on a diverse corpus of unlabeled text. GPT-1 outperforms discriminatively trained models that use architectures specifically crafted for each task in 9 out of the 12 tasks studied.
Loss function
Language model loss:
\[L_u = \sum_i \log P(w_t | w_{t-1}, \dots , w_{t-k}; \theta)\]Supervised loss:
\[L_s = \sum_i \log P(y | x_i; \theta)\]where $x_i$ is the sequence of tokens, $x_i = w_n, … , w_1$.
GPT-1 is pre-trained with language model loss $L_u$ and fine tuned on combined loss $L = L_s + \lambda L_u$
The author conducted ablation studies to demonstrate that using language model loss as an auxiliary loss helped learning by
- Improving generalization of the supervised model
- Accelerating convergence
Task-Specific Input Transformations
Inj multi-task learning, some tasks does not fit into the above supervised loss framework (e.g. for similarity task, the input is a pair of sentences). Previous work introduced task-specific architectures to deal with different task, which requires a lot of engineer and is inefficient. Instead of changing the architecture, GPT-1 chances the input, i.e., “Task-Specific Input Transformations”:
- All transformations requires adding special tokens: <s> for Start, $ for Delim, and <e> for Extract
- Classification: No change to input
- Textual entailment: premise $ hypothesis
- Semantic similarity: average of Text 1 $ Text 2 in both order
- Multiple choice: Softmax over Context $ Answer i
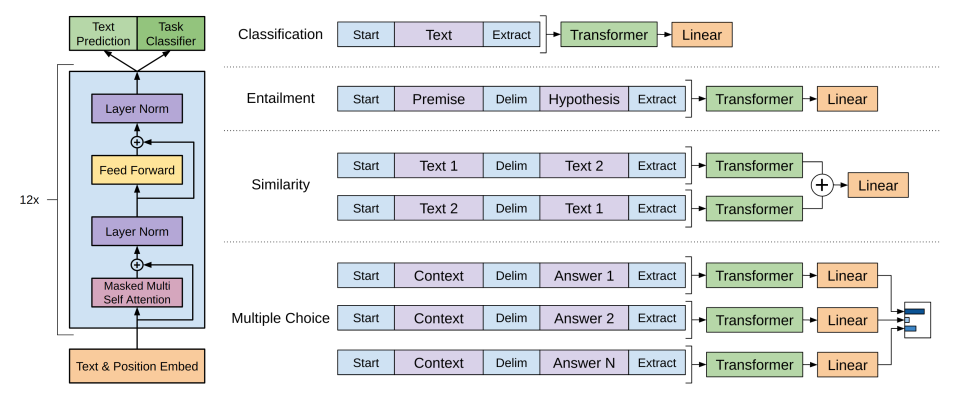
The goal of Task-Specific Input Transformations is to make minimal changes to the architecture in fine tuning.
Model
- Dataset: Book corpus (7000 unpublished books)
- Vocabulary: Byte Pair Encoding (BPE) with 40,000 merges
- Activation: GELU
- Regularization
- Dropout: 0.1 on residual, embedding, and attention layer
- Modified L2 regularization: non bias or gain weights
- Batch size: 64 for training and 32 for fine-tuning
We will skip the results and the 12 tasks studied in this paper since they are pretty outdated.
Zero-shot Behaviors
The authors tried to understand why the above pre-training schema improves the model’s generalization ability. They argue that the in order to become a better language model (i.e., minimize $L_u$ loss), GPT-1 inherently need to be skillful in performing some of the general NLP tasks (to put it in plain language, having a decent understanding of the world).
As explained above, GPT-1 itself is a language model: it can returns a conditional distribution of the next word given a sequence of tokens. To evaluate the model on general NLP tasks without fine tuning, the authors need to formulate those tasks into next word prediction problems. Here is a series of “hacks” they devised:
- Sentiment analysis (SST-2 dataset)
- Append the token “very” to each example
- Restrict the language model’s output distribution to 2 tokens, “positive” and “negative”
- GPT produce a binary output
- Classification = output with higher probability
- Linguistic acceptability (CoLA dataset)
- Classification = threshold on target token’s log-probability assigned by GPT
- Question answering (RACE dataset)
- Append for all choice: Document, Question, Answer
- Use GPT-1 to evaluate the log probability of the entire sequence
- Choice = higher log probability
- Question answering (DPRD dataset / winograd schemas)
- Substitute the binary choice and get 2 sentences
- Use GPT-1 to evaluate the log probability of the rest of sentence after the substitution token
- Choice = higher log probability
Note that the zero-shot output requires heavy engineering (e.g., extract log-probability) in all tasks, which is not really useful in practice. Given the development, we expect a zero-shot model to understand natural language prompt and directly output human interpretable content.
The result demonstrated that as pre-training progress, the model’s ability to achieve zero-shot learning also increased.
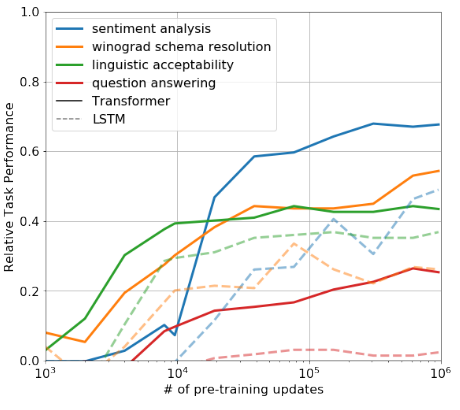
The First Prompt?
Prompt refers to the description of the task embedded in the input that the model is supposed to accomplish.
Below is just my personal guess: the invention of the “prompt learning” strategy may be related to this type of ablation studies. To evaluate the zero-shot sentiment analysis performance, the authors attached the token “very” to the end of the input sentence. This approach appear to be rudimentary and rather looks like some experimental “prompt”. Using today’s standard, we may write more directed prompt, such as: “The previous sentence contains what emotion: positive or negative? A:”, to encourage the model to probe the sentiment-dimension of the next word prediction task.
GPT-2
Unlike its predecessor GPT-1, GPT-2 ditch the “pre-training + fine-tuning” paradigm. The authors does not perform fine-tuning at all in their experiments and the model was evaluated on few-shot & zero-shot tasks (although they mention that they may try finetuning in Section 6. Discussion). There is little change to the model architectures and the paper mostly focused on scaling up the model and the dataset.
The authors discuss Task Conditioning in data and emphasize that the instruction of what task the model should perform can be embedded in the token sequence itself. Due to there is huge amount of “instruction-task” and “question-answer” format task online, the authors hypothesize that the model can achieve multi-task learning by only optimizing for language model loss on a wide range of texts. To test their hypothesis, the authors:
- Scale up the model
- Scale up the dataset
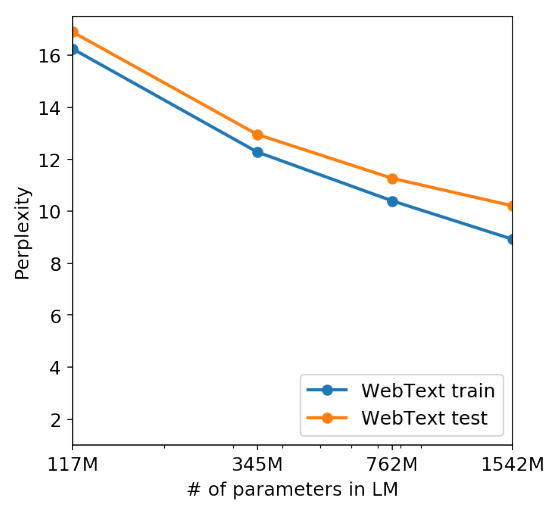
Results: increased performance in multi-task and zero-shot / few shot learning. Given GPT-2’s testing perplexity on WebText is steadily increasing as model size grow, the authors believe that GPT-2 is still underfitting the data.
OpenAI did not release the dataset or the model at the beginning, which stir up a big discussion back then (Yannic Kilcher’s review).
Scaling Up the Dataset
What is Task Conditioning?
Task Conditioning refer to the special clue provides to the model to inform its target task in multi-task learning.
- In single-task learning, a model performs a task by estimating a conditional distribution: $P(output \mid input)$
- In multi-task learning, a model performs a task by estimating a conditional distribution: $P(output \mid input, task)$
Previously, task conditioning is mostly implemented at architectural level (e.g., multiple decoder heads and each group of heads specialized in one task). However, GPT-2’s authors believe that task conditioning can be implemented at data level. For example
- A translation task can be written as the sequence (translate to french, english text, french text)
- A reading comprehension training example can be written as (answer the question, document, question, answer)
Previous Datasets
The authors pointed out that most of the previous work train language models on a single domain of text (e.g, news articles, Wikipedia, fictions). Given their “task conditioning” and “multi-task” learning hypothesis, they want to collect a large and diverse a dataset which contains natural language demonstrations of tasks in as varied of domains and contexts.
They presented several naturally occurring demonstrations of English to French and French to English translation found throughout the WebText training set:
- I’m not the cleverest man in the world, but like they say in French: Je ne suis pas un imbecile [I’m not a fool].
- “I hate the word ‘perfume,”’ Burr says. ‘It’s somewhat better in French: ‘parfum.’
- If this sounds like a bit of a stretch, consider this question in French: As-tu aller au cinéma?, or Did you go to the movies?, which literally translates as Have-you to go to movies/theater?
The WebText Dataset
- Web scrapes like Common Crawl has data quality issues and contains large amount of documents whose content are mostly unintelligible
- The author created The WebText Dataset, which emphasizes document quality (web pages which have been curated/filtered by humans)
- Approach
- Scraped all outbound links from Reddit, a social media platform, which received at least 3 karma
- Posts with high karma indicate other users found the link interesting, educational, or just funny
- Documents are further processed by de-duplication and some heuristic based cleaning
- Result: 8 million documents / 40 GB of text
- All Wikipedia documents remove due to overlapping with test evaluation tasks
Scaling Up the Model
- Vocabulary: 50,257
- Context size: 512 -> 1024 tokens
- Layers: 12 -> 48
- Model dimension: 768 -> 1600
- Num of parameters: 117M -> 1.5B
- Batch size: 64 -> 512
- Layer normalization was moved to input of each sub-block and an additional layer normalization was added after final self-attention block
- At initialisation, the weight of residual layers was scaled by $1/\sqrt{N}$, where N was the number of residual layers
Multi-Task & Few-Shot Learning
- Reading Comprehension
- Dataset: CoQA dataset
- Prompt by: [document], [associated conversations], “A:”
- GPT-2: $F_1 = 0.55$
- SOTA supervised BERT: $F_1 = 0.89$
- Summarization
- Dataset: CNN and Daily Mail dataset
- Prompt by: “TL;DR: “
- First 3 generated sentences in the generated 100 tokens as the summary
- Barely outperform random selection 3 sentences on ROUGE 1,2,L
- Possible to prompt the model by natural language, but performance reduced
- Translation
- Prompt by: [example english] = [example french], [target english] =
- WMT-14 English-French: 5 BLEU
- WMT-14 French-English: 11.5 BLEU on (SOTA unsupervised model 33.5 BLEU)
- Note that non-English webpages is intentionally removed from pre-training dataset
- Training data only contains 10MB of data in the French language (approximately 500x smaller than the monolingual French corpus common used in prior research)
- Close Book Question Answering
- Dataset: SQUAD (evaluation metric: exact match)
- Goal: test what information is contained within model
- Due to there is no access to internet, answer only relies on information stored in its parameters
- GPT-2: 4.1% accuracy (Human: 17%, open book system: 30-50%)
Discussions
Text Generation
GPT-2 is able to
- Adapt to style and content of the conditioning text
- Maintain coherence across the generated text (long term memory)
- Generated text is close to human quality
- Sample text: Better language models and their implications
Generalization vs Memorization
- WebText training set does not overlap with evaluation dataset
- Target datasets: PTB, WikiText-2, enwik8, text8, Wikitext-103, 1BW
- 8 grams overlapping
- WebText train vs target dataset test: 0.88%-3.94% (average: 3.2%)
- Target dataset train vs target dataset test: 0.66%-13.19% (average: 5.9%)
- Increase model capacity => log-linear improvement in zero-shot performance
- GPT-2 is still underfitting the data (see Figure below)
GPT-3
The author hypothesize that higher few-shot performance can be achieved by further scaling up the model, due to:
- Increased model size brought improvements in text synthesis and/or downstream NLP tasks
- Evidence suggest that log loss, which correlates well with many downstream tasks, follows a smooth trend of improvement with scale
- Notable models
- GPT-1: 100M parameters
- BERT: 300M parameters
- GPT-2: 1.5B parameters
- Megatron-LM: 8B parameters
- T5: 11B parameters
- T-NLG: 17B parameters
GPT-3 further scale up the GPT-2 model. Results are:
- While GPT-2 significantly underperforms supervised models, GPT-3 sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches
- GPT-3 can perform tasks that requires some degree of reasoning, for example: unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic
- Qualitative evaluations find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans
However, there are still tasks where GPT-3 has poor few-shot performance:
- Natural language inference: ANLI dataset
- Reading comprehension: RACE dataset, QuAC dataset
Due to the length of the paper (the paper itself is 40 pages long, with a 23 page long appendix), we will only highlight important results in this post.
Model Architecture
- Similar to GPT-2 (modified initialization, pre-normalization, and reversible tokenization)
- Efficient attention implementation
- Alternating dense and locally banded sparse attention
- Sparse Attention from Generating long sequences with sparse transformers, 2019
- Context size: 1024 -> 2048 tokens
- Layers: 48 -> 96
- Model dimension: 1600 -> 12288
- Num of parameters: 1.5B -> 175B
- Batch size: 512 -> 3.2M
- Optimization
- Larger models can typically use a larger batch size, but require a smaller learning rate
- Measure the gradient noise scale during training for choice of batch size
- Clip the global norm of the gradient at 1.0
Dataset
- Common Crawl dataset: filtered + fuzzy deduplication (410B tokens)
- Curated high-quality datasets
- Expanded version of the WebText dataset (19B tokens)
- Books1 and Books2 corpora (67B tokens)
- English-language Wikipedia (3B tokens)
- Overlapping testing sets & Memorization problems (paper Section 2.2 and Section 4)
Few-Shot Learning
Few-shot performance often grows with model capacity, perhaps suggesting that larger models are more proficient meta-learners
Larger models => efficient use of in-context information
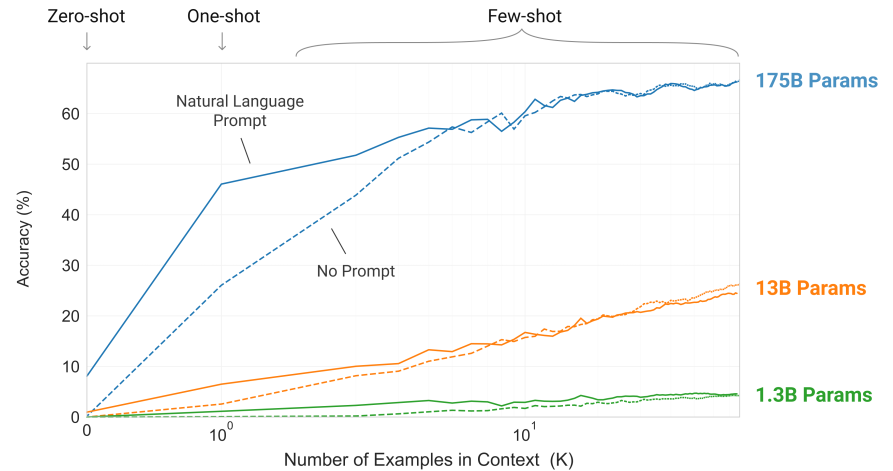
The steeper “in-context learning curves” for large models demonstrate improved ability to learn a task from contextual information
Task: removing random symbols from the word (paper Section 3.9.2)
- A random punctuation or space character is inserted between each letter of a word
- The model must output the original word
- Example: s.u!c/c!e.s s i/o/n = succession
- With and without a natural language task description
Language Modeling
- PTB:
- Previous SOTA perplexity: 35.8
- GPT-3 perplexity: 20.5
- LAMBADA (long range dependencies in text)
- Previous SOTA accuracy: 68.0
- GPT-3 zero-shot accuracy: 76.2
- GPT-3 few-shot accuracy: 86.4
- Below SOTA datasets
- HellaSwag (picking the best ending to a story or set of instructions)
- StoryCloze (electing the correct ending sentence for five-sentence long stories)
Closed Book Question Answering
- TriviaQA: GPT-3 few-shots outperforms Fine-tuned SOTA
- WebQuestions: GPT-3 is competitive to SOTA
- Natural Questions: GPT-3 underperforms SOTA
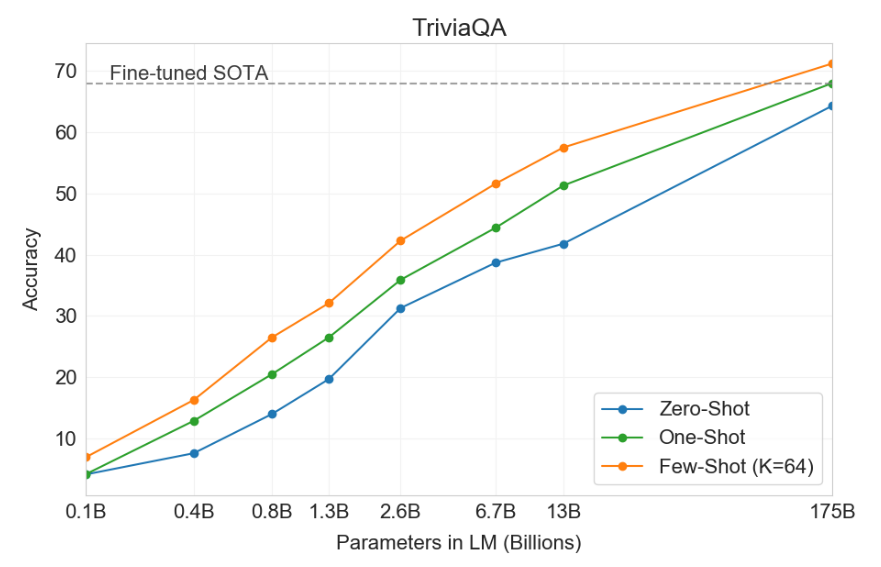
GPT3’s performance grows smoothly with model size on TriviaQA
Translation
- Measured by BLEU
- Translation into English: GPT-3 outperforms/competitive to Fine-tuned supervised SOTA
- Translation from English: GPT-3 significantly lag behind Fine-tuned supervised SOTA
- Details: paper Section 3.3
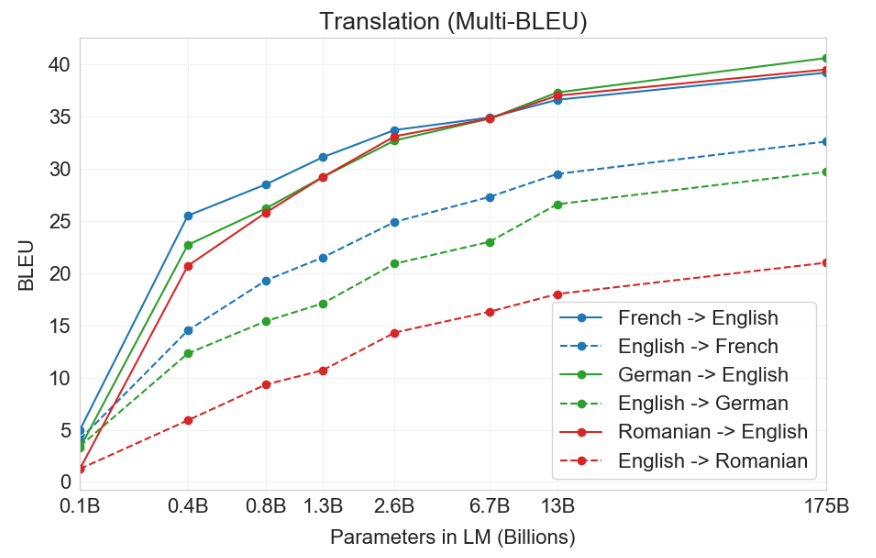
GPT3’s performance grows smoothly with model size on NMT tasks
Winograd-Style Tasks
- Tasks in NLP that involves determining which word a pronoun refers to
- The pronoun is grammatically ambiguous but semantically unambiguous to a human
- Winograd: GPT-3 few-shot is competitive to Fine-tuned SOTA
- Winograd XL: GPT-3 few-shot lag behind to Fine-tuned SOTA
Common Sense Reasoning
- Tasks in physical or scientific reasoning
- Distinct from sentence completion, reading comprehension, or broad knowledge question answering
- PhysicalQA
- Common sense questions about how the physical world works and is intended as a probe of grounded understanding of the world
- GPT-3 outperforms Fine-tuned SOTA
- ARC
- Multiple-choice questions collected from 3rd to 9th grade science exams
- GPT-3 lag behind Fine-tuned SOTA
Reading Comprehension
- GPT-3 Generally underperforms Fine-tuned SOTA
- GPT-3 performs best (within 3 points of the human baseline) on CoQA, a free-form conversational dataset
- GPT-3 performs worst on QuAC, a dataset which requires modeling structured dialog acts
Natural Language Inference
- Task for testing the ability to understand the relationship between two sentences
- GPT-3 largely underperforms Supervised SOTA on RTE and ANLI
Synthetic and Qualitative Tasks
- 3-digit additions: large model suddenly generalize
- Word Scrambling: larger model lead to smooth performance increase
- Selected SAT college entrance exam: large model improve performance (>60% accuracy)
- News Article Generation: human unable to identify model generated articles (statistically cannot reject null hypothesis)
- Learning and Using Novel Words: appears to be a correct or at least plausible use of the word
- Correcting English Grammar
- Few-shot prompt: “Poor English Input: [sentence]\n Good English Output: [sentence]”