Self-Supervised Learning
This post is mainly based on
- Prof. Richard Zemel’s topic course
- Lilian Weng’s blog on SSL
- Yann LeCun’s blog on SSL
Representation Learning had emerged as an important topic in deep learning research. If you are not familiar with this term, representation learning is just another way of describing feature learning or feature extraction. Self-Supervised Learning (SSL) is method of representation learning: given a set of unlabeled data, we design some so called pretext tasks to training a neural network. The catch is: we do not really care about our model’s accuracy on these pretext tasks; the goal is utilizing the supervising provided by the pretext tasks to learn a good representation.
Yann LeCun mentioned that one of the motivation of SSL is acquiring general intelligence. Supervised learning requires a large amount data and labeling them could be expensive. We observe that human are very sample efficient in learning new skills. One explanation is that humans achieve this by background knowledge of how the world works. In language of machine learning, we have a “world model”: a model that constantly observes the world, generates labels and learns a good embedding.
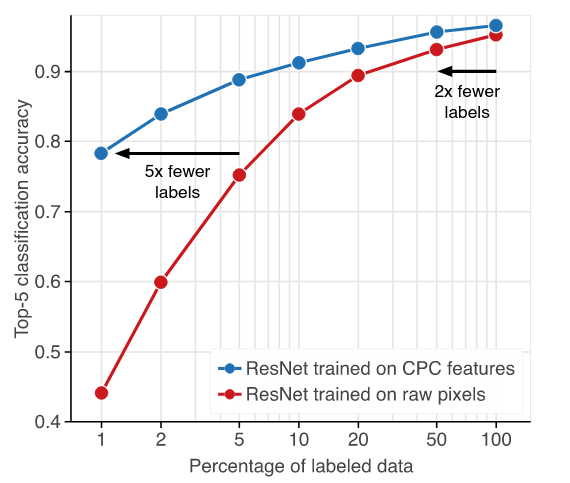
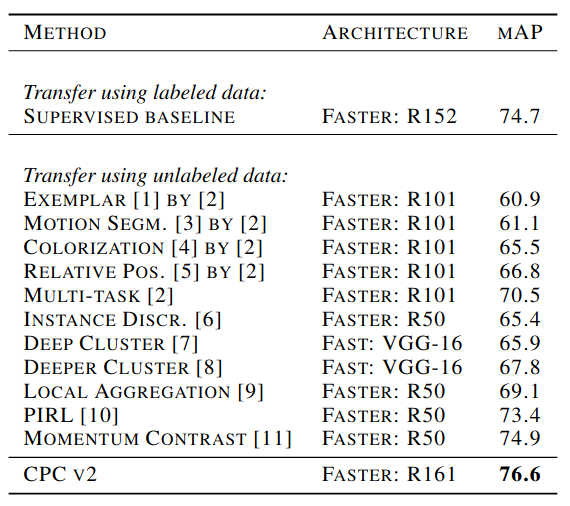
Recently, SSL has achieved remarkable results in deep learning. For example networks trained with CPC v2 embeddings is highly sample efficient: reaching close to 80% testing accuracy with 1% of ImageNet data. It also beat features from supervised baseline on PASCAL VOC object detection task.
Taxonomy
- Supervise Learning: human label all training data
- Weakly Supervised Learning: model is trained on coarse, noisy or off task labels (e.g., images with Instagram hashtags)
- Semi-Supervised Learning: human label $p$% of data (how to deal with unlabeled data depends on your assumption, a common approach is iteration until convergence)
- Self-Supervised Learning: Design some tasks that could automatically synthesized labels
- Unsupervised Learning: Learning purely based on distribution of data (e.g., K-means, PCA, factor analysis, generative models)
The main difference between Self-Supervised Learning and Unsupervised Learning is
- Self-Supervised Learning: requires additional information supported by human understanding of the problem to synthesized label; dataset is $\{(X,y)\}$
- Unsupervised: only $\{(X)\}$ is available
Origin of Self-Supervised Learning
Self-Supervised Learning is inspired by works in many fields that is related to Representation Learning, including data compression, generative model, paired data and unsupervised learning.
Autoencoder (AE)
An AE is a generative model. The encoder map the input data into an embedding space $Z$ and goal of AE is data compression or dimensionality reduction. To efficiently encoding data, the encoder must learn a good representation of the data distribution. If the goal is to use the embedding of AE in other tasks, then AE can be viewed as representation learning.
Restricted Boltzmann Machine (RBM)
- Restricted Boltzmann Machine
- Training Products of Experts by Minimizing Contrastive Divergence
- On Contrastive Divergence Learning
An RBM is a generative model. The most simple form of RBM deals with binary input: $[0,1]^n$. It consists of a visible layer $V$, a hidden layer $H$ and a weight matrix $W$. The probability of a specific configuration in one layer only depends on the configuration of another layer: given $V$, $P(H, V) = P(H|V)$. The weight matrix $W$ determines the conditional distribution $P(H|V)$ or $P(V|H)$. Optimizing an RBM involves adjusting $W$ to minimize the energy function and the optimization method is called Contrastive Divergence. If you never worked on RBM before, this introduction video is a good starting point.
In early days of deep learning, neural networks cannot be efficiently optimized by gradient descent. Instead, they are trained by stacking RBM on top of each other (deep belief network). The hidden layer models the distribution of data and can be viewed as representation learning.
Siamese Network
Siamese network is originally designed for signature verification: checking whether two signatures are signed by the same individual. It maps a pair of inputs to a pair of embeddings. The output layer measures the similarity between two embeddings.
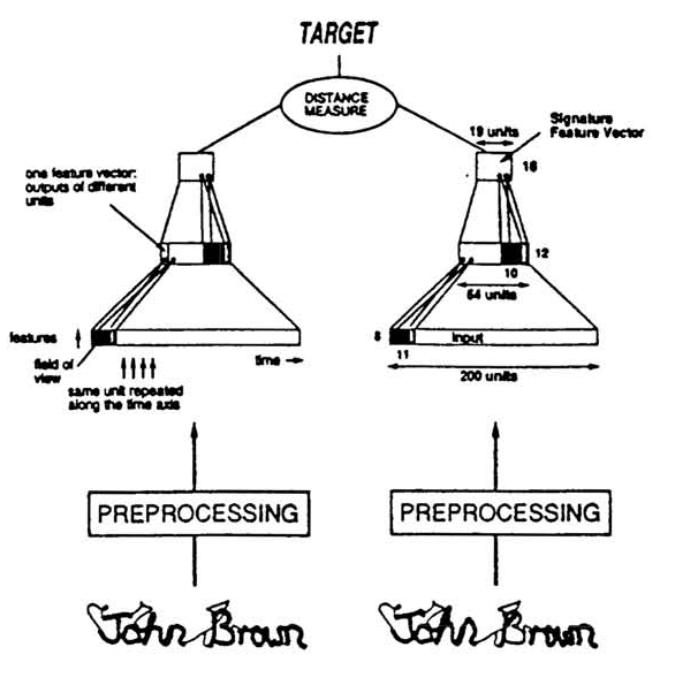
The optimization goal is to pull similar images close and push different images apart in the embedding space. We will discuss more about this idea in the [Contrastive Learning Post].
Word Embedding
Word Embeddings map tokens to embedding space. Token that are similar in semantics or syntax are “close” in the embedding space. Word embeddings are used in many NLP downstream tasks and can be viewed as representation learning. Word2Vec can also be viewed as Contrastive Learning.
Self-Supervised Learning Methods
- Generative Model
- Powerful, but computationally expensive
- Perhaps unnecessary for representation learning
- [Discriminative Model]
Generative Model
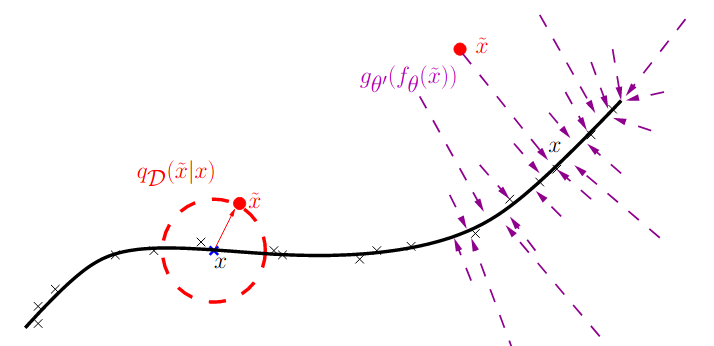
Denoising Autoencoders
In representation learning, there is the question of what constitute to a good representation? One possible answer is: a good representation is robust under Covariate Shift. Assume we are dealing with the distribution shift caused by gaussian noise. A way of imposing the learned representation invariant to gaussian noise is to train the model under such noise. This is the idea behind Denoising Autoencoder: the learned representation should map points in a ball/neighborhood of $x$ back to itself.
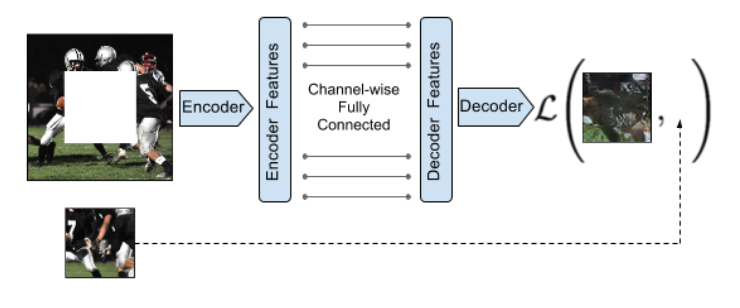
Context Encoders
Context encoder rethink about the question: What is the relevant part to reconstruct? In Denoising AE, the task is to reconstruct every pixels. However, pixels in the corner are not really useful and human generally have inductive bias toward the center of an image. Context Encoder mask the center of the image to force the model to learn a better representation.
Colorization
- Colorful Image Colorization, ECCV 2016
- Input: 1 channel (Grayscale)
- Predict: 2 channels (ab color space)
- Learn about: distribution of color over the object
The assumption for colorization is color distribution may be more important for some tasks.

Pretext Tasks
As previously mentioned, the pretext task provide supervision in SSL. However, a lot of questions remains: What pretext tasks is useful? Is benchmark dataset (e.g. ImageNet) good for SSL? How to evaluate SSL? We may discuss these questions in a [future post].
Empirical evidence
- We have good understandings of CV tasks:
- What should the image be invariant to: e.g., noise, rotation, crop, etc.
- What information we want the system to encode: e.g., color, relative location, etc.
- We have some understandings of NLP tasks:
- Context of the word is important (Masked Language Model)
- We do not have as many reliable augmentations as in CV
- We do not have good knowledge in many other domains
- Hard to design good pretext tasks or augmentations
Pretext Tasks in CV
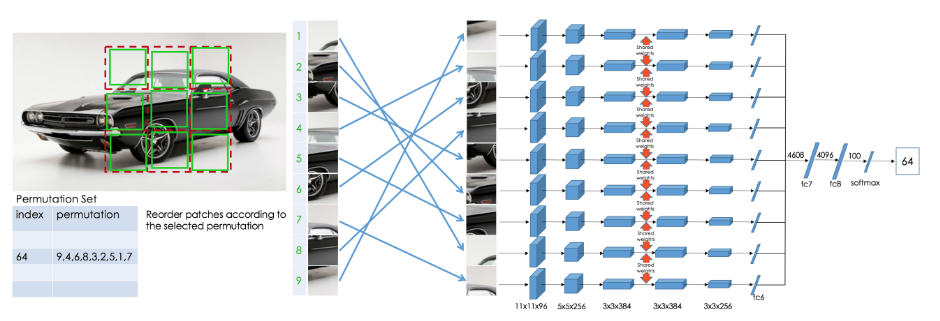
Permutation
- Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles, ECCV 2016
- Input: 9 patches
- Predict: correct permutations (1 out of 64)
- Learn about: shape, location and association
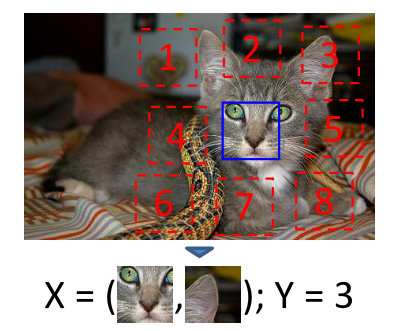
Context
- Unsupervised Visual Representations Learning by Context Prediction, ICCV 2015
- Input: the center patch and target patch (1 of 8 patches around the center)
- Predict: target patch location (1 out of 8)
- Learn about: shape, location and association
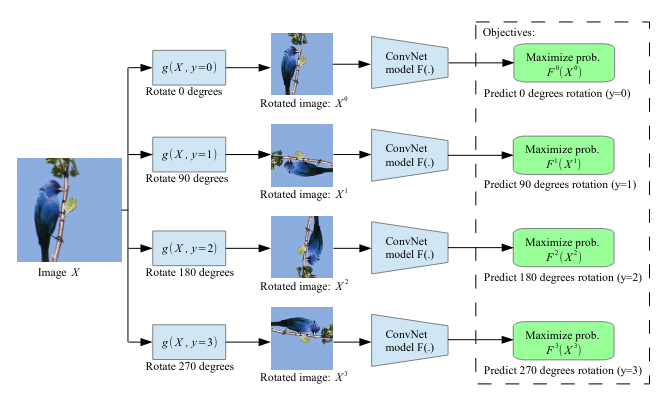
Rotation
- Unsupervised Representations Learning by Predicting Image Rotations, 2018
- Input: rotated image
- Predict: rotation (1 out of 4)
- Learn about: orientations
Pretext Tasks in NLP
Masked Language Model
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Input: sentence with masked token
- Predict: masked token
- Learn about: context
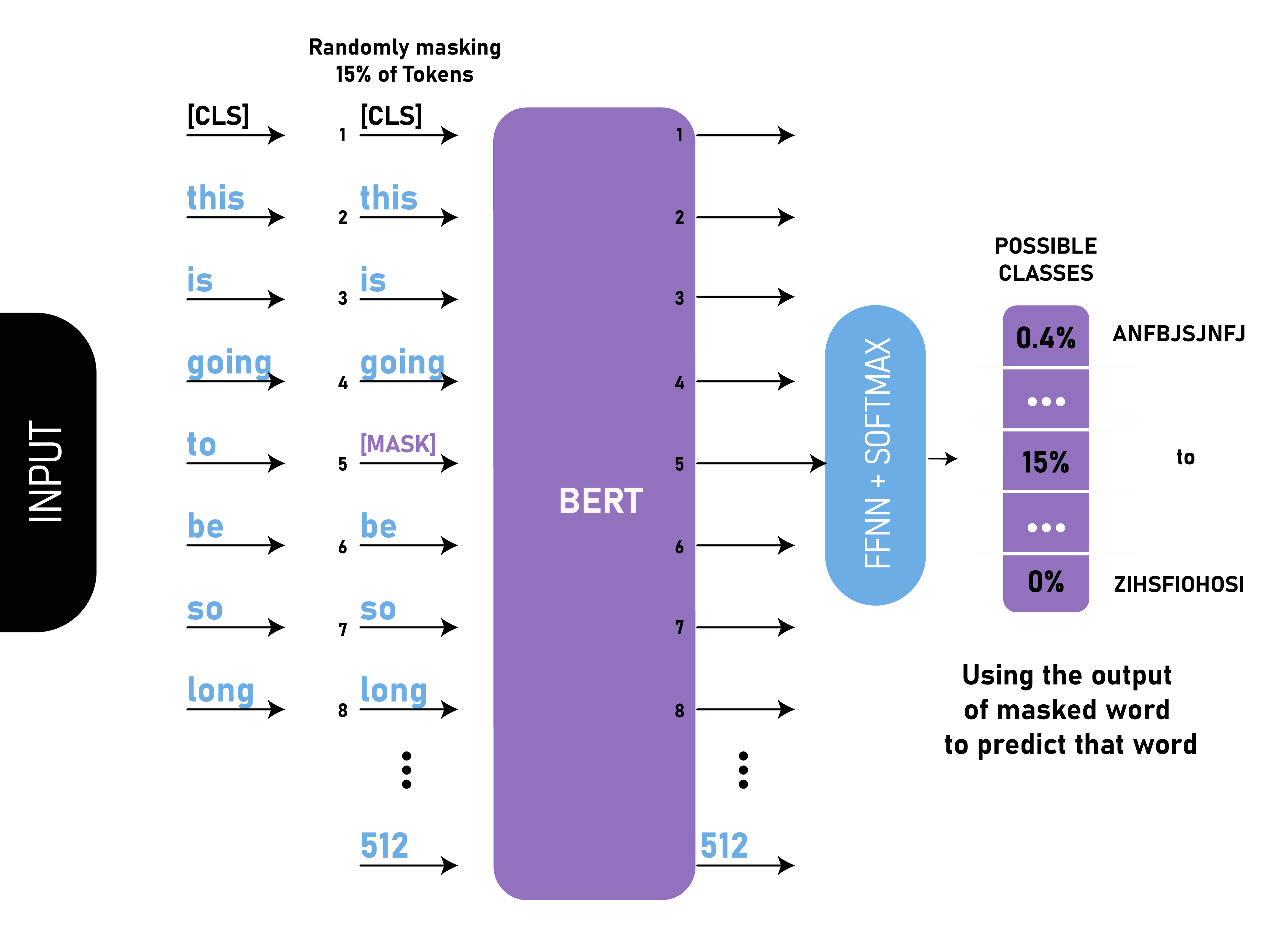
Image from Geeksforgeeks