Dropout
This post is mainly based on
- Improving neural networks by preventing co-adaptation of feature detectors
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting, JMLR 2014
Dropout was discussed as a model regularization technique by Srivastava and Hinton in early 2010s. They attribute the success of dropout to reducing neuron’s co-adaptation, promoting sparsity and performing model averaging. I think the last one make more sense. I am curious about if dropout have some effects on optimization landscape but I am not able to find any good discussion on this.
It appear that dropout was a bit outdated after introduction of batch norm, but many modern architecture still use dropout:
- In CV, recent deep architecture mainly uses Conv layers + batch norm, which need less regularization as discussed here.
- Some claims that dropout doesn’t work well between recurrent units in RNN, while others disagree, more discussions here.
- Transformer uses dropout in its residual connection as described in this implementation
Automatic Differentiation
Automatic Differentiation (AD) with dropout is easy to implement. If a neuron is inactivate, the computation graph before that neuron have zero effects on loss function. AD can be performed on the reduced computation graph which only include active neurons.
Co-adaptation
The authors mentioned that the neural co-adaptation concept is similar to co-adaptation in biology. The direct effect of dropout is making input from other hidden units unreliable. They believe dropout drive the model _towards creating useful features on its own without relying on other hidden units to correct its mistakes._The model has better generalization performance when each neuron is robust and can work with a small subset of reliable input.
Below is autoencoder (AE) trained with dropout and w/o dropout. AE with dropout create more meaningful features.

Features learned on MNIST with one hidden layer autoencoders having 256 rectified linear units
Effect on Sparsity
Below is autoencoder (AE) trained with dropout and w/o dropout. AE with dropout create sparse representation from input.
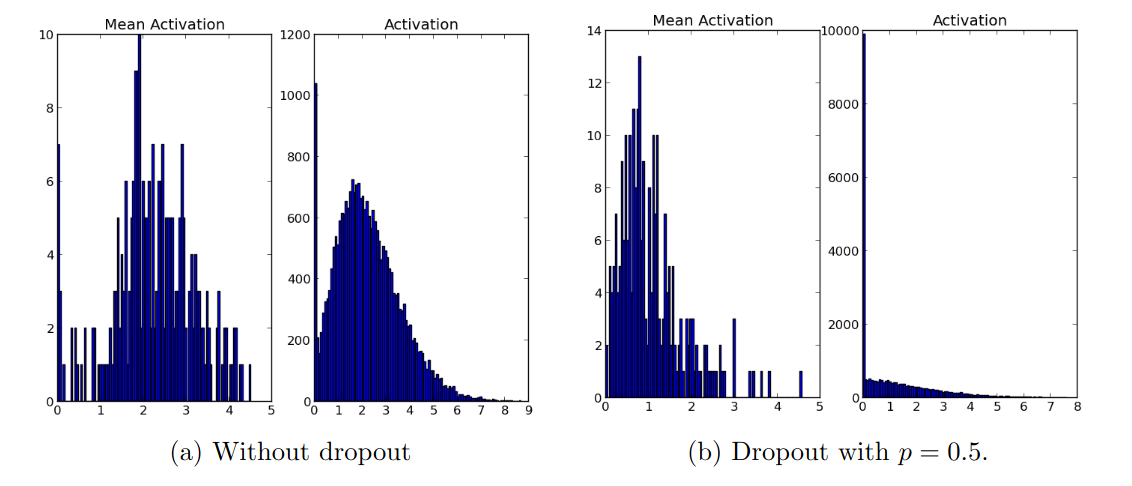
Model trained with MNIST with one hidden layer autoencoders, activations histogram are created by passing mini-batch from testing set.
Model averaging
The authors mentioned that dropout can be viewed as model bagging (I think neural network with dropout is also somewhat similar to Feature Bagging). From the view of bias-variance tradeoff, bagging improves model generalization by reducing the model variance:
\[\hat{f} = \frac{1}{B} \sum_{b=1}^{B} f_b(x)\]In a standard model bagging, we need to train networks with different architecture and average over their output. This is computational expensive.
By randomly deleting neurons, dropout effectively created different networks in training and minimized the weighted loss. The weight is the probability of one specific network architecture is sampled with dropout probability. In testing, the “correct” way to make unbiased prediction is to sample $n$ networks again with dropout probability, and then compute their average. In practice, we set all neurons as activate. The authors mentioned that this is equivalent to computing equally-weighted averaging of exponentially many models with shared weights.
They also discussed the connection between dropout and Bayesian network in both paper.
Note that there is another regularization technique called stochastic depth where an entire block/layer is dropped. Stochastic depth is different from neuron level dropout and it does not work for feedforward network without skip connection. It works in residual network for some different reasons, interested reader please refer to this post