LLM Benchmark 2022-2023
This post is mainly based on
- BIG-bench: Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, 2022
- AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models, 2023
- MT-Bench: Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, NIPS 2023
BIG-bench (2022)
- Beyond the Imitation Game benchmark (BIG-bench)
- Task
- Tasks that are believed to be beyond the capabilities of current language model
- Large-scale, extremely difficult and diverse tasks
- Dataset
- 204 tasks, contributed by 450 authors across 132 institutions
- Diverse tasks: linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development
- Human expert and human average raters performed all tasks to provide a baseline
- Findings
- Analyze dense and sparse transformer models, from Google and OpenAI, across six orders of magnitude of model scale
- Performance is similar across model classes
- Tasks where performance linearly scales with size are mainly knowledge based tasks that involves memorization
- Tasks where performance exhibit “breakthrough” behavior at a critical scale often involve multiple steps / skills
- Social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting
BIG-bench API
- JSON Task (80% of all)
- Contains a list of examples made up of inputs and targets
- Evaluation
- Comparing generated model outputs to targets using standard metrics (e.g., ROUGE)
- Compute on model-assigned probabilities (e.g., in answering multiple-choice questions)
- Programmatic Task (20% of all)
- Written in Python and have the ability to interact directly with the model over multiple query rounds
- The code that defines the task can query the model repeatedly (e.g., multiple rounds dialog)
- Evaluation: custom metrics
- Benchmark Average Score
- Specify a unique preferred metric for each task
- Specify high and low scores for each task, the score is then normalized in this range
BIG-bench Lite
JSON tasks only, for less computationally intensive evaluation.
24 tasks included in BIG-bench Lite:
auto_debugging
bbq_lite_json
code_line_description
conceptual_combinations
conlang_translation
emoji_movie
formal_fallacies_...
hindu_knowledge
known_unknowns
language_identification
linguistics_puzzles
logic_grid_puzzle
logical_deduction
misconceptions_russian
novel_concepts
operators
parsinlu_reading_comprehension
play_dialog_same_or_different
repeat_copy_logic
strange_stories
strategyqa
symbol_interpretation
vitaminc_fact_verification
winowhy
“Breakthrough” Behavior
- Tasks that see strong breakthrough behavior include those that are
- Composite in nature
- Require a model to apply several distinct skills or perform multiple steps to reach the correct answer
- Examples
modified_arithmetic: applying a mathematical operator, defined in-context to certain inputsrepeat_copy_logicfigure_of_speech_detectioncodenames
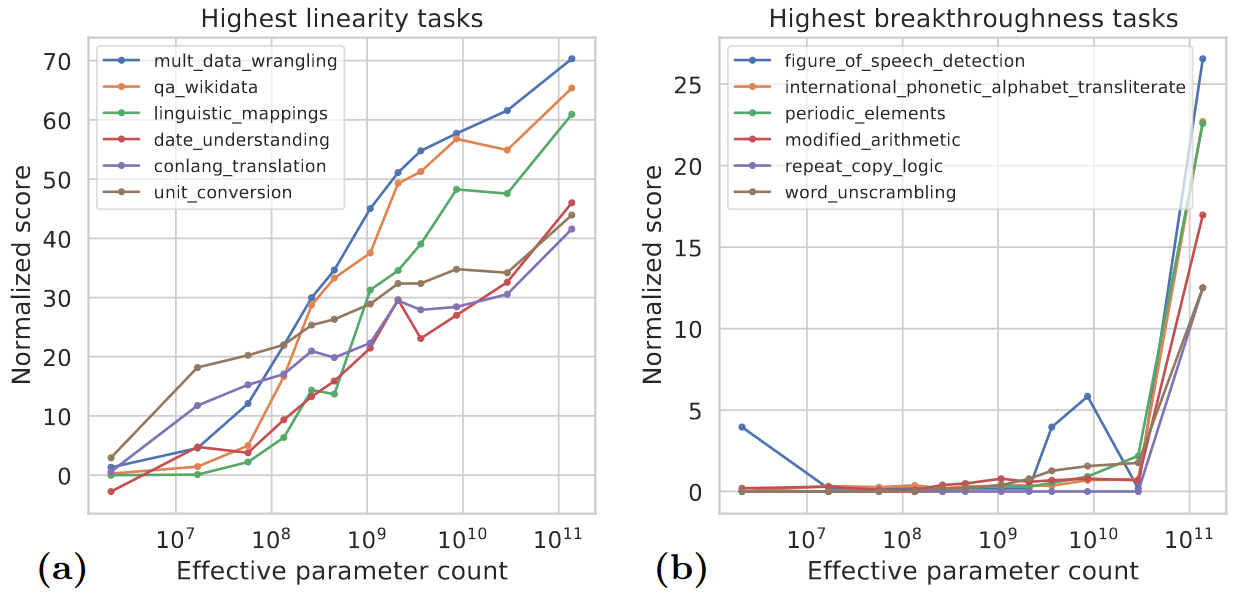
Left: Tasks that achieve the highest linearity scores see model performance improve predictably with scale.
Right: Tasks with high breakthroughness do not see model performance improve until the model reaches a critical scale. Around 5% of BIG-bench tasks see models achieve sudden score breakthroughs with increasing scale.
Social Bias
- Social Bias: given a fixed context involving people, with potential completions, does a model show a systematic preference for members of one category over another or for associating particular attributes with particular categories?
- Bias typically increases with scale in settings with broad or ambiguous contexts
- Bias can decrease with scale in settings with narrow, unambiguous contexts
- Bias can potentially be steered through appropriately chosen prompting
AGIEval (2023)
- Task
- Human-centric standardized exams (college entrance exams, law school admission tests, math competition)
- Dataset
- 8062 questions from 10 exams
- Human-level reasoning and real-world relevance
- Evaluation Metrics: multiple-choice and fill-in-the-blank (exact match & F1)
- Findings
- GPT-4 surpasses average human performance on SAT, LSAT, and math competitions, attaining a 95% accuracy rate on the SAT Math test
- LLM weaknesses
AGIEval vs MMLU
- AGIEval: data sourced from high-standard and official human-centric exams
- AGIEval is bilingual
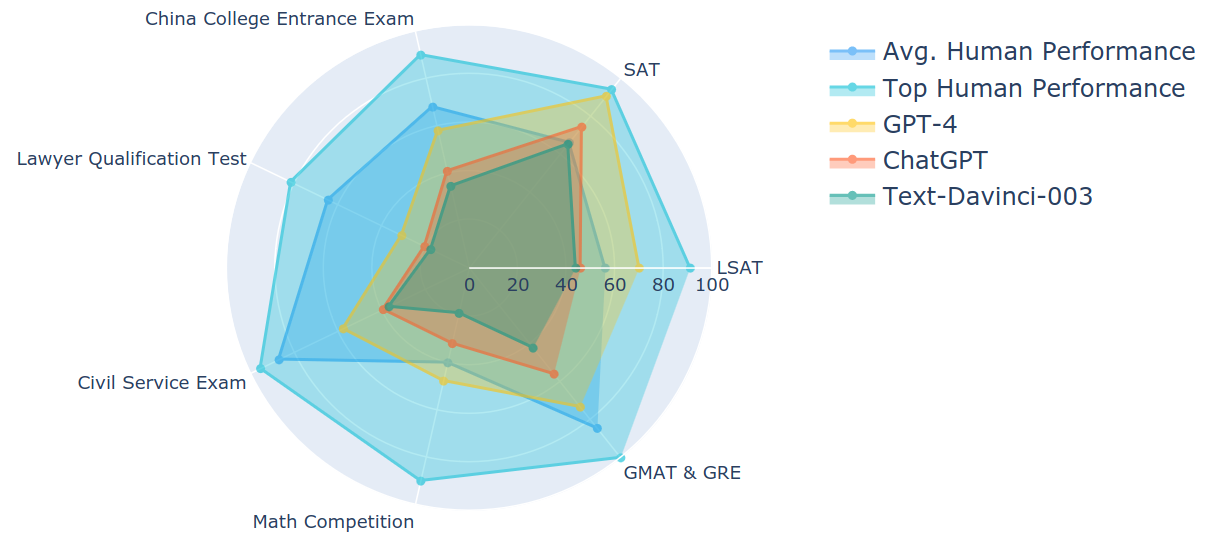
Compared to the averaged human performance, GPT-4 achieves better scores on the SAT, LSAT, and math competition. Model: zero-shot learning with a Chain-of-Thought (CoT) prompting setting. Human performance (top) refers to the performance of the top 1% of test takers, except for the lawyer qualification test which uses the top 10%.
Overall Trend of LLM Capabilities
Capabilities
- Understanding: accurately interpret the meaning of questions
- Knowledge: proficiency in identifying correct knowledge
- Reasoning: accurately execute multi-step reasoning processe
- Calculation: basic calculation, combinatorial abstraction and variable substitutions
Strength
- Good Understanding
- Proficiency in Simple Reasoning and Deduction
- Grasping General Reasoning Process
Weaknesses
- Understanding
- Difficulty with Variable Substitution
- Difficulty with Complex Math Concepts and Symbols
- Confusion with Similar Concepts
- Difficulty with Handling Long Contexts
- Knowledge
- Occasionally lack of commonsense or domain-specific knowledge
- Difficulty with Identifying Correct Formulas
- Reasoning
- Difficulty with Strict Logical Deduction
- Ignoring premise conditions
- Misconstruing sufficient and necessary conditions
- Making errors in logical chaining
- Difficulty with Counterfactual Reasoning
- Difficulty with generating alternative scenarios
- Difficulty with evaluating hypothetical outcomes
- Difficulty with exploring potential consequences based on varying assumptions
- Struggles in Multi-hop Complex Reasoning
- Establishing Incorrect Conclusions and Contradictory Reasoning
- Set an incorrect conclusion first and then generate contradictory reasoning based on that faulty foundation
- Concealed Substitution of Concepts
- Vulnerability to Contextual Disturbance
- When the context is modified, the models may produce different deductions for the same condition
- Difficulty with Strict Logical Deduction
- Calculation
- Prone to Making Calculation Errors
- Difficulty with Complex Variable Substitutions
MT-Bench (2023)
- Task: systematically evaluate LLM alignment
- Idea: using strong LLMs as judges to evaluate answers on open-ended questions
- Goal: develop a more scalable and automated LLM evaluation approach
- Dataset
- MT-bench: 80 high-quality multi-turn questions, 3K expert votes
- Chatbot Arena: crowdsourcing open-end interaction with two anonymous models, 30K votes
- Findings
- GPT-4 judge match human evaluations at an agreement rate exceeding 80%
For more details, please refer to this post