LLM As A Judge
This post is mainly based on
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, NIPS 2023
- MT-Bench Browser
- Chatbot Arena Conversations Dataset
Traditional NLP Evaluation Methods
- BLEU
- Machine translation benchmark
- N-grams precision: measure % of n-grams also occured in the reference translations
- Brevity Penalty: penalize for translation length < reference length
- For more details, check this post
- Rouge: Recall-Oriented Understudy for Gisting Evaluation
- ROUGE = $\sum$ Recall of n-grams
- ROUGE-N: overlap of n-grams
- ROUGE-L: longest common subsequence
- ROUGE-S: overlap of skip-bigram
- Multiple-choice questions
- Standardized and consistent way to evaluate the language understanding capabilities
- Sample benchmarks: MMLU
Challenges of traditional LLM benchmarks: cannot effectively tell the difference between these aligned models and the base models.
LLM-as-a-Judge
- Idea: using strong LLMs as judges to evaluate answers on open-ended questions
- Goal: develop a more scalable and automated LLM evaluation approach
- Agreement rate
- GPT-4 judge match human evaluations at an agreement rate exceeding 80%
- Same level as human-human agreement rate
- Human preference datasets
- MT-bench: 80 high-quality multi-turn questions, 3K expert votes
- Chatbot Arena: crowdsourcing open-end interaction with two anonymous models, 30K votes

Multi-turn dialogues between a user and two AI assistants—LLaMA-13B (Assistant A) and Vicuna-13B (Assistant B)—initiated by a question from the MMLU benchmark and a follow-up instruction. GPT-4 is then presented with the context to determine which assistant answers better.
LLM-as-a-Judge
- Types
- Pairwise comparison: determine which one is better or declare a tie (See paper’s Figure-5)
- Single answer grading: directly assign a score (1 to 10) to a single answer (See paper’s Figure-6)
- Reference-guided grading: grading with reference solutions (See paper’s Figure-8)
- Advantages
- Scalability
- Explainability
- Limitations
- Position, verbosity, and self-enhancement biases
- Limited reasoning ability

Sample multi-turn questions in MT-bench
Limitations: Position Bias
- Approach: LLM is asked to evaluate two responses in different posistions
- “Rename” renames the assistants in our default prompt to see whether the bias is on positions or names
- Findings
- All LLMs exhibit strong position bias, most favor the first position
- Claude-v1 favors “Assistant A”
- GPT-4 has highest consistent: 60%
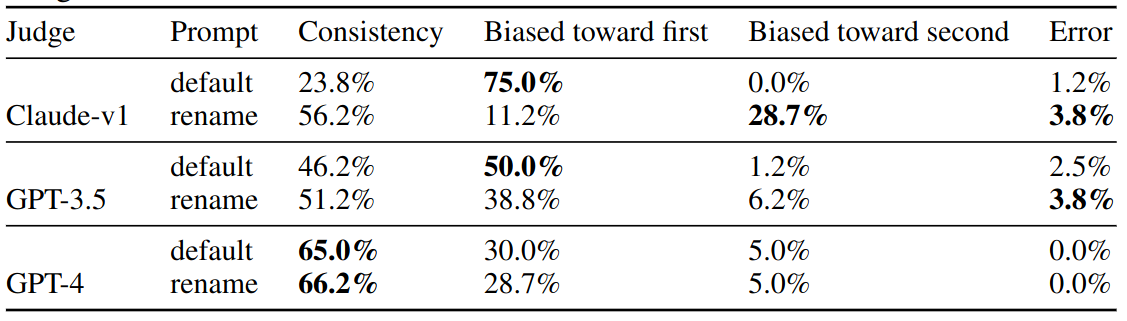
Position bias of different LLM judges. Consistency is the percentage of cases where a judge gives consistent results when swapping the order of two assistants. “Biased toward first” is the percentage of cases when a judge favors the first answer. “Error” indicates wrong output formats.
Limitations: Verbosity Bias
- Approach: “repetitive list” attack
- Select answers that contain a numbered list
- Use GPT-4 to rephrase the list without adding any new information
- 5 items => 5 items + 5 items rephrased from the original 5 items
- Findings
- All LLMs may be prone to verbosity bias
- GPT-4 defends significantly better than others

Failure rate under “repetitive list” attack for different LLM judges on 23 answers.
Limitations: Self-Enhancement Bias
- LLM judges may favor the answers generated by themselves
- Approach: win rate under different LLM judges and humans
- Findings
- GPT-4 favors itself with a 10% higher win rate
- Claude-v1 favors itself with a 25% higher win rate
Limitations: Lack of Capability in Grading Math and Reasoning Questions
- LLMs are known to have limited math and reasoning capability
- TBD: Training verifiers to solve math word problems
Addressing Limitations
- Swapping positions
- Few-shot judge
- CoT and reference-guided judge
Multi-turn Judge
- When comparing two assistants, need to handle 2 questions and 4 responses
- 2 designs
- Design 1: Breaking the two turns into two prompts
- Design 2: Displaying complete conversations in a single prompt
- Findings
- Design 1 cause LLM judge struggling to locate the assistant’s previous response precisely
- Necessary to display a complete conversation to enable the LLM judge to better grasp the context
Agreement Evaluation
- Metrics
- Agreement: probability of randomly selected LLM judge and Human judge agreeing on a randomly selected question
- Average win rate: average of win rates of one LLM’s answer against all other LLMs’ answer
- Metrics can be computed with or without including tie votes
High agreement on MT-bench
- GPT-4 show very high agreements with human experts in
- Pairwise comparison
- Single answer grading
- The GPT-human agreement-S2 (w/o tie) reaches 85%, higher than human-human agreement (81%)
- Conflict resolution
- When a human’s choice deviated from GPT-4, we presented GPT-4’s judgments to humans and ask if they are reasonable
- Despite different views, humans deemed GPT-4’s judgments reasonable in 75% of cases and are even willing to change their choices in 34% of cases
- Conclusion
- GPT-4 with single-answer grading matches both pairwise GPT-4 and human preferences very well
- This means GPT-4 has a relatively stable internal rubric
- GPT-4 may sometimes perform slightly worse than pairwise comparison and give more tie votes
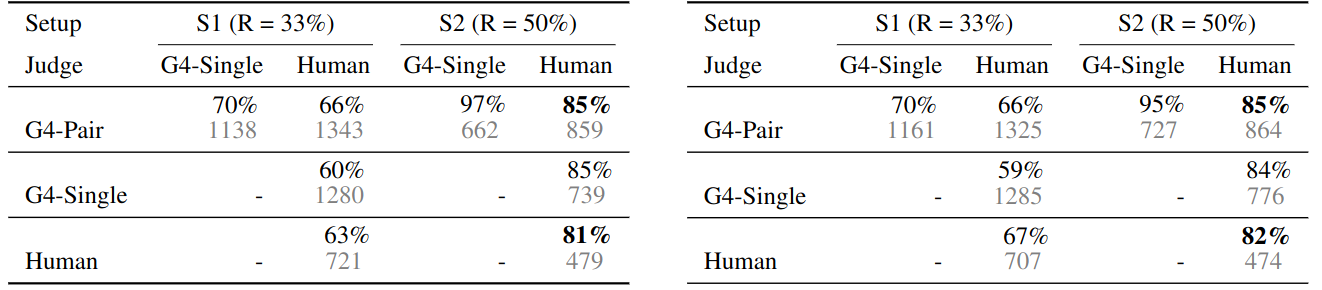
Agreement between two types of judges on MT-bench.
- Row
- G4-Pair: GPT-4 with pairwise comparison
- G4-Single: GPT-4 with single-answer grading
- The single-answer grading can be converted into pairwise comparison for calculating the agreement
- Column
- S1: includes non-tie, tie, and inconsistent (due to position bias) votes and counts inconsistent as tie
- S2: only includes non-tie votes
- Cell
- The agreement between two random judges under each setup is denoted as “R=%”
- Top value: agreement
- Bottom gray value: #votes
High agreement on Chatbot Arena
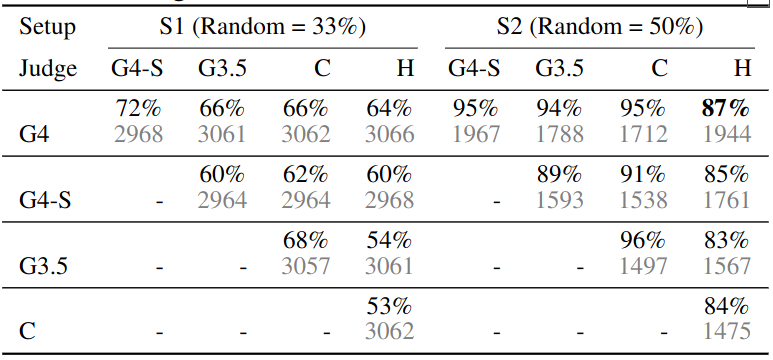
Agreement between two types of judges on Chatbot Arena.
- G4-S: GPT-4 with single-answer grading
- G4: GPT-4 with pairwise comparison
- G3.5: GPT-3.5 with pairwise comparison
- C: Claude with pairwise comparison
- H: human