Parameter Efficient Fine-Tuning
This post is mainly based on
- Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, ACL 2021 outstanding paper
- LoRA: Low-Rank Adaptation of Large Language Models, ICLR 2022
The goal of Parameter-Efficient Fine-Tuning (PEFT) is to avoid full fine-tuning on all model parameters, which is prohibitively expensive for LLM with billions of parameters. Backgrounds: Measuring Neural Network’s Intrinsic Dimensionality.
Difference between 2 paper
- First paper
- Empirically show LM has low Intrinsic Dimension (across all params)
- Parameters are grouped as a whole, without matrix structure, then project them to low dimension
- Projection matrix is computed from Fastfood transform
- LoRA
- Assume the each $\Delta$ weight matrix has low rank, and estimate it by low rank decomposition
- Parameters are grouped by considering their matrix structure, then project them to low dimension
- Low rank decomposition is learned
Intrinsic Dimensionality of LLM
- It is unclear why LLM with millions of parameters can be fine-tuned (FT) on hundreds or thousands of labeled examples
- Based on the Intrinsic Dimension Method, this paper empirically show
- LLM has a low dimension reparameterization (FT on full params vs reduced params are equally effective)
- By optimizing 200 parameters, RoBERTa can achieve 90% performance of the full parameter FT on MRPC
- Pre-training implicitly minimizes intrinsic dimension, which could reveal insights on how to compress the average NLP task
Background
- Pre-trained models such as BERT are redundant in their capacity, allowing for significant sparsification without much performance degradation
- FT top layers of pre-trained models is not effective, FT with Adapter Module is parameter efficient
- Standard FT seem to affect generalization of pre-trained representations
Direct Intrinsic Dimension (DID)
\[\theta^{(D)} = \theta^{(D)}_0 + P\theta^{(d)}\]Selection of Projection Matrix
- The only computationally reasonable subspace optimization method is Fastfood transform
- Reason: projecting RoBERTa-Large model to a $d = 1000$ subspace with a dense matrix requires 1.42TB of memory
Structure Aware Intrinsic Dimension (SAID)
- Existing literature found that individual layers specialize separate task in transformer
- What Does BERT Look At? An Analysis of BERT’s Attention
- However, the original DID method ignores the layer-wise structure of transformer
- SAID inject structure to $\theta^{d}$ when computing $d_{90}$
where,
- $i$: layer index
- $m$: total number of layer
- $d-m$: dimension of projected parameters, s.t., subspace’s total degree of freedom = $d-m$ + $m$, where $m$ = number of parameters reserved for $\lambda_i$
Experiments
Intrinsic Dimension of LLM
- From GLUE benchmark, choose MRPC and QQP
- MRPC: small dataset, ~3700 samples
- QQP: large dataset, 363k samples
- For each dataset and model, we run 100 subspace trainings with $d \in [10, 10000]$ on log scale
- Classification model contains randomly initialized sentence classification head, fixed
- This ensure we have exactly $d$ parameters to optimize
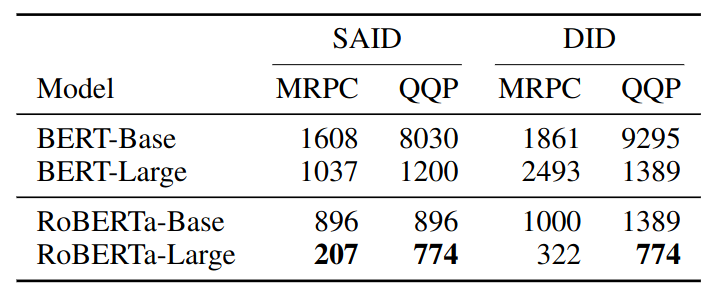
- Results
- Dimensionality for LLM on viable solutions is incredible low
- RoBERTa large # of parameters: 354 MM
- RoBERTa large MRPC subspace dimension: 207
- RoBERTa consistently outperforms BERT across various subspace dimensions $d$ while having more parameters
- Dimensionality for LLM on viable solutions is incredible low
Estimated \(d_{90}\) intrinsic dimension via DID and SAID
Intrinsic Dimension, Pre-Training, And Generalization Gap
- Interpretation of the intrinsic parameter vector
- The low dimensional vector encodes the target task with respect to the pre-trained representations
- Can interpret $d$ as the minimal description length of the target task via pre-trained representations
- Hypothesis
- Pre-training reduced the intrinsic dimensionality of the average NLP task
- Pre-training compress the minimal description length of target tasks
- The compression point of view
- For a classification network with pre-trained representation $f$, classification head $g$ are their respective weights $w_f, w_g$
- Fine tuning with SAID only requires storing $d$ parameters + $1$ seed to generate random matrices in Fastfood transform
Pre-Training & Intrinsic Dimension
- Steps
- Retrain a RoBERTa-Base from scratch, checkpoint model every pre-training 10000 steps
- Pre-training data does not contains downstream datasets
- At each checkpoint, using SAID to estimate $d_{90}$ across 6 datasets
- Results
- Intrinsic dimensionality of RoBERTa-Base monotonically decreases as we continue pre-training
- The correlation between tasks traditionally hard for RoBERTa and their large intrinsic dimension hints at a connection between generalization and intrinsic dimension
- Hypothesis
- Masked Language Models (MLM) learns generic and distributed enough representations of language to facilitate downstream learning of highly compressed task representations
- Pre-training learning representations that form a compression framework with respect to various NLP tasks
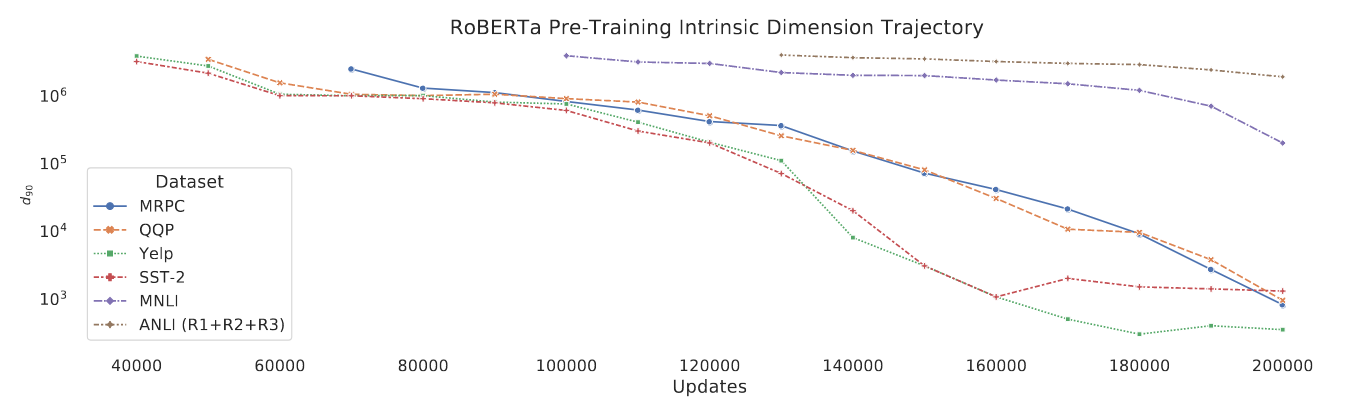
Estimated \(d_{90}\) intrinsic dimension of RoBERTa-Base when training from scratch. \(d_{90}\) are estimated on 6 datasets.
Parameter Count & Intrinsic Dimension
- Steps
- For each model, using SAID to estimate $d_{90}$ on MRPC dataset
- Results
- Strong general trend: as # parameters increases, intrinsic dimension of fine-tuning on MRPC decreases
- Experiments on other datasets showed the same trend (see paper Appendix)
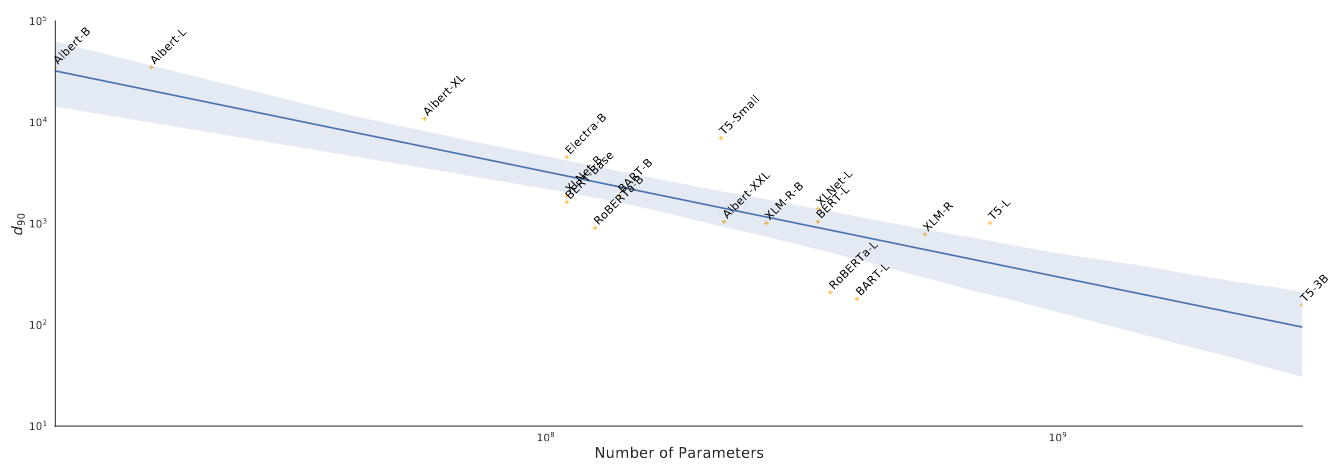
Scaling of intrinsic dimension w.r.t # params using the SAID method on the MRPC dataset.
Generalization Gap & Intrinsic Dimension
- A lower intrinsic dimension is strongly correlated with better evaluation performance
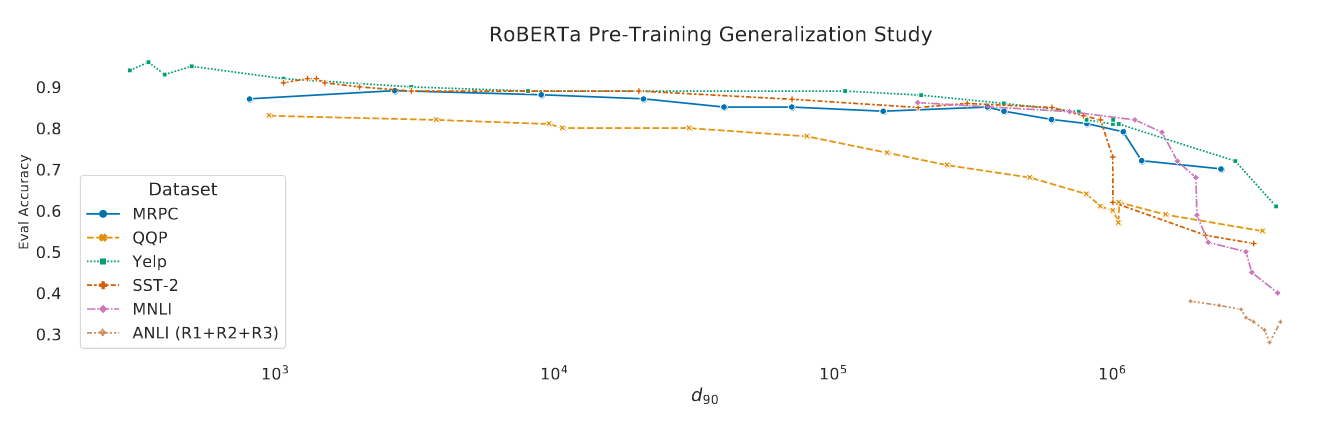
Evaluation accuracy vs intrinsic dimensionalities on 6 datasets.
TBD: Generalization Bounds
LoRA
- “Low-Rank Adaptation”
- How
- Freezes the pretrained model weights
- Injects trainable rank decomposition matrices into each Transformer layer
- Update only the parameters of rank decomposition matrices
- Greatly reduce trainable parameters + increase training throughput
- Performance: on-par or better than traditional finetuning on RoBERTa, DeBERTa, GPT-2, and GPT-3
Rank-deficiency in language model adaptation
- Hypothesize: change in weights during model adaptation also has a low “intrinsic rank”
- Using GPT-3 175B as an example, we show that a very low rank $\Delta$ weight is enough
- Even the full rank for GPT-3 is as high as 12,288
Background
- Over-parametrized models in fact reside on a low intrinsic dimension
- Approach 1: Adapter Modules
- 2 Adapter Layers are added on top of each transformer layer
- Advantage: only store and load a small number of task-specific parameters
- Disadvantage
- Increase inference latency due to sequential processing (20-30%, see Table 1)
- For model sharding, problem get worse, due to the synchronous GPU
AllReduceandBroadcast
- Approach 2: Prefix Tuning
- Disadvantage
- Difficult to optimize
- Often fail to match the fine-tuning baselines
- Reserving a part of the sequence length for adaptation reduces the input sequence length
- Disadvantage
- Approach 3: SAID
- Disadvantage
- Random Matrix in Fastfood transform still requires large storage
- Slow to train
- Disadvantage
LoRA
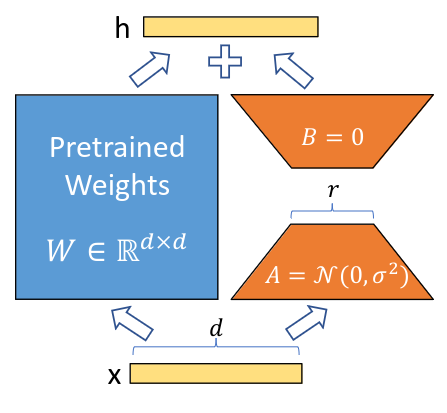
Reparametrization. Pre-trained Weights are fixed. Only train A and B are trained.
LoRA directly modifies the pre-trained parameters / weight matrices $W_0$ in each Transformer Layers by adding a $\Delta W$ on top of them:
\[W_0 + \Delta W = W_0 + BA\]where,
- $B \in \mathbb{R}^{d \times r}$
- $A \in \mathbb{R}^{r \times k}$
- $d$: input dimension
- $r$: matrix rank
- $k$: hidden dimension
- $r \ll min(d,k)$
During training and inference, matmul between $x$ and $W_0, \Delta W$ can be parallelized:
\[h = W_0x + \Delta Wx = W_0x + BAx\]LoRA advantages
- One pre-trained model + many small LoRA modules ($A,B$ in Figure 1) for different tasks
- Lower hardware barrier + higher throughput (No need to calculate the gradients or maintain the optimizer states for most parameters)
- On deployment: merge trainable matrices with frozen weights => no inference latency
- Orthogonal to previous approaches and can be combined with them (e.g., prefix-tuning)
LoRA is A Generalization of Full Fine-tuning
Why? As we increase the number of trainable parameters
- LoRA: converges to training the original model
- Adapter-based methods: converges to an MLP
- Prefix-based methods: converges to a model that cannot take long input sequences
Applying LoRA to Transformer
- Transformer: 4 weight matrices in the self-attention module $(W_q, W_k, W_v, W_o)$ and two in the MLP module
- This study
- Only adapting the attention weights for downstream tasks
- Freeze the MLP modules
Practical Benefits and Limitations
- Most significant benefit: reduction in memory and storage usage
- VRAM
- If $R \ll d_{model}$, can reduce that VRAM usage by up to 2/3
- On GPT-3 175B, can reduce the training VRAM from 1.2TB to 350GB
- If $r=4$ and only the query and value projection matrices being adapted, checkpoint size is reduced by roughly 10,000x (350GB -> 35MB)
- Training speed
- 25% speedup during training on GPT-3 175B compared to full fine-tuning
- Reason: do not need to calculate the gradient for the vast majority of the parameters
Experiments
- LoRA on GPT-3 175B
- Competitive to full fine-tuning
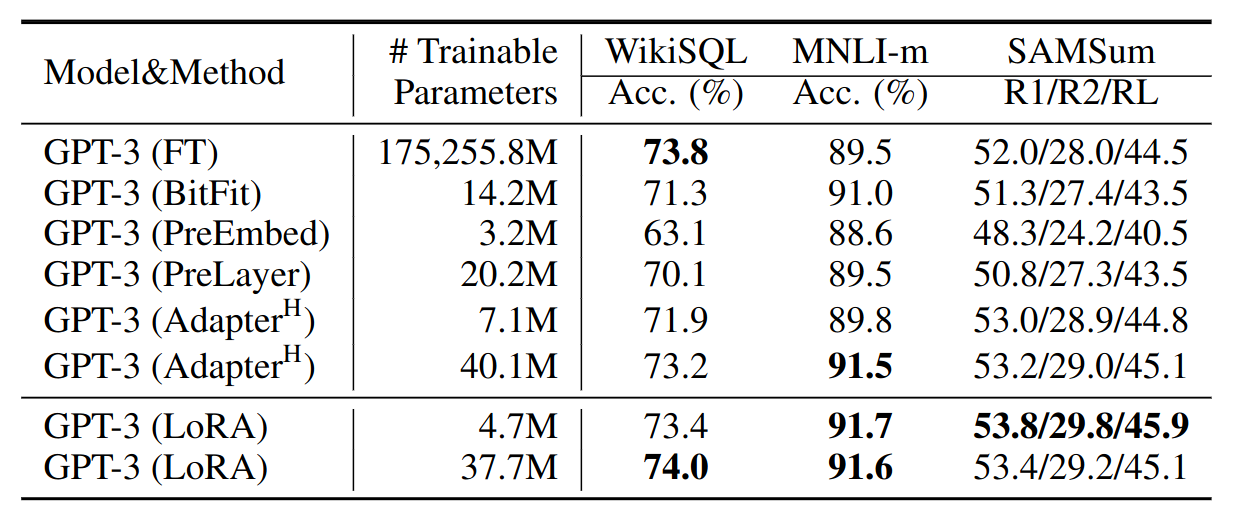
Performance of different adaptation methods on GPT-3 175B. Metric: logical form validation accuracy on WikiSQL, validation accuracy on MultiNLI-matched, and Rouge-1/2/L on SAMSum.
Is LoRA Robust Against Number of Trainable Parameters?
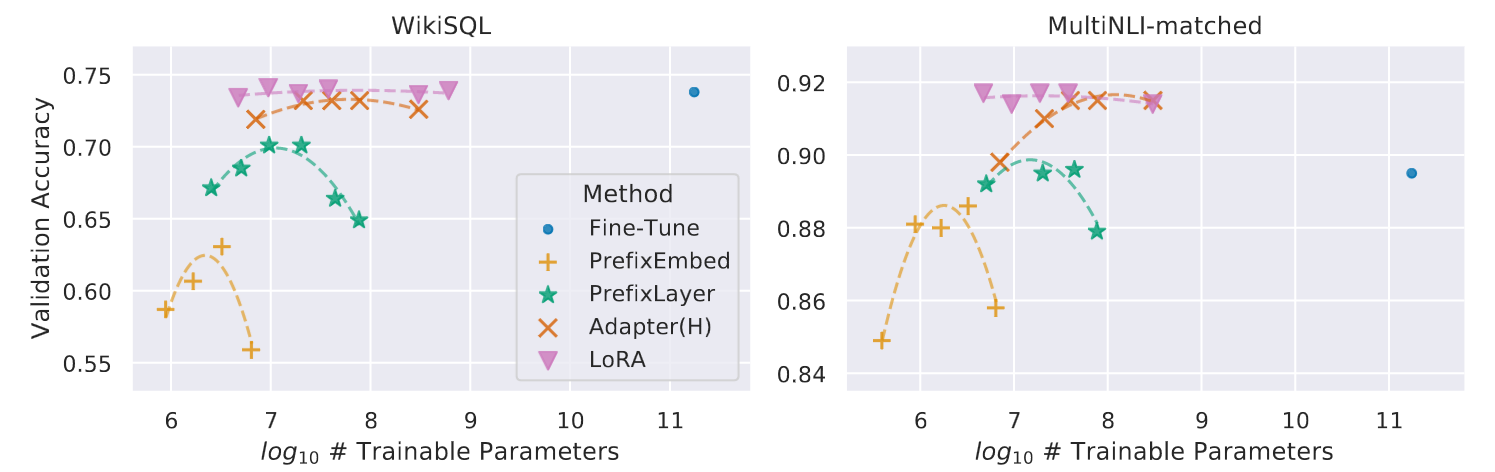
GPT-3 175B validation accuracy vs. number of trainable parameters of several adaptation methods on WikiSQL and MNLI-matched. LoRA exhibits better scalability and task performance.
Ablation study: effect on adapting different types of attention weight matrices in a Transformer.
Which Weight Matrix in Transformer Should We Apply LoRA To?
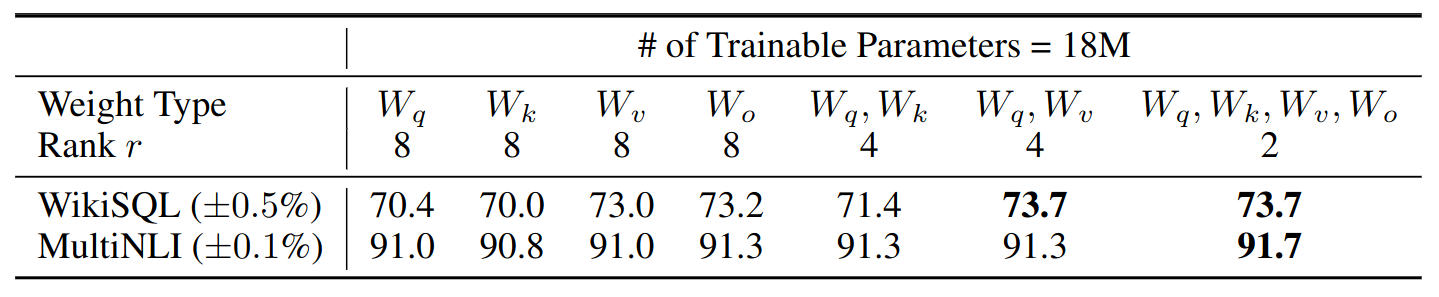
Validation accuracy on WikiSQL and MultiNLI after applying LoRA to different types of attention weights in GPT-3, given the same number of trainable parameters. Adapting both $W_q$ and $W_v$ gives the best performance overall.
What is the Optimal Rank $r$ for LoRA?
![]()
Validation accuracy on WikiSQL and MultiNLI with different rank $r$. To our surprise, a rank as small as one suffices for adapting both Wq and $W_v$ on these datasets while training Wq alone needs a larger $r$. We conduct a similar experiment on GPT-2.