FlashAttention
This post is mainly based on
- Data Movement Is All You Need: A Case Study on Optimizing Transformers
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- FlashAttention - Tri Dao | Stanford MLSys #67
- Making Deep Learning Go Brrrr From First Principles, Horace He
- ELI5: FlashAttention
Strongly recommend readers to go through Online Softmax to understand the scaling factor $l$ and the numerical stability term $m$ first.
Problem with Attention
- Computing and storing Attention matrix is costly (quadratic complexity)
- Motivation: longer sequence model generally results in better validation performance
- Three school solutions
- Hardware aware training
- Approximate attention (tradeoff quality for speed)
- Sparse attention: Sparse Transformer, Reformer. Routing Transformer
- Low rank approximation of attention: Linformer, Linear Transformer, Performer
- No wide spread adoption (due to reduce performance and computation overhead)
- MapReduce (summarize short sequence and combine into long sequence)
Terminology
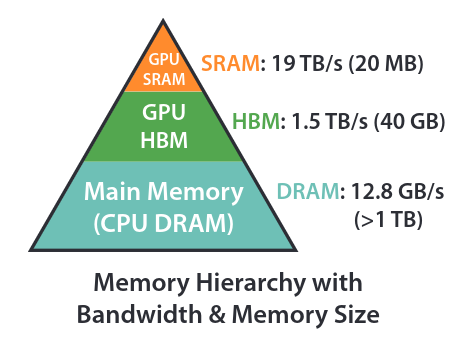
- GPU architecture
- CPU DRAM
- Speed: 25.6 GB/s (DDR4-3200)
- Size: >1 TB
- PCIe 4.0 x16 bandwidth: 32 GB/s
- GPU DRAM: Dynamic Random-Access Memory
- GPU’s off-chip main memory
- Speed: 1.5 TB/s (HBM)
- Size: 40 GB
- SRAM: Static Random-Access Memory
- GPU’s fast on-chip cache memory
- Speed: 19 TB/s
- Size: 20 MB
- Compute: fundamental processing / where compute actually happens
- Streaming multiprocessors (SMs) or shader cores
- Tensor cores
- CPU DRAM
- Tiling
- A technique used in GPU computing to optimize memory access patterns and increase data locality
- Partitioning a data set into smaller, contiguous tiles that fit within the (SRAM)
- Exploit the high bandwidth / low latency SRAM, minimize to access DRAM
- Kernel fusion
- A compiler optimization technique used to combine multiple loops or kernel operations into a single loop or kernel
- Goal: reduce memory access and improve cache utilization
- Tensor contraction
- Generalized matrix multiplication (rank-2 tensors)
- Summing over paired indices in tensors to produce a new tensor with reduced rank
Types of Runtime Costs
- Compute cost
- Compare CPU and GPU speed
- A100: 312 trillion FLOPS
- Python: 32 million FLOPS
- The time that Python can perform a single FLOP, an A100 could perform 9.75 million FLOPS
- Compare CPU and GPU speed
- Data transfer cost
- Memory bandwidth cost: moving data from DRAM to SRAM
- Data transfer costs: moving data from CPU DRAM to GPU DRAM
- Network costs: moving data from one GPU node to another (for distributed training)
- Overhead cost
- All remaining cost
- Exmaples
- Time spent in the Python interpreter
- Time spent in the PyTorch framework
- Time spent launching CUDA kernels (but not executing them)
- Example (unary operation, e.g., dropout)
- Overhead cost: preparing to launch kernels
- Data transfer cost: Move data from DRAM to SRAM
- Compute cost: SM access SRAM and perform a tiny bit of computation
- Data transfer cost: Move data from SRAM to DRAM
- High memory bandwidth cost for the example above
- Remedy: Kernel Fusion
- Instead of moving data to DRAM just to read it back again, we performing several computations at once
- Example: GELU takes nearly same time as ReLU, desipte have more operations
- Question: do we even need activation checkpointing?
- Recompute might be faster than moving data, hence cost less runtime
- For A100: until we’re doing ~100 unary operator operations, we’ll be spending more time performing memory accesses than actual compute
PyTorch Efficiency
- PyTorch have many layers of dispatch before getting to actual compute kernel
- A lot of time needs to be spent on “figuring out what to do”
- Example: when compute a + b, the following steps need to happen
- Look up what add dispatches to on a
- Determine many attributes of the tensor (
dtype,device,autograd?) to determine which kernel to call - Actually launch the kernel
- Fundamentally, overhead cost comes from the flexibility of being able to do something different at each step
- Pro: Flexible in eager mode
- Con: For scientific computing / tiny tensors, PyTorch could be incredibly slow compared to C++
- Remedy
- Asynchronously execution to reduce overhead cost
- While running a CUDA kernel, PyTorch can continue and queue up more CUDA kernels behind it
Data Movement is All You Need
- Training become memory-bound, rather than compute-bound
- Megatron report achieving only 30% of peak GPU FLOPS
- Existing implementations do not efficiently utilize GPUs
- Findings
- Key bottleneck when training transformers is data movement
- BERT training
- Memory-bound operations: 37% runtime
- Tensor contractions: 99% FLOPS, 61% runtime
- New approach
- Reduce data movement by up to 22.91%
- 1.3x performance improvement on BERT encoder layer
Dataflow Analysis
- Tools
- Data-Centric (DaCe) parallel programming framework
- Stateful Dataflow multiGraph (SDFG)
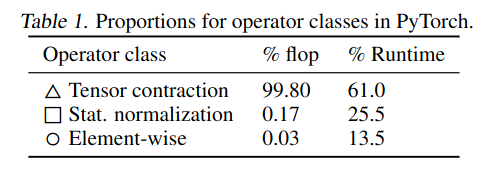
- Breakdown of FLOP & runtime
- PyTorch implementation of BERT encoder layer
- Normalization: 250x slower than Tensor contraction/MatMul (in FLOP)
- Element-wise: 700x slower than Tensor contraction/MatMul (in FLOP)
Custom Kernels
- More efficient than NVFuser and XLA
- Limitations: CUDA code is hard to write
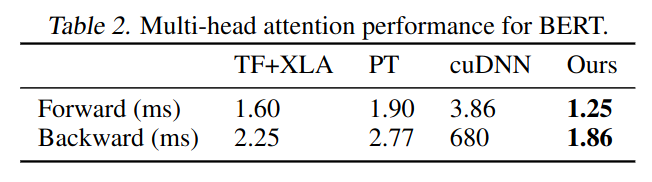
FlashAttention
- Hardware-Aware Optimization
- Goal: optimize Read/Write to different levels of memory to reduce GPU memory IOs
- Technique
- Tiling: load block by block from HBM to SRAM to compute attention
- Recomputation: don’t store attention matrix, recompute it in backward pass
- Results on Exact Attention
- Benchmark: vanilla PyTorch implementation
- 2-4x faster
- 10-20x more memory efficient (linear complexity)
Forward + backward runtime of standard attention and FlashAttention for GPT-2 medium. Despite higher FLOP, fewer HBM access greatly improves runtime.
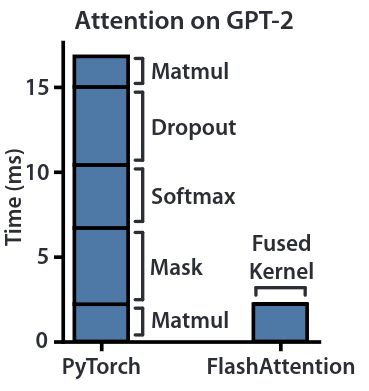
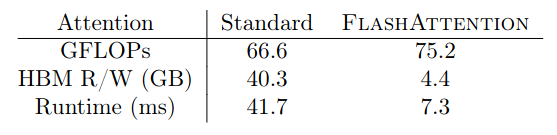
FlashAttention does not read and write the attention matrix to HBM, resulting in an 7.6x speedup on the attention computation.
Standard Attention Implementation
Matrix Computation
- $Q,K,V \in \mathbb{R}^{N \times d}$
- Attention Score Matrix: $S=QK^T \in \mathbb{R}^{N \times N}$
- Attention Matrix: $P=\text{softmax}(S) \in \mathbb{R}^{N \times N}$
- Output Matrix: $O = PV \in \mathbb{R}^{N \times d}$
- Where
- $N$: sequence length
- $d$: head dimension
softmax()on $S \in \mathbb{R}^{N \times N}$ is applied row-wise
Algorithm 0
- Requires: Matrices $Q, K, V$ in HBM
- Load $Q, K$ by blocks from HBM, compute $S = QK^T$, write $S$ to HBM.
- Read $S$ from HBM, compute $P = \text{softmax}(S)$, write $P$ to HBM.
- Load $P, V$ by blocks from HBM, compute $O = PV$, write $O$ to HBM.
- Return $O$.
Analysis
- Problems of Algorithm 0
- Memory bounded: storing attention matrix $P$ requires $O(N^2)$
- I/O bounded: element-wise operation on $S$ or $P$ (e.g., masking, dropout)
- How to reduce Memory requirement and I/O?
- Idea: perform most computation in block in SRAM
- Avoid storing intermediate matrices
- Reduce R/W to HBM
- Challenge 1: Compute softmax without access to row of $S$ matrix
- Challenge 2: Backward without the large attention matrix from forward
- Idea: perform most computation in block in SRAM
- Solution
- Solution to Challenge 1: Tiling
- Solution to Challenge 2: Recomputation
- FlashAttention implement fused CUDA kernel, instead of using pytorch suboptimal computation graph
Tiling (Section 3.1, Appendix B.1, B.3)
Difference between Memory Efficient Self-attention (MESA) and FlashAttention (FA)
- Query-chucks are in outer loop in MESA, but they are in inner loop in FA
- FA have block size defined in algorithm, but MESA requires user to define chuck size
- FA is implemented in CUDA, MESA is implemented in JAX
Algorithm 1 (forward pass only)
- Initialization
- Calculate key-value block size $B_c = \lceil \frac{M}{4d} \rceil$
- Calculate query block size $B_r = \min( \lceil \frac{M}{4d} \rceil, d )$
- Calculate key-value block number $T_c = \lceil \frac{N}{B_c} \rceil$
- Calculate query block number $T_r = \lceil \frac{N}{B_r} \rceil$
- Divide $K, V$ into $T_c$ blocks of dim $B_c \times d$
- Divide $Q$ into $T_r$ blocks of dim $B_r \times d$
- Divide $O$ (output embedding) into $T_r$ blocks of dim $B_r \times d$
- Divide $l$ (softmax denominator / scaling factor) into $T_r$ blocks of dim $B_r$
- Divide $m$ (numerical stability term) into $T_r$ blocks of dim $B_r$
- Outer loop: Load $K_j$ and $V_j$ into SRAM
- Inner loop
- Load $Q_i, O_i, l_i, m_i$ into SRAM
- Compute Online Softmax
- $O_i$ is updated multiple times as we loop though $j$
- For $O_i$ computed from $j-1$ outer loop, adjust it with scaling factor $l$
- Add new attention score adjusted $V_j$ into this scaling factor adjusted $O_i$
- Wite the new $O_i$ to HBM (to be updated again in $j+1$ outer loop)
- Update $l_i, m_i$ and wite to HBM
- Return $O$
Algorithm 1 compute attention $O = \text{softmax}(QK^T)V$ with $O(N^2d)$ FLOPs and requires $O(N)$ additional memory beyond inputs and output.
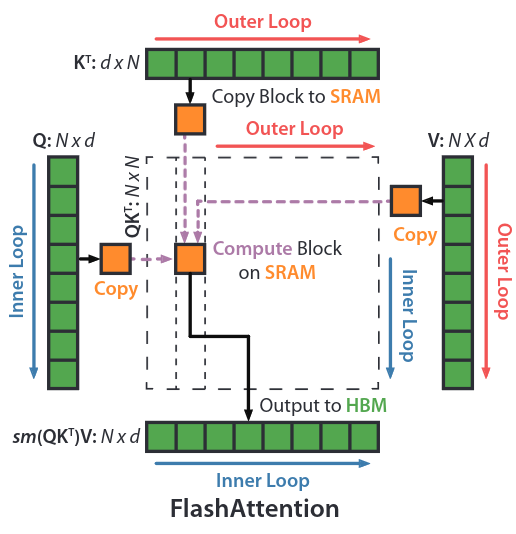
Tiling: partitioning a data set into smaller, contiguous tiles that fit within the (SRAM).
Recomputation (Section 3.1, Appendix B.2, B.4)
- Goal: avoid storing $O(N^2)$ attention matrix for the backward pass
- Can recompute the attention matrix $S, P$ easily in the backward pass from $O, l, m, Q, K, V$
- Can be seen as a form of selective gradient checkpointing (?)
- Tradeoff more computation for reduced memory. Even with more FLOPs, FlashAttention achieved speed up in backward pass due to reduced HBM access.
IO Complexity
- See paper’s Section 3.2
Experiments
- Training Speed
- Outperforms 15% MLPerf 1.1 speed record
- Speedup on GPT-2: 3x over HuggingFace and 1.8x over Megatron
- Quality
- Train 4k-GPT2 faster than Megatron 1k-GPT2, achieve 0.7 lower perplexity
- 6.4 points of lift on two long-document classification task: MIMIC-III and ECtHR
- Beat SOTA transformer on Path-X and all SOTA sequence model on Path-256
- Memory
- Memory footprint of FlashAttention scales linearly with seq. length
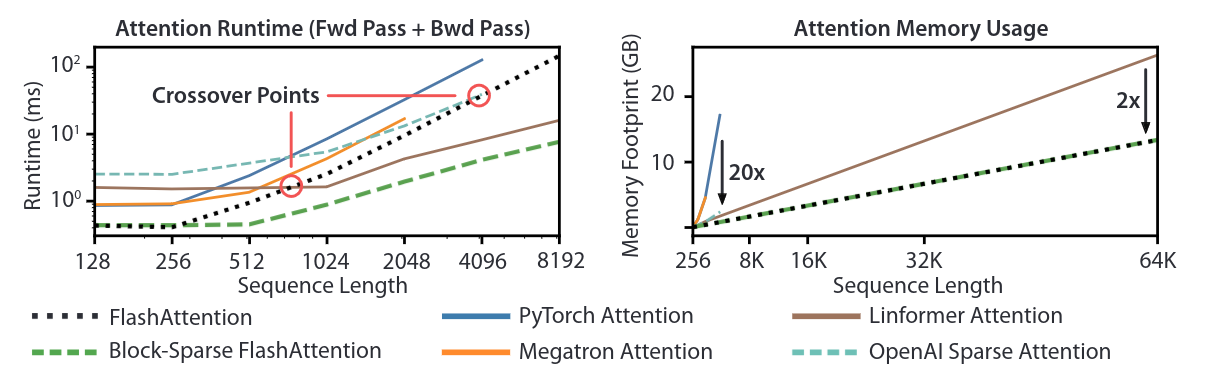
Left: runtime of forward pass + backward pass. Right: attention memory usage.