Tokenization
This post is mainly based on
- Neural Machine Translation of Rare Words with Subword Units, 2015
- Summary of the tokenizers - Hugging Face
New progress made on Word Embedding since 2013 led to a new problem in NLP preprocessing: how to deal with unknown tokens UNK or out-of-vocabular (OOV) words.
The problem is in a open open-vocabulary setting, it is impossible to construct a dictionary that consists of every word with existing word stemmer. So should we just map all UNK tokens to the same embedding? There is also a practical concern of using a very big vocabulary: it will result in a large embedding layer which cause deterioration in language model performance. In 2015, the vocabulary size is typically limited to 30,000 - 50,000 in neural models.
Early solutions (for example, mentioned in this 2014 paper to solve NMT rare word problem) use a back-off dictionary: a point is assigned for each UNK token in source language. In the postprocessing step, they directly translate the source word using a dictionary or copy the source word if no translation is found. This is hardly an ideal solution since in the most cases, the rare word contains key information. Treating them as a same UNK token removes context information from the autoregressive model. The authors stated that back-off dictionary works well when there are only a few unknown words in the target sentence, but it has been observed that the translation performance degrades rapidly as the number of unknown words increases.
Byte Pair Encoding
The Byte Pair Encoding (BPE) technique originate from a compression algorithm. BPE as a compression algorithm tries to detect repeated segments of data and replace them with some encoding to save communication cost. The 2015 paper adapt BPE to the task of word segmentation. It is based on the assumption that each word can be decomposed into some meaningful part. For example: lower_ -> low + er_ (the “_” character represent end of a word). This is useful for languages with morphologically complex forms. For sample, solar system in German is Sonnensystem_, which can be decompose into Sonnen + system_
Algorithm
- Run a pre-tokenizer which splits the text data into words
- Initialize the symbol vocabulary with the character vocabular (a to z, A to Z)
- Each word can be represent with this initial vocabulary (with “_” character represent end of a word)
- Repeat until reach vocabulary size $k$:
- Count frequency of all symbol pairs (e.g., aa, ab, ac, …)
- Merge the most frequent pair with a new symbol (say AB)
- Add the merged pair to the vocabulary (new vocabulary: a to z, A to Z, AB)
Each merge operation produces a new symbol which represents a character n-gram. Frequent character n-grams (or whole words) are eventually merged into a single symbol. If you still confused about the algorithm, checkout this video from Stanford CS124.
The BPE algorithm should produce no UNK tokens, as in the worst case scenario, a OOV word is going to be mapped into a sequence of single characters. BPE allows for the representation of an open vocabulary through a fixed-size vocabulary of variable-length character sequences, making it a very suitable word segmentation strategy for neural network models.
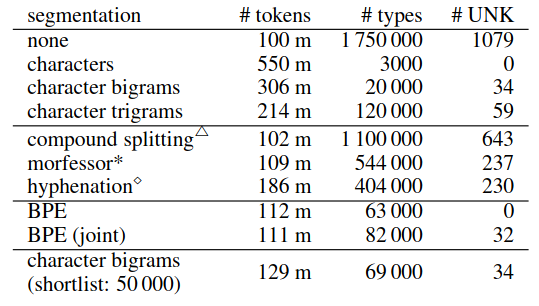
Corpus statistics for German training corpus with different word segmentation techniques. #UNK: number of unknown tokens in newstest2013. BPE (joint): learning the encoding on the union of the two vocabularies. I’m no sure why there is UNK tokens in joint BPE.
For the specific case of NMT, the authors need to consider if the model should:
- Just copy: named entities
- Directly map / dictionary: cognates and loanwords
- Translate subword: morphologically complex words
Please refer the original paper for detailed discussions.
The empirical result show that BPE encoded subword models outperforms the back-off dictionary baseline.
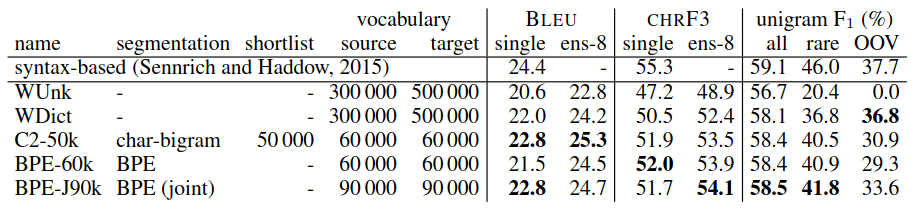
English to German translation performance (BLEU, CHRF3 and unigram F1) on newstest2015. Ens-8: ensemble of 8 models. Best NMT system in bold. Unigram F1 (with ensembles) is computed for all words (n = 44085), rare words (not among top 50 000 in training set; n = 2900), and OOVs (not in training set; n = 1168). WUnk and WDict are back-off dictionary based models.
Other Tokenizer
Hugging Face’s Summary of the tokenizers page provides a good review of different tokenizers used by various language models
- BPE: GPT-2, RoBERTa
- WordPiece: BERT, DistilBERT, and Electra
- SentencePiece: ALBERT, XLNet, Marian, and T5