H3: Hungry Hungry Hippo
This post is mainly based on
Hungry Hungry Hippo / H3
- Known issues with SSM
- SSM underperform attention in language modeling
- SSM still slower than Transformers due to poor hardware utilization
- Understanding expressivity gap between SSMs and attention in language modeling
- Existing SSMs struggle with two capabilities
- Recalling earlier tokens in the sequence
- Comparing tokens across the sequence
- H3
- Matches attention on the synthetic languages
- Competitive to Transformers on OpenWebText (gap < 0.4 PPL)
- Hybrid H3-attention model outperforms Transformers on OpenWebText by 1.0 PPL
- Existing SSMs struggle with two capabilities
- Reducing the hardware barrier between SSMs and attention
- Optimization
- Fused block FFT algorithm
- State passing algorithm
- Speedup
- 2x speedup on the long-range arena benchmark
- 2.4x faster inference than Transformers
- 2.7B model trained on the Pile
- Lower perplexity than Transformers
- Outperforms Transformers in zero/few-shot learning on a majority of SuperGLUE tasks
- Optimization
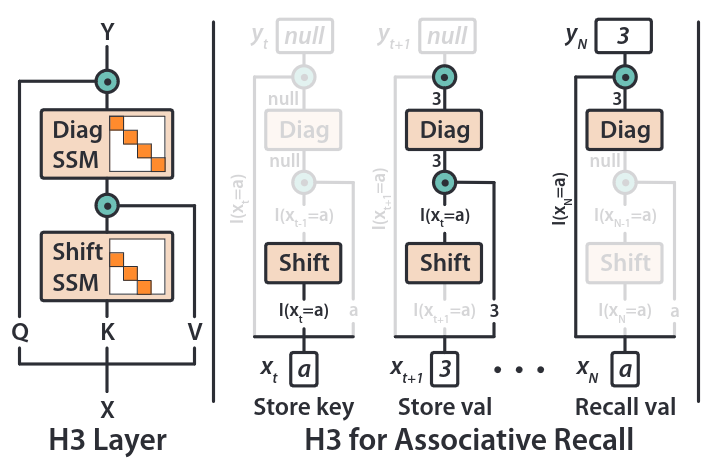
H3 Architecture
- Stacks two SSMs
- Compute multiplicative interactions between SSMs outputs and input projections
- Enable H3 to keep a log of tokens and compare them across the sequence later
Fused block FFT algorithm
- FFT-based convolution improves speed over vanilla convolution on long kernel
- The cuFFT implementation is inefficient
- I/O bounded
- Cannot utilize the FP16 tensor core (For A100, FP16=312 TFLOPs/s, FP32=20 TFLOPs/s)
- Fused Block FFT
- Fuses the FFT, pointwise multiply, and inverse FFT to reduce memory I/O
- Block FFT algorithm for sequence lengths up to 8K (fit into GPU SRAM)
Novel state passing algorithm
- Splits the input into the largest chunks that can fit into GPU SRAM
- Efficiently computes the FFT-based convolution using block FFT
- Updates an intermediate state to start the next chunk.
Background
Motivation
It is unclear what cause the performance gap between Transformer and SSM
- Inherent inductive biases and capabilities in attention?
- Result of resources spent training and tuning large attention-based LM?
State Space Models
\[y = \operatorname{SSM}_{A,B,C,D}(u)\] \[\begin{align} x'(t) &= Ax(t) + Bu(t)\\ y(t) &= Cx(t) + Du(t) \end{align}\]where
- $A \in \mathbb{R}^{m \times m}$, a matrix that can be parametrized as diagonal or diagonal plus low-rank
- $B \in \mathbb{R}^{m \times 1}$
- $C \in \mathbb{R}^{1 \times m}$
- $D \in \mathbb{R}^{1 \times 1}$
For details, please refer to S4.
SSM through FFTs
- Convolution with naive matrix operations cost $O(N^2)$, which is expensive for long kernels
- Convolution with FFTs cost $O(N \log N)$
- Take the FFT of $f$ and $u$
- Multiply FFT coefficients together pointwise
- Take the inverse FFT
Linear Attention
\[O_i = \frac{\sum_{j=1}^i \text{Sim}(Q_i, K_j) V_j}{\sum_{j=1}^i \text{Sim}(Q_i, K_j)} \in \mathbb{R}^d\]The standard softmax attention $\text{Sim}(q,k) = \frac{\exp(q^\top k)}{sqrt{d}}$ can be view as an inner product on some kernel function $\phi$:
\[\text{Sim}(q,k) = \phi(q)^\top \phi(k)\]The output can be rewrite as:
\[O_i = \frac{\phi(Q_i)^\top \sum_{j=1}^i \phi(K_j) V_j^\top}{\phi(Q_i)^\top \sum_{j=1}^i \phi(K_j)}\]Let,
- $S_i = \sum_{j=1}^i \phi(K_j)V_j^\top \in \mathbb{R}^{d \times d}$
- $z_i = \sum_{j=1}^i \phi(K_j) \in \mathbb{R}^d$
- $d_i = \phi(Q_i)^\top z_i \in \mathbb{R}$
The output can be rewrite as:
\[O_i = \frac{\phi(Q_i)^\top S_i}{d_i}\]where $S_i, z_i$ are incrementally updated in the $\sum_{j=1}^i$, much like an RNN updates its hidden states incrementally.
Synthetic Language Modeling Tasks
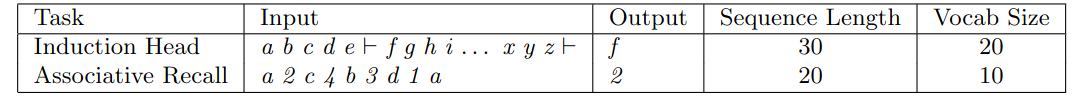
Sample synthetic language modeling tasks.
Induction Head Task
- Tests how well a model can recall content after a special token (e.g., $|-$)
- At the end of the sequence, the model must recall the token that appeared immediately after the special token earlier in the sequence
Associative Recall
- Requires the model to remember multiple key-value pairs
- At the end of the sequence, the model must recall a specific value belonging to a specific key (e.g., sequence ends with $a$, so look up for $a$ $2$)

Evaluation of 2-layer models on synthetic language tasks.
Analysis
- S4D and Gated State Spaces both fail to model these synthetic languages
- S4D and Gated State Spaces miss two capabilities
- Remember tokens that appear after a particular event (Induction Head Task)
- Compare tokens across the sequence (Associative Recall)
- H3 is designed to narrow the expressivity gap between SSMs and attention
H3 Layer
- Shift and diagonal matrices
- Multiplicative operations against projections of the input
High-level Intuition
Remember Tokens From the Past
- State $x_i$ copy from the input $u_i$
- State $x_i$ pass that information to the next state $x_{i+1}$
Given the state update operation $x_{i+1} = Ax_i$, a discrete SSM with a shift matrix $A$ can shifts the elements of a state vector:
\[[a, b, c] \to [0, a, b]\]Compare Tokens Across the Sequence
- Take the output of an SSM (containing information from previous time steps)
- Take the input at the current time steps
- Multiply the above 2 to measuring similarity between tokens
This is called multiplicative interaction.
H3 vs Linear Attention
Recall Linear Attention has update:
\[O_i = \frac{\phi(Q_i)^\top S_i}{d_i}\]H3 is loosely inspired by linear attention:
- Project the input $u$ to get three signals $Q, K, V$
- Replace the non-linearity $\phi(K)$ with an SSM where state update matrix $A$ is a shift matrix ($\text{SSM}_{\text{shift}}$)
- Replace the summation $S_i$ with a SSM with diagonal A ($\text{SSM}_{\text{diag}}$)
The output, for the case of head dimension $d_h = 1$, is:
\[Q \odot \text{SSM}_{\text{diag}}(\text{SSM}_{\text{shift}}(K) \odot V)\]where $\odot$ denotes pointwise multiplication
More details please refer to paper’s Appendix B.
Remembering Key Tokens: Shift and Diagonal SSMs
Shift SSMs
The Shift SSMs have state update matrix $A$:
\[A_{i,j} = \begin{cases} 1 & \text{for } i - 1 = j \\ 0 & \text{otherwise} \end{cases}\]Here is a solid example of how it works:
Let $B = e_1$, which will copy $u_i$ to the first element of $Bu_i$ with all other elements equals to zero.
Recall the SSM has state update function $x_i = Ax_{i−1} + Bu_i$, $A$ will shift all elements of previous state $x_{i-1}$ one position down:
\[[u_{i-1}, u_{i-2}, ... , u_{i-m+1} , u_{i-m}] \to [0, u_{i-1}, ... , u_{i-m+1}]\]$Ax_{i−1} + Bu_i$ will assign the newly copied $u_i$ to the first position of $x_i$:
\[[0, u_{i-1}, ... , u_{i-m+1}] \to [u_i, u_{i-1}, ... , u_{i-m+1}]\]In practice, $B$ and $C$ are learned.
Diagonal SSMs
$A$ is diagonal and initializes from the diagonal version of HiPPO (S4D).
This parameterization allows the model to remember state over the entire sequence.
The shift and diagonal SSMs are designed to enable H3 to log tokens after particular events:
- Shift SSM: detect when a particular event occurs
- Diagonal SSM: remember a token afterwards for the rest of the sequence
Multiplicative Interaction for Comparison
- The multiplicative interactions between the output of the shift SSM and the $V$ projection mimics local multiplicative interactions in linear attention
- The multiplicative interactions with the Q projection and the output of the diagonal SSM allows comparisons between tokens over the entire sequence
H3 Layer Algorithm
- MLPs
- Residual connection
- Layer norm

Expressivity of H3 Layer
Evaluation of 2-layer models on synthetic language tasks.

Perplexity of 12-layer model on OpenWebText. All models have size around 125M and trained on same hyperparameters for 50B tokens.
FlashConv
- Kernel fusion: fuses FFT, pointwise multiply, and inverse FFT to reduce memory I/O
- For sequence lengths < 8K: Block FFT algorithm
- For sequence lengths > 8K: State-passing algorithm
- FlashConv can speed up any SSMs
Fused Block FFTConv
Kernel Fusion
\[\text{iFFT}(\text{FFT}(u) \odot \text{FFT}(f))\]where
- $u$: input
- $f$: conv filter
- $\odot$: pointwise multiplication
Fuse the entire FFTConv into a single kernel and compute it in SRAM to avoid this overhead
Block FFT
[TBD]
State-Passing
The recurrent nature of SSMs allows us to split the FFTConv of a length-$N$ sequence into chunks of size $N’$ each
- $N’$ is the longest FFT we can fit into SRAM
- Assuming $N$ is a multiple of $N’$
Experiments
Language Modeling with H3
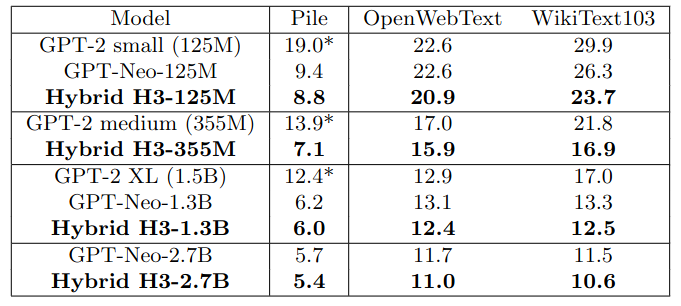
Perplexity on various corpus. GPT-Neo and hybrid H3 are trained on the Pile, while GPT2 is trained on WebText. All models use the same GPT2 tokenizer. Perplexity of GPT-2 models on the Pile is marked with (∗), due to the performance is not directly comparable since they were trained on different data.
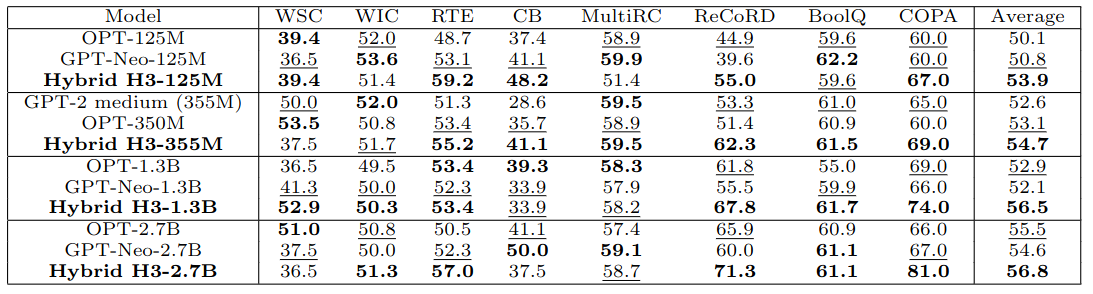
Zero-shot acc. on SuperGLUE.
Inference Throughput
- A100 80GB / 1.3B models
- Hybrid H3-1.3B has up to 2.4x higher throughput compared to Transformer-1.3B.
FlashConv on Long Range Arena
- FlashConv accelerates S4 by 2x, outperforming Transformers by 5.8x.
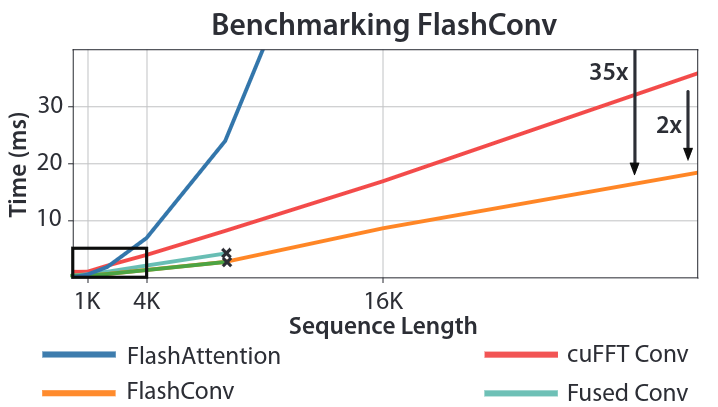
For long sequences, FlashConv yields speed 2.3x faster vs cuFFT Conv, and 35x vs FlashAttention.