MLOps
This post is mainly based on
MLOps
- Wikipedia - MLOps
- Databricks - MLOps
- A set of best practices
- Motivation: productionize ML models are difficult, requiring collaboration between multiple teams
- Goal: deploy and maintain machine learning models in production, improve efficiency, scalability, and risk reduction
- Approach: workflow abstraction and increase automation
- ML lifecycle management
- Model generation (Software development lifecycle, CI/CD)
- Orchestration
- Deployment
- Health, diagnostics, governance, and business metrics
- One way to breaking down ML lifecycle
- Data collection, data processing, feature engineering, data labeling
- Model design, model training and optimization
- Endpoint deployment, and endpoint monitoring
- MLOps Tools
- Model metadata storage and management
- MLflow
- Data and pipeline versioning
- DVC
- Orchestration and workflow pipelines
- Kubeflow
- Polyaxon
- SageMaker Pipelines
- Production model monitoring
- SageMaker Model Monitor
- Model metadata storage and management
Why MLOps?
- Technical Debt
- A metaphor introduced by Ward Cunningham
- Refer to: long term costs incurred by moving quickly in software engineering
- Technical debt may be paid down by
- Refactoring code
- Improving unit tests
- Deleting dead code
- Reducing dependencies
- Tightening APIs
- Improving documentation
- The goal is not to add new functionality, but to
- Enable future improvements
- Reduce errors
- Improve maintainability
- Technical Debt in ML
- Developing and deploying ML systems is relatively fast and cheap
- However, maintaining ML systems over time is difficult and expensive, due to
- Abstraction boundary erosion
- Entanglement
- Data dependency > Code Dependency
- Feedback loops
- System-level anti-patterns
- Configuration debt
- Changes in the external world
Abstraction Boundary Erosion
- Traditional software engineering
- Enforce strong abstraction boundaries using encapsulation and modular design
- This help create maintainable code in which it is easy to make isolated changes and improvements.
- ML system
- Difficult to enforce strict abstraction boundaries or prescribing specific intended behavior
- ML is create to handle problems where the desired behavior cannot be effectively expressed in software logic without dependency on external data
- The real world does not fit into tidy encapsulation
- Traditional abstractions and boundaries may be subtly corrupted or invalidated, due to data dependency
Entanglement
- Machine learning systems mix signals together, entangling them and making isolation of improvements impossible.
- Example
- Consider a ML system that makes prediction based on features $x_1, …x_n$
- Mathematically, a ML model is a mapping $f: x \rightarrow y$, which minimize some loss $\mathcal{L}(\hat{y}, y)$
- Suppose new data flows in and contains anomalies that change the distribution of $x_1$, and we update the model (retrain or train from checkpoint)
- The new mapping $f’$, trained with anomalies, may not minimize loss $\mathcal{L}(\hat{y}, y)$ under the original distribution
- Possible Mitigation
- Isolate models: final output is based on an ensembles of explainable features
- Detecting changes in prediction behavior
Data Dependency > Code Dependency
- Code dependencies can be identified via static analysis (e.g., compilers and linkers)
- Data Dependency can be hard to analyze without appropriate tools
- Unstable Data Dependencies
- Model consume features produced by other systems
- Examples
- One ML model consume output of another ML model
- One ML model consume output of some data dependent features (e.g., population mean or TF-IDF score)
- Mitigation: create versioned copy of signals
- Underutilized Data Dependencies
- Model consume features that provide little incremental modeling benefit
- Examples
- Legacy Features
- Bundled Features: a group of features is evaluated and found to be beneficial
- $\epsilon$-Features: feature with high complexity but very small accuracy gain
- Correlated Features
- Mitigation: regularly detect and remove, s.t., the ML system is less vulnerable to change
Feedback loops
- Live ML systems that update regularly over time
- Direct feedback loops
- A model’s prediction directly affects the data it will collect in the future
- Example: an algorithm choosing which ad to present to a consumer
- Requires knowledge in bandit problem / reinforcement learning to analyze these feedback loops
- Hidden feedback loops
- Two or more models’ prediction directly affects the data they will collect in the future
- Example: two stock-market prediction model choose how to execute trades
System-level anti-patterns
- Only a tiny fraction of code in ML system is devoted to model specification (learning or prediction)
- Glue Code & Pipeline Jungles
- Supporting codes/pipelines to transform data into format that ML model can consume
- May caused by incremental model improvement / adding features
- Problems
- Difficult to maintain
- Requires many error detections / failure recovery logic, requires expensive end-to-end integration tests
- Many intermediate files output
- Mitigation
- Wrap open-source packages into API
- Reduce separation between “research” and “engineering” arm
- Dead Experimental Codepaths
- Experimental codepaths for experiments / ablation studies
- Mitigation: periodic review
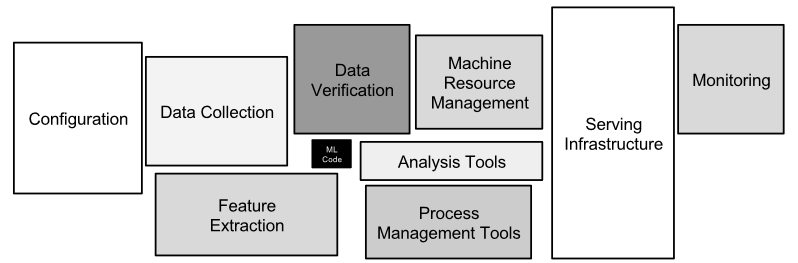
Configuration debt
- Too many configuration for a ML system
- Feature selection
- Data selection / tran-test split
- Model architecture
- Hyperparameter
- Various pre- / post-processing
- Many researchers and engineers treat configuration as an afterthought
- Principles of good configuration systems
- Easy to specify a small change from a previous configuration
- Easy to detect the difference two configurations
- Easy to automatically assert and verify basic facts about the configuration
- Configurations should undergo a full code review and be checked into a repository
Changes in the external world
- ML systems often interact directly with the external world, which is rarely stable
- Fixed Thresholds in Dynamic Systems
- Specify a decision threshold / prediction range
- Learning thresholds from a heldout validation set
- Monitoring and Testing
- Unit test may be inadequate for an online system
- Comprehensive live monitoring is required to ensure that a system is working as intended
- Monitor
- Prediction distribution shift
- Action Limits
- Up-Stream Producers
- External changes occur in real-time, therefore, response must also occur in real-time
Useful questions to consider
- How easily can an entirely new algorithmic approach be tested at full scale?
- What is the transitive closure of all data dependencies?
- How precisely can the impact of a new change to the system be measured?
- How quickly can new members of the team be brought up to speed?