Big Data
Big data can refers to dataset that are
- Too large in Volume: to be handle by a single machine
- Too large in Velocity: speed of data collection / generation
- Too large in Variety: structured / unstructured
Special frameworks (e.g., Hadoop) are required to handle big data.
Hadoop
Main Modules
- Hadoop Distributed File System (HDFS)
- A file system that handles large data sets running on commodity hardware (low-cost, scalable hardware)
- Scale a single Apache Hadoop cluster to hundreds/thousands of nodes
- Yet Another Resource Negotiator (YARN)
- Manages and monitors cluster nodes and resource usage
- It schedules jobs and tasks.
- MapReduce: a framework that for parallel computation
- Hadoop Common: client (Java) libraries used to communicate with Hadoop’s common components (HDFS, MapReduce, YARN)
HDFS Assumptions
- Hardware Failure: fault detection, quick/automatic recovery
- Streaming Data Access: data is stored in batch and “streaming” (maintaining the maximum I/O rate)
- Large Data Sets
- Simple Coherency Model: write-once-read-many access, once a file is created/written/closed is will not changed
- “Moving Computation is Cheaper than Moving Data”
- Portability Across Heterogeneous Hardware and Software Platforms
NameNode vs DataNodes
- NameNode = manager
- Manages the file system namespace and regulates access to files by clients
- Determines the mapping of blocks to DataNodes
- DataNode = worker
- Manage storage attached to the nodes that they run on
- A file is split into one or more blocks and these blocks are stored in a set of DataNodes
- A typical block size used by HDFS is 64 MB
- The blocks of a file are replicated for fault tolerance
- If possible, each block will reside on a different DataNode
Row vs Column Oriented Storage
- Difference between Row oriented and Column oriented data stores in DBMS
- Column-Based or Row-Based: That is the Question, Scene 2
A tabular dataset can be stored in row oriented vs column oriented storage approach
- Row oriented
- Sequentially stored row by row
- Adjacent rows are physically close on disk
- Column oriented
- Sequentially stored column by column
- Column data are grouped together
Database performance is typically limited by disk I/O, therefore, choice of row vs column orientation depends on application
- Row-oriented
- Best suited for Online Transactional Processing (OLTP)
- Query is typically looking up a single record
- Column-oriented
- Best suited for Online Analytical Processing (OLAP)
- Query is typically value comparison, group or sort
Big Data File Format
The data format of files in HDFS or data lake is critical to their performance. Factor to be considered include:
- Access pattern: read vs write
- Query type: transactional vs analytical processing
- Schema Evolution: adding or removing fields
- Splittable: e.g., file needs to be divided into blocks in HDFS
- Compression: compression rate, performance
Popular File formats
- AVRO
- Row-oriented storage / OLTP
- Splittable
- Enforce schema / Highly supports schema evolution
- Parquet
- Column-oriented storage / OLAP
- Splittable
- Enforce schema / Supports schema evolution
- Restricted to batch processing
- Support nested structures
- ORC (Optimized Row Columnar)
- Column-oriented storage / More efficient for OLAP than OLTP queries
- Splittable
- Enforce schema / Does not support schema evolution
Parquet
Column-oriented storage is not inherently splittable: records are first partitioned into row groups, then each row group is store in column-oriented structure:
- Row group
- A logical horizontal partitioning of the data into rows
- A row group consists of a column chunk for each column in the dataset
- Column chunk
- A chunk of the data for a particular column
- Column chunks in row group are guaranteed to be contiguous in the file
- Page
- Column chunks are divided up into pages written back to back
- The pages share a standard header and readers can skip the page they are not interested in
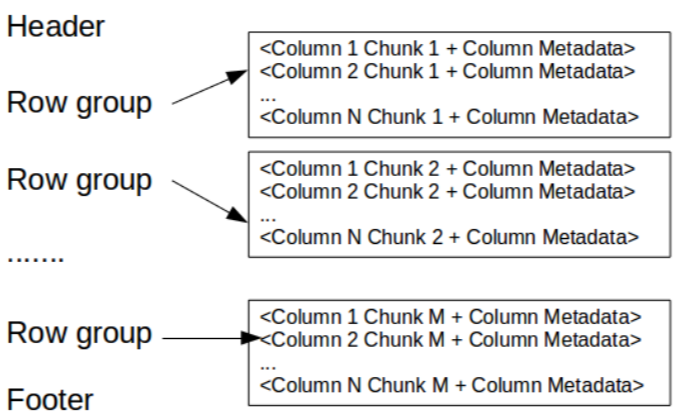
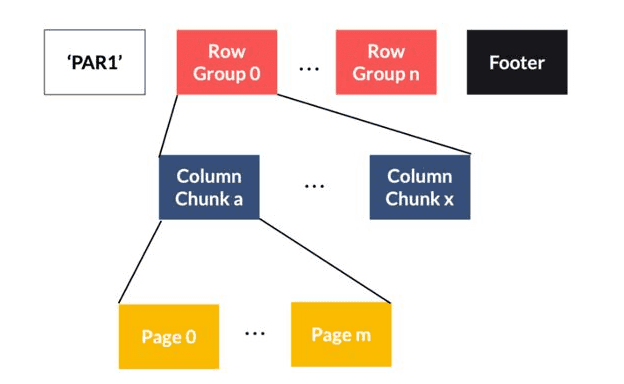
Image from clairvoyant.ai and adaltas.com
ORC
Similar to parquet, ORC partitions records into stripes. Column-oriented storage is implemented within each strip. The default stripe size is 250 MB. Large stripe sizes enable large, efficient reads from HDFS. Index data include min and max values for each column and the row’s positions within each column, which enables more optimized OLAP queries.
Parquet vs ORC
- ORC is more capable of Predicate Pushdown
- ORC supports ACID properties
- ORC is more compression efficient
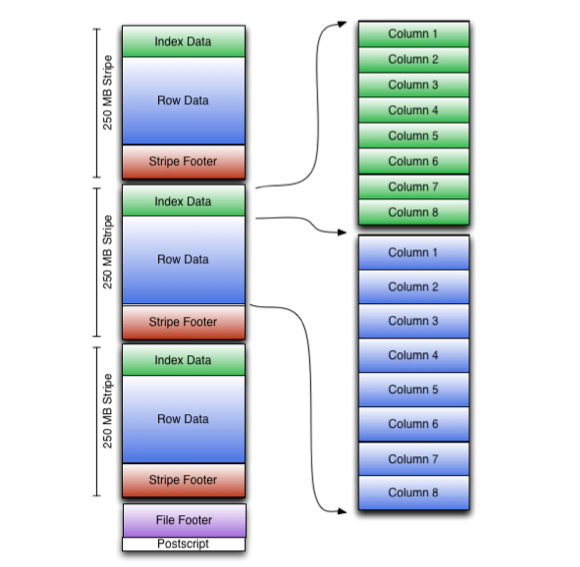
Image from clairvoyant.ai