Inter-Rater Reliability
This post is mainly based on
- Computing Inter-Rater Reliability for Observational Data: An Overview and Tutorial
- A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research
- Inter-rater reliability
- Intraclass correlation
The quality of a measuring instruments can be evaluated by:
- Reliability: the extent to which the measures are consistent
- Validity: the extent to which the measures are accurate
Inter-Rater Reliability (IRR) can be used to evaluate the consistency of ratings provided by multiple coders. The coder is used as a generic term for describing the individuals who assign ratings in a study.
The rating / score from a coder can be decomposed in the following way:
\[X = T + E\]where $X$ denote the observed score, $T$ denote the ground truth score and $E$ denote the measurement error. If $T$ and $E$ are independent, then we have the variance:
\[Var(X) = Var(T) + Var(E)\]And reliability is defined as:
\[\operatorname{Reliability} = \frac{Var(T)}{Var(X)}\]i.e., the proportion of the observed variance originate from the measurement error. A low reliability implies measurement error is high, i.e., agreement between coders are low.
Since $T$ and $E$ are not observed, IRR can only be estimated by some estimators. For example: Kappa for categorical variables or Intra-Class Correlation for ordinal, interval, or ratio variables.
One may consider using Pearson correlation as a estimator of IRR. However, Pearson correlation requires ratings from a pair of coders. It cannot handle cases where (1) there are more than 2 coders or (2) different subjects are rated by different coders.
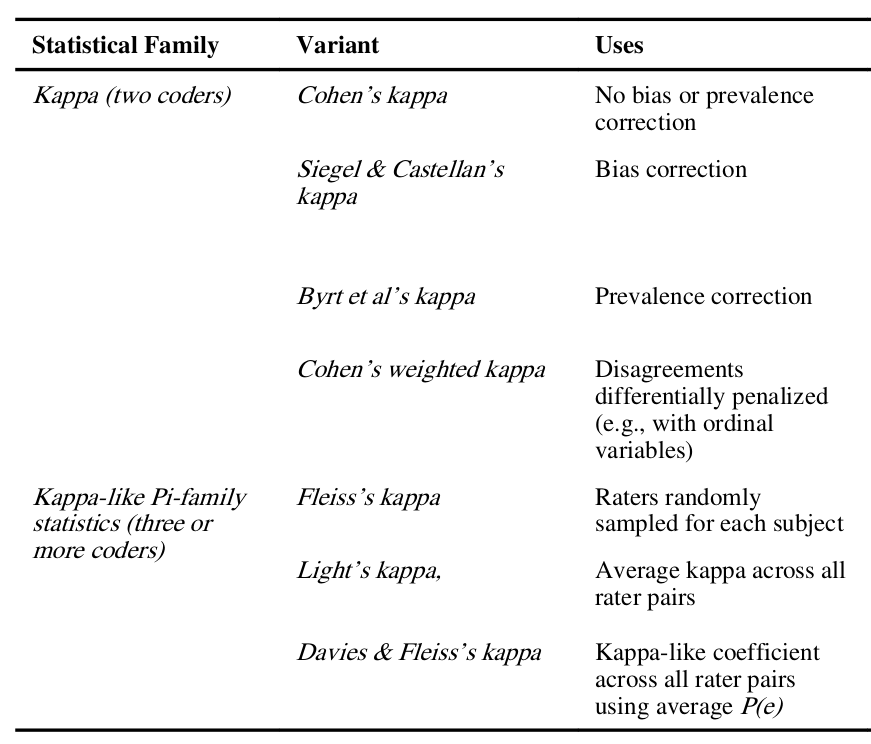
Kappa
Cohen’s kappa and its variants are commonly used for assessing IRR for nominal / categorical variables. The variants are developed for:
- Bias/prevalence correction
- Non-fully crossed designs
Cohen’s Kappa
\[\kappa = \frac{P(a)-P(e)}{1-P(e)}\]where $P(a)$ denotes the observed percentage of agreement, and $P(e)$ denotes the probability of expected agreement due to chance. Consider the following agreement matrix for Coder A and B:
| Coder A - Absent | Coder A - Present | |
| Coder B - Absent | 42 | 13 |
| Coder B - Present | 8 | 37 |
$P(a) = (42 + 37)/100 = 0.79$
$P(e) = 0.5 \times 0.45 + 0.5 \times 0.55 = 0.5$
Hence, $\kappa = (0.79-0.5)/(1-0.5) = 0.58$
Properties
- $\kappa \in [-1,1]$
- $\kappa \in [0.61, 0.80]$: substantial agreement
- $\kappa \in [0.81, 1.0]$: almost perfect or perfect agreement
- When the marginal distributions of observed ratings largely fall under one category, kappa estimates can be unrepresentatively low
- When the marginal distributions of specific ratings are substantially different between coders, kappa estimates can be unrepresentatively high
Kappa Variants
Intra-Class Correlation (ICC)
Intra-class correlation (ICC) is commonly used for assessing IRR for ordinal, interval, and ratio variables. ICCs are suitable for:
- Studies with two or more coders
- All subjects in a study are rated by multiple coders
- Only a subset of subjects is rated by multiple coders and the rest are rated by one coder
- Fully-crossed designs
- Coders are randomly selected for each subject
Consider a rating $X_{ij}$ provide to subject $i$ by coder $j$:
\[X_{ij} = \mu + r_i + e_{ij}\]where $\mu$ is the mean of the ground truth score, $r_i$ is the deviation from the ground truth mean or $Var(T)$, and $e_{ij}$ is the measurement error or $Var(E)$.
If we consider the possibility that some coder may make systematic error (e.g., biased to provide higher score), the above equation can be expand to:
\[X_{ij} = \mu + r_i + e_{ij} + c_j + rc_{ij}\]where $c_j$ is the bias of coder $j$ (the degree that coder $j$ systematically deviates from the ground truth mean), and $rc_{ij}$ represents the interaction between subject derivation and coder error.
Variance of the term $e_{ij}, c_j, c_{ij}$ are used to compute ICC. There are many different variants of ICC and those variants are constructed using different combination of the above terms.
ICC is defined under two conventions: Shrout and Fleiss convention and McGraw and Wong convention. The detailed calculation and conversion between those two conversion can be found at Table 3 of the Koo and Li paper.
Koo and Li’s guideline for interpreting ICC is:
- ICC < 0.50: poor
- 0.50 < ICC < 0.75: moderate
- 0.75 < ICC < 0.9: good
- ICC > 0.90: excellent
A visualization of difference between ICC variants:
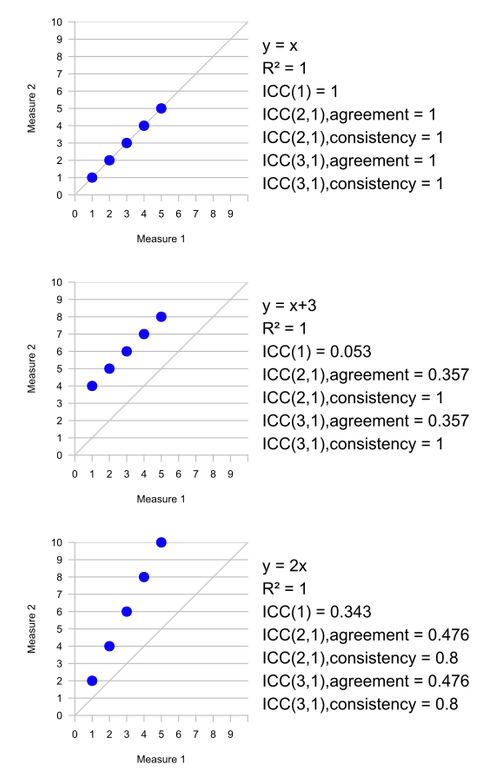
Detailed description can be found at the Wikipedia page.