Are Transformers Effective for Time Series?
This post is mainly based on
Personal Thoughts
- Dataset Size Issue
- The authors of this paper and Informer, Autoformer, FEDformer paper all conducted experiments on very small time-series datasets (all < 70k timesteps), which may leads to poor performance of Transformers
- In “Section 5.3 Is training data size a limiting factor for existing LTSFTransformers?”, the authors compared the performance of Transformer model trained on small and large data set. Since large dataset doesn’t lead to lower MSE, they argue that training data size is not the limiting reason
- However, it is possible that LTSF-Transformers overfit on the both datasets. An RNN may require upwards of 10M timesteps to avoid overfitting on certain TS-prediction problems
- Lack of Optimization Details
- The authors of this paper did not discuss their optimization details, e.g., convergence, training vs testing loss
Long-term time series forecasting (LTSF)
- Attention mechanism is permutation-invariant, which could result in information loss
- Experiments
- Datasets: 9, including traffic, energy, economics, weather, and disease predictions
- Benchmark model: repeats the last value in the look-back window
- LTSF-Linear: simple one-layer linear models
- LTSF-Transformer: FEDformer, Autoformer, Informer
- Findings
- Positional encoding cannot effectively preserve ordering information
- LTSF-Linear outperforms LTSF-Transformer in all cases, often by a large margin
- Challenge the effectiveness of using Transformers for LTSF tasks
Preliminaries
- Importance of Positional Information
- NLP: semantic meaning of a sentence is largely preserved even if we reorder some words
- Time series: order of data plays the most crucial role
- Multi-step Forecasting
- IMS: iterated multi-step forecasting
- DMS: direct multi-step forecasting
LTSF-Transformer
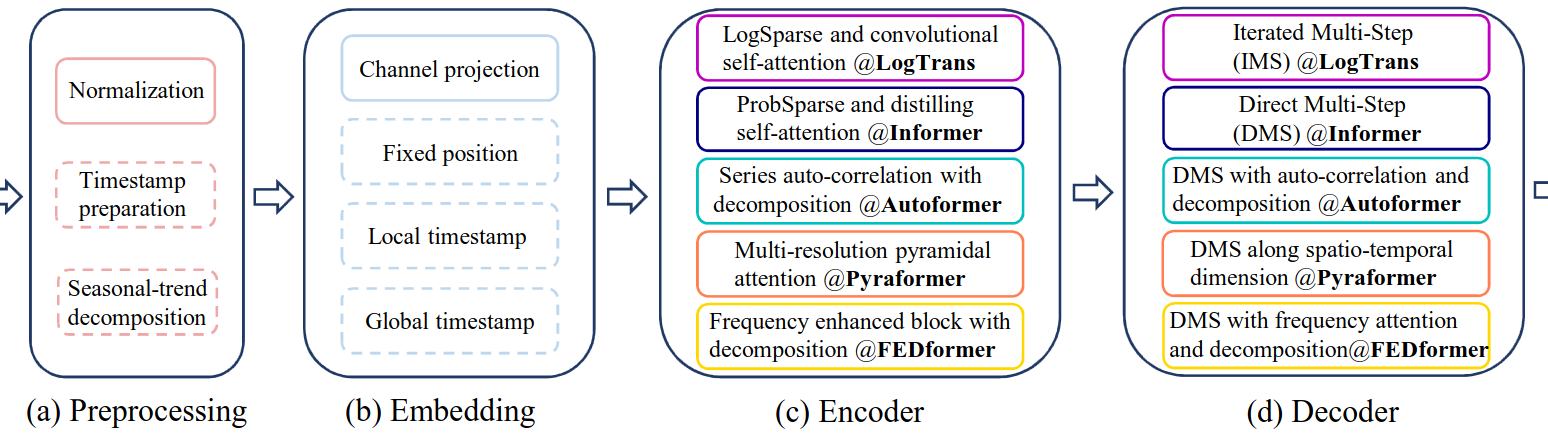
- Preprocessing
- Normalization: zero-mean centering
- Seasonal-trend decomposition (Autoformer): moving average kernel, extract the trend-cyclical component
- mixture of experts decomposition (FEDformer): moving average kernels with various kernel sizes
- Embedding
- Goal: perserve temporal context (e.g., week, month, year, holidays and events)
- Injecting several embeddings (e.g., a fixed positional encoding, a channel projection embedding, and learnable temporal embeddings)
- Self-attention
- Sparsity bias: Logsparse mask (LogTrans), pyramidal attention (Pyraformer)
- Low-rank approximation of attention matrix (Informer and FEDformer)
- ProbSparse, a self-attention distilling (Informer)
LTSF-Linear
- LTSF-Linear is a set of linear models
- Vanilla Linear is a one-layer linear model
- To handle time series across different domains (e.g., finance, traffic, and energy domains), we further introduce two variants with two preprocessing methods, named DLinear and NLinear.
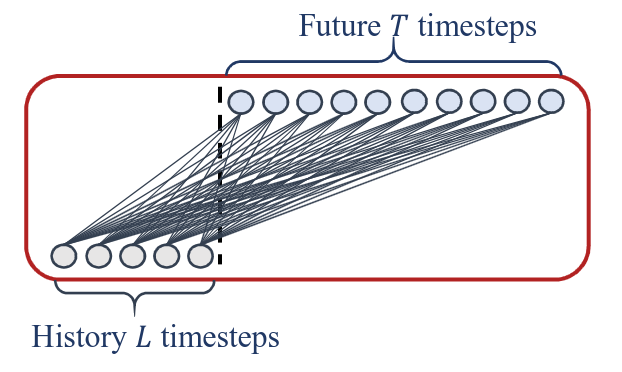
Vanilla LTSF-Linear.
- DLinear
- Use cases: a clear trend exists in the data
- Steps
- Decomposes data into a trend component (by moving average kernel) and a remainder / seasonal component
- One-layer linear layers are applied to each component
- Sum up the two features
- NLinear
- Use cases: distribution shift exists in the data
- Steps
- Subtracts the input by the last value of the sequence
- input goes through a linear layer
- Subtracted part is added back
Experiment
LTSF Evaluation
- Forecast horizon T: 24-60 or 96-720
- Evaluation: MSE and MAE
- Linear vs Transformer Improvement: See paper’s Table 2
Qualitative Evaluation
- Input length: 96 steps
- Output horizon: 336 steps
- Electricity & ETTh2 dataset
- FEDformer & Autoformer: overfit input data
- Informer: unable to capture seasonality
- Exchange-Rate dataset
- Transformer based model cannot predict a proper trend
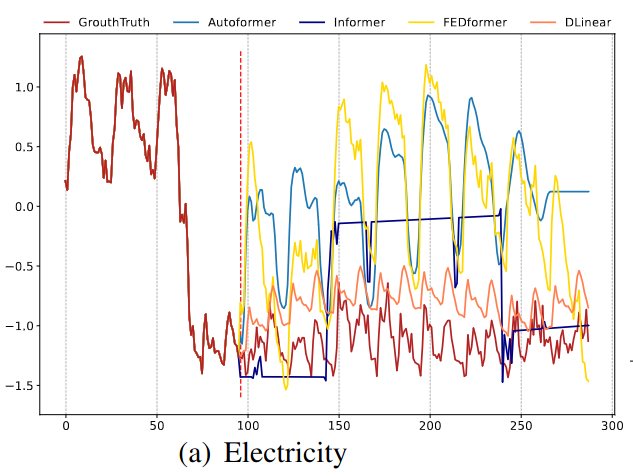
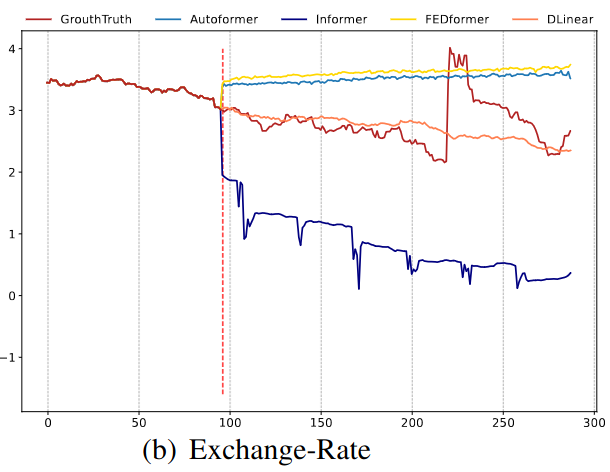
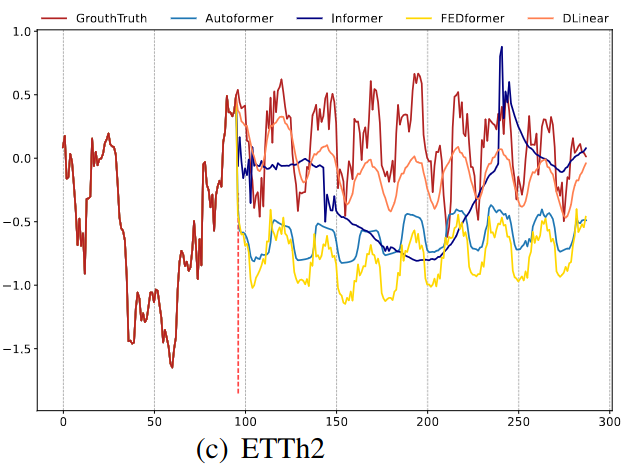
Illustration of the long-term forecasting output (Y-axis) of five models with an input length L=96 and output length T=192 (X-axis).
Performance vs Context Length
- Linear: increase look-back window significantly boosted performance
- Transformer: performance not improve when the look-back window increases
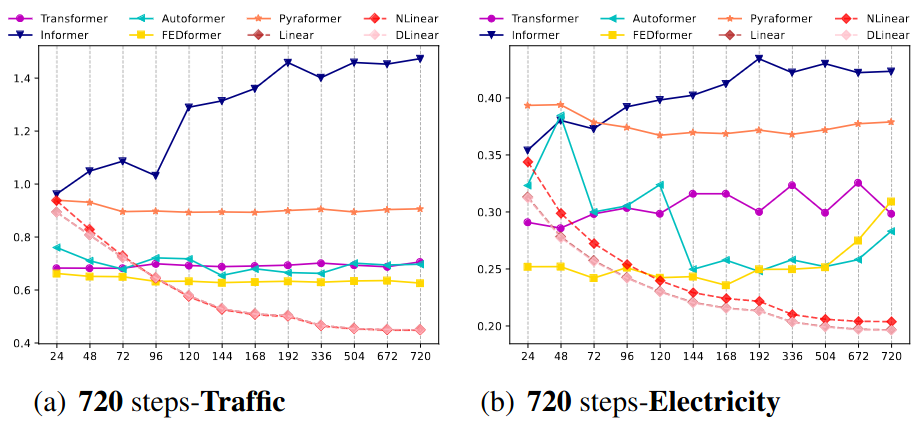
The MSE results (Y-axis) of models with different look-back window sizes (X-axis) of long-term forecasting (T=720) on the Traffic and Electricity datasets
Does LTSF-Transformers Preserve Temporal Order?
- Shuffle the raw input before the embedding
- Shuf: randomly shuffles the whole input sequences
- Half-Ex: exchanges the first half of the input sequence with the second half
- Exchange Rate Data
- The performance of all Transformer-based methods does not fluctuate even when the input sequence is randomly shuffled
- By contrary, the performance of LTSF-Linear is damaged significantly
- Conclusion
- Embeddings preserve quite limited temporal relations and are prone to overfit on noisy financial data
- The average drops of LTSF-Linear are larger than Transformer-based methods for all cases, indicating the existing Transformers do not preserve temporal order well
- For details, see paper Table-5