Instruction Tuning
This post is mainly based on
- Human Generated
- Machine Generated
SUPERNI
- Super-NaturalInstructions Dataset
- 1616 diverse NLP tasks + expert-written instructions
- 76 distinct task types: classification, extraction, infilling, sequence tagging, text rewriting, text composition, etc.
- Contributed by 88 NLP practitioners, in response to public call
- Results
- Trained Tk-INSTRUCT (backbone: T5 model)
- Tk-INSTRUCT Outperforms existing instruction-following models (InstructGPT) by >9% on our benchmark despite being an order of magnitude smaller
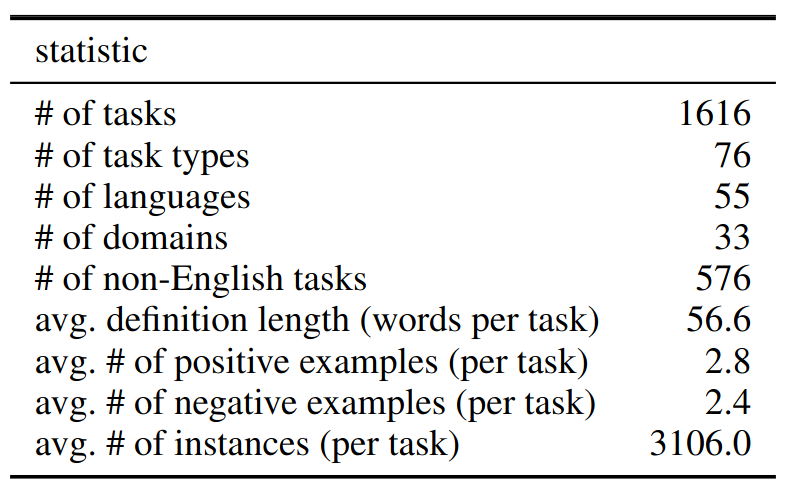
Statistics of SUP-NATINST.
SUP-NATINST
- A meta-dataset
- A dataset of datasets
- Consists of a wide variety of NLP tasks with their instructions
- Extends NATINST dataset
- 26x more tasks
- Greater variety of task types
- Instruction schema
- Definition: defines a given task in natural language / how to map input text to output text
- Positive Examples: (inputs, output), with a short explanation
- Negative Examples: (inputs, output), with a short explanation
- Task instances
- A unified format to organize the instances of all tasks
- Each instance consists of a textual input and a list of acceptable textual outputs
- Limit the number of instances in each task to 6.5K to avoid an imbalance dataset
- Data collection
- Source
- Existing public NLP datasets
- Available intermediate annotations in crowdsourcing experiments
- Synthetic tasks that can be communicated to an average human in a few sentences
- JSON files via GitHub pull requests
- Reviewed by automated checks and peers
- Source
- Evaluation Setup
- Evaluation tasks
- Fix a manually selected collection of 12 categories, representing 154 tasks
- Sample a maximum of 100 instances for each task, which results in 15,310 testing instances in total
- English cross-task generalization: 119 tasks
- Cross-lingual cross-task generalization: 35 tasks
- Evaluation Metrics
- ROUGE-L
- Human
- Evaluation tasks
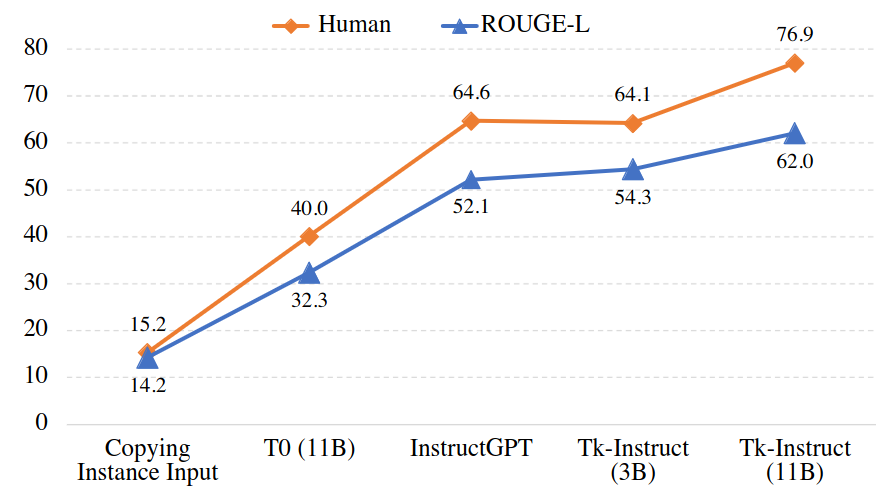
Human evaluation vs. ROUGE-L for several methods. Human evaluation align quite well with automatic metrics. For details, check paper Section 6.2 and Appendix B.
Results
- Model: Tk-INSTRUCT
- Goal: Generalization to Unseen Tasks at Scale
- Given: instruction $I_t$, dataset $(X_t, Y_t)$
- Learn: $y = M(I_t, x)$ for $(x,y) \in (X_t, Y_t)$
- Models that leverage instructions show stronger generalization to unseen tasks.
- Model fine-tuned on a diverse set of tasks outperforms InstructGPT and T0 by a large margin
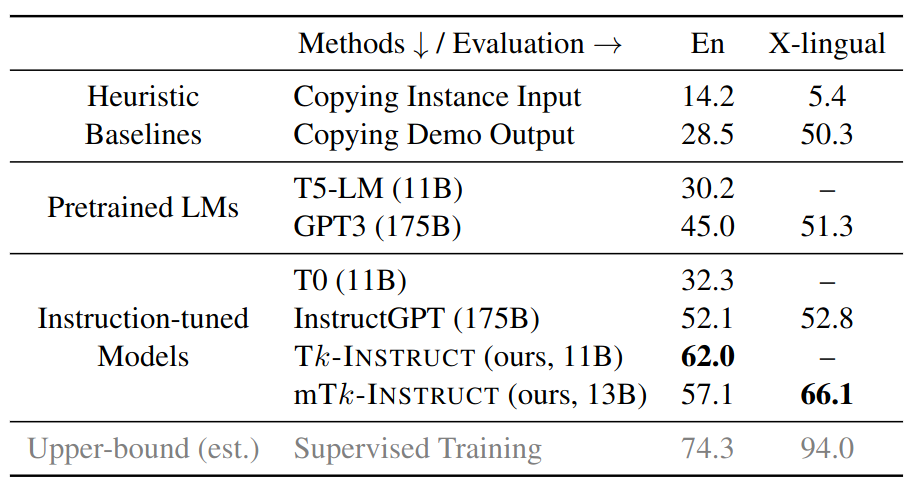
The overall performance of different methods on unseen tasks in the test set of SUP-NATINST. We report ROUGE-L here as our aggregated metric.
Scaling Trends of Generalization
- More observed tasks: better generalization
- Generalization performance grows log-linearly w.r.t. # of observed tasks
- More instances per task: not much impact
- Generalization performance saturates when only 64 instances per task are used for training
- Larger model: better generalization
- Generalization performance grows log-linearly w.r.t. model parameter size
- Trade-off
- Increasing the diversity of training tasks is an alternative to scaling model sizes
- T5-large model trained with 757 tasks $\approx$ T5-3B model trained with 128 tasks
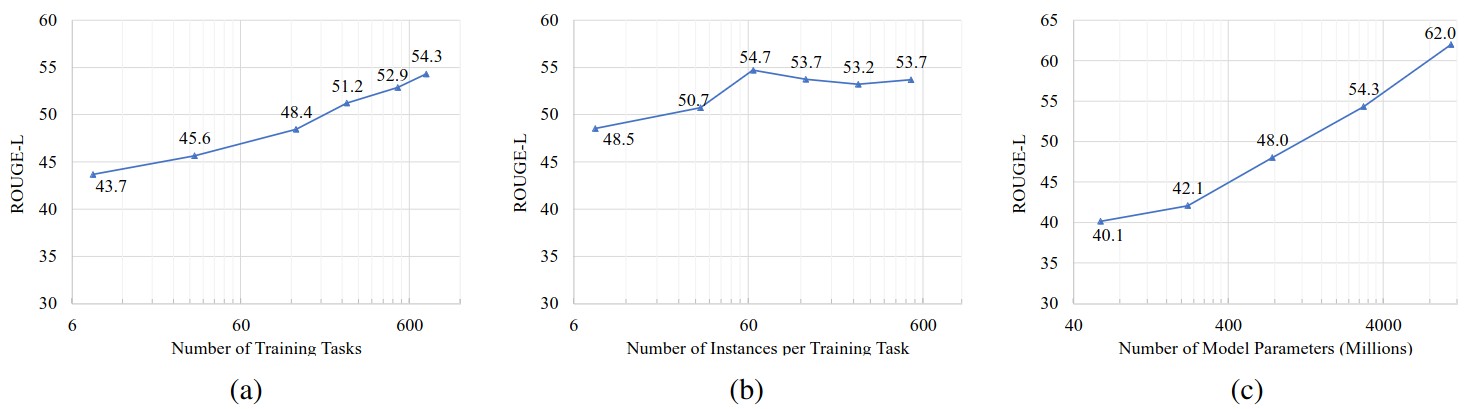
Scaling trends of models performance as a function of (a) the number of training tasks; (b) the number of instances per training task; (c) model sizes. x-axes are in log scale. Model performance increases with increase in observed tasks and model size. The performance gain from more instances per task is limited.
Self-Instruct
- A framework for generating instruction dataset
- Generate: (instructions, input, output)
- Filter: invalid or similar data
- Finetune the original model with generated instruction dataset
- Results on GPT-3
- 33% absolute improvement over fine-tuning on SUPER-NATURALINSTRUCTIONS
- Final model’s performance is comparable to InstructGPT001 / text-davinci-001
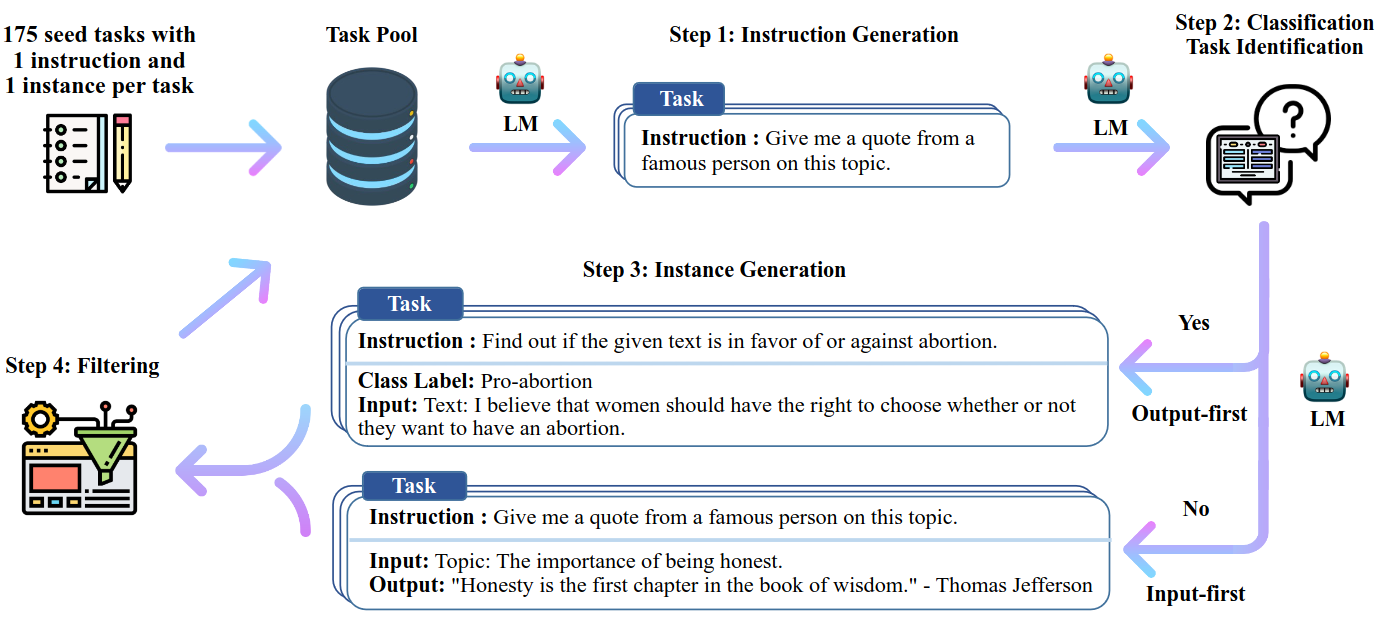
Procedure: bootstrap
Starts with 175 manually-written seed tasks in the task pool
Step 1: Instruction Generation
- In-context examples: 8 task instructions from the task pool
- 6 are human-written, 2 are model-generated
- Prompt: Table 5
Step 2: Classification Task Identification
- In-context examples: 31 classification examples from task pool
- 12 classification instructions, 19 non-classification instructions
- Prompt: Table 6
Step 3: Instance Generation
- Input-first prompt: Table 7
- Output-first prompt: Table 8
Step 4: Filtering and Postprocessing
- New instruction is added to the task pool only when all pairwise ROUGE-L similarity < 0.7
- Exclude
- Contains certain keywords (e.g., image, picture, graph)
- Instances with same input but different output
- Invalid generations (e.g., instruction is too long or too short)
SELF-INSTRUCT Dataset
- Statistics: see paper Table 1
- Diversity: see paper Figure 4
- Quality: see paper Table 2
Results
SUPERNI Evaluation Set
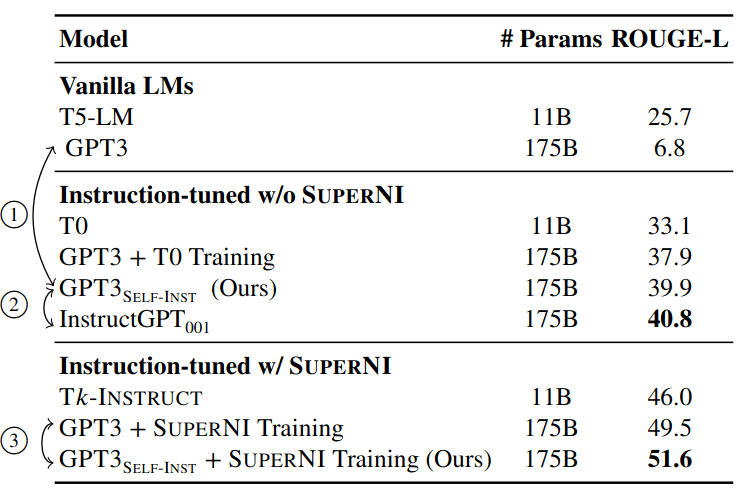
Evaluation results on unseen tasks from SUPERNI. 1: SELF-INSTRUCT can boost GPT3 performance by a large margin (+33.1%) 2: SELF-INSTRUCT nearly matches the performance of InstructGPT001. 3: SELF-INSTRUCT can further improve the performance even when a large amount of labeled instruction data is present.
Human Evaluation
- Grading
- RATING-A: The response is valid and satisfying.
- RATING-B: The response is acceptable but has minor errors or imperfections.
- RATING-C: The response is relevant and responds to the instruction, but it has significant errors in the content. For example, GPT3 might generate a valid output first, but continue to generate other irrelevant things.
- RATING-D: The response is irrelevant or completely invalid.
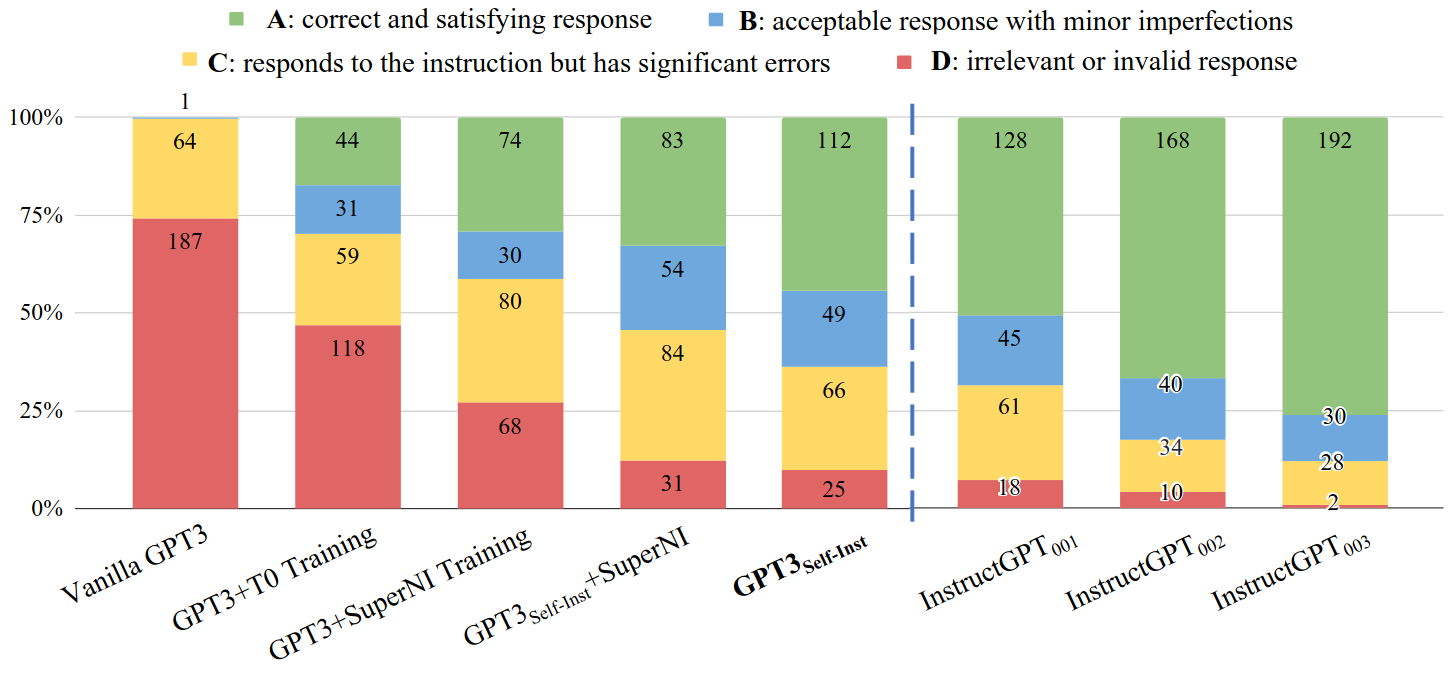
Performance of GPT3 model and its instruction-tuned variants, evaluated by human experts on our 252 user-oriented instructions. Human evaluators are instructed to rate the models’ responses into four levels (A-D). The results indicate that \(GPT3_{SELF-Inst}\) outperforms all the other GPT3 variants trained on publicly available instruction datasets. Additionally, \(GPT3_{SELF-Inst}\) scores nearly as good as \(InstructGPT_{001}\)
Scaling with Data Size
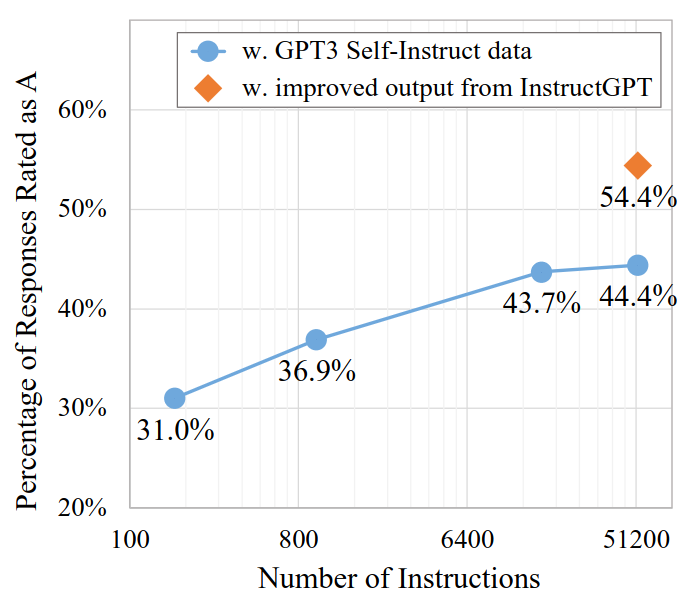
Human evaluation performance of GPT3SELF-INST models tuned with different sizes of instructions. x-axis is in log scale.
Data Quality
- Fix instruction and input
- Regenerate the output field of all our instances using InstructGPT003
Alpaca
- Base model: LLaMA-7B
- Fine-tuning Data
- 52K instruction-following demonstrations
- Following self-instruct framework generated by text-davinci-003
- Results
- Alpaca shows many behaviors similar to OpenAI’s text-davinci-003
- Surprisingly small and easy/cheap to reproduce (<$500 / 3 hours on 8 80GB A100s)
- Blind pairwise comparison: Alpaca wins 90 versus 89 comparisons against text-davinci-003
- Limitations: hallucination, toxicity, and stereotypes
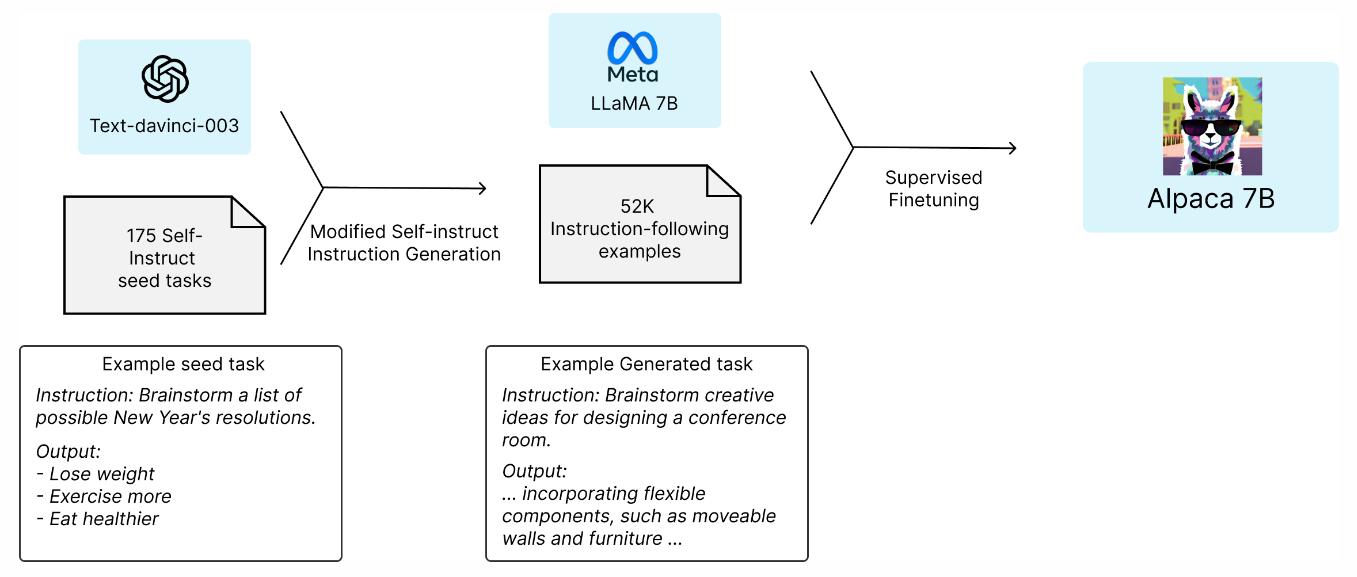
Alpaca training pipeline.
ShareGPT
- An open-source Chrome Extension for crowdsourcing ChatGPT data
- Dataset: search huggingface/datasets
Vicuna
- Base model: LLaMA-13B
- Data
- ~70K conversations from ShareGPT.com
- Enhanced Alpaca’s training scripts to better handle multi-turn conversations and long sequences (512 -> 2048)
- Cost: ~$1000 / 8 A100 GPUs in one day
- Results
- Eval: GPT-4
- Quality of answers are based on helpfulness, relevance, accuracy, and detail
- Findings - GPT-4 can produce highly consistent ranks and detailed explanations on why such scores are given - GPT-4 is not very good at judging coding/math tasks
- Outperforms LLaMA and Alpaca in more than 90% of cases
GPT-4-LLM
- Data: GPT-4 generated instruction
- Model: Instruction-tuned LLaMA models and reward models
- Evaluation
- Human evaluation on three alignment criteria
- Auto evaluation using GPT-4 feedback
- ROUGE-L on un-natural instructions
Data
- English Instruction-Following Data: reuse 52K unique instructions
- Chinese Instruction-Following Data: 52K translate into Chinese
- Comparison Data
Instruction Tuning
- Supervised finetuning
- Follow Alpaca’s training schedule
- RLHF
- Large-scale comparison data created by GPT-4
- Train a reward model based on OPT 1.3B
Benchmarks
- User-Oriented-Instructions-252
- 252 instructions, motivated by 71 user-oriented applications such as Grammarly, StackOverflow, Overleaf, rather than well-studied NLP tasks
- Vicuna-Instructions-80
- A dataset synthesized by gpt-4 with 80 challenging questions that baseline models find challenging
- Unnatural Instructions
- 68,478 samples synthesized by text-davinci-002 using 3-shot in-context-learning from 15 manually-constructed examples
Alignment Criteria: HHH
- Helpfulness: whether it helps humans achieve their goals. A model that can answer questions accurately is helpful
- Honesty: whether it provides true information, and expresses its uncertainty to avoid misleading human users when necessary. A model that provides false information is not honest
- Harmlessness: whether it does not cause harm to humans. A model that generates hate speech or promotes violence is not harmless