ViT & Discrete Tokenization
This post is mainly based on
BEiT
- Masked Image Modeling (MIM) loss
- “Tokenize” the original image into visual tokens, then randomly mask some image patches
- Pre-training objective: recover the original visual tokens based on the corrupted image patches
- Each image has two views in our pre-training
- Image patches (16×16 pixels)
- Visual tokens (discrete tokens)
- Competitive with SOTA
Architecture
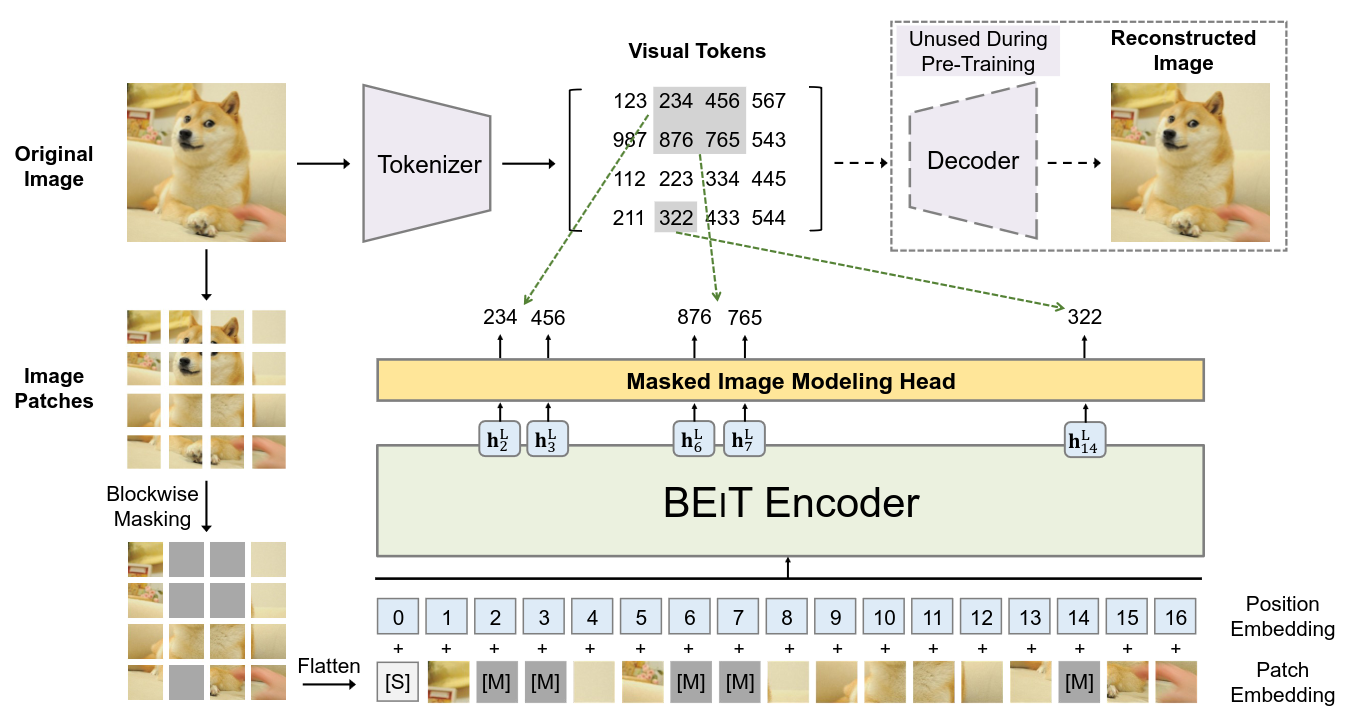
BEiT Architecture
- Before pre-training, we learn an “image tokenizer” via autoencoding-style reconstruction
- Image Representations
- Image patches
- Reshape an image $x \in \mathbb{R}^{H \times W \times C}$ into $N = HW/P^2$ patches
- Each patch have dim: $x^p_i \in \mathbb{R}^{P^2C}$, where $1 \leq i \leq N$
- $x^p_i$ are flatten into vectors and are linearly projected
- This paper: split $224 \times 224$ image into $14 \times 14$ grid of $16 \times 16$ image patches
- Visual tokens
- Map $x \in \mathbb{R}^{H \times W \times C}$ into $z = [z_1, …, z_N] \in \mathcal{V}^{N}$
- The vocabulary $\mathcal{V}$ contains 8192 discrete token indices
- Image tokenizer: learned by discrete variational autoencoder (dVAE)
- Tokenizer: $q_{\phi}(z | x)$
- Decoder: $p_{\psi}(x | z)$
- Non-differentiable / Gumbel-softmax
- For more details, see dVAE paper: Zero-shot text-to-image generation, PMLR 2021
- Image patches
- Backbone Network
- ViT-base: 12-layer, 768-dim, 12-head, 3072-FF size
- Input: ${ x^p_i }_{i=1}^N$
- Linear projection matrix $E \in \mathbb{R}^{(P^2C) \times D}$: project patches to ViT embeddings
- Learnable 1D position embeddings: $E_{pos} \in \mathbb{R}^{ N \times D }$
- Special SOS token: [E]
- Tokenizer init: from dVAE paper
- Masking strategy
- Blockwise masking (instead of random masking)
- For each block, we set the minimum number of patches to 16
- Randomly choose an aspect ratio for the masking block
- Repeat until we get $0.4N$ number of masked patches
- MIM Loss
- Randomly mask ~40% of image patches
- Replace with a learnable mask embedding $e_{[M]} \in \mathbb{R}^D$
- For each masked position, predict the original visual tokens with a softmax classifier after a linear projection on output embedding
MIM Loss:
\[\sum_{x \in \mathcal{D}} \mathbb{E}_{\mathcal{M}} \left[ \sum_{i \in \mathcal{M}} \log p_{MIM}( z_i | x^{\mathcal{M}} ) \right]\]where
- $\mathcal{M}$: masked token index set
- $\mathcal{D}$: training corpus
- $x^{\mathcal{M}}$: corrupted image patches
BEiT as Variational Autoencoder
- TBD
Optimization
- Pretrain BEIT on the training set of ImageNet-1K / 1.2M images
- Augmentation: random resized cropping, horizontal flipping, color jittering
- Batch size: 2k
- Training steps: 500k steps (i.e., 800 epochs) / 5 days on 16 V100
- Proper initialization is important to stabilize training (see paper Section 2.5)
Experiments
- Image Classification
- Follow DeiT hyperparameters on fine-tuning
- Large learning rate + layer-wise decay
- Pre-trained BEIT significantly improves performance
- Fine-tuning on pre-trained BEiT is ~5x more data efficient than training DeiT from scratch (see paper Figure 2)
- Semantic Segmentation
- ADE20K benchmark, 25K images, 150 semantic categories
- Task layer & hyperparameters: mostly follow SETR-PUP
- 160K steps / batch size 16
- Intermediate fine-tuning: first pre-train, then fine-tune on ImageNet, finally fine-tune on ADE20K
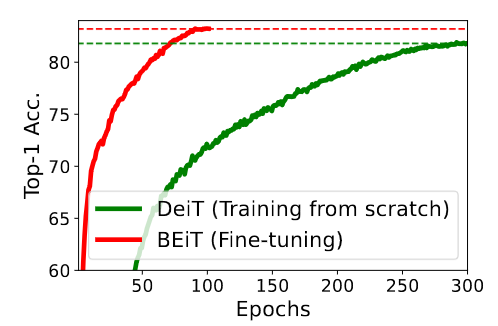
Convergence curves of training DeiT from scratch and fine-tuning BEIT on ImageNet-1K.

Semantic segmentation on ADE20K.
Self-Attention Map Analysis

Self-attention map for different reference points. Method: use the corresponding patch as query, and visualize which patch BEiT attends to. The self-attention mechanism in BEIT is able to separate objects, although self-supervised pre-training does not use manual annotations.