Layout Language Model
This post is mainly based on
- LayoutLM: Pre-training of Text and Layout for Document Image Understanding, SIGKDD 2020
- LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding, 2020
- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, 2021
- LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking, 2022
Why Visually-Rich Document Understanding is Hard?
- Relies on: not only textual information, but also visual and layout information
- Text style and format also convey information
- Hypothesis: textual, visual, and layout information should be jointly modeled and learned end-to-end in a single framework
Comparison of LayoutLMs
- LayoutLM
- 2-D absolute position embedding + Image embedding
- Image encoder: only fine-tuned on down stream task, not pre-trained
- Masked Visual-Language Model (MVLM) loss + Multi-label Document Classification (MDC) loss (similar to BERT)
- LayoutLMv2
- 2-D relative position embedding
- Image encoder: ResNeXt101-FPN, pre-trained
- New loss function: Text-Image Alignment Loss, Text-Image Matching Loss
- LayoutXLM
- Multilingual extension of LayoutLMv2
- LayoutLMv3
- Image encoder: Linear projection to visual embedding
- New loss function: Masked Image Modeling, Word-Patch Alignment Loss
LayoutLM
- 2-D position embedding
- Image embedding
- Masked Visual-Language Model (MVLM) loss
- SOTA
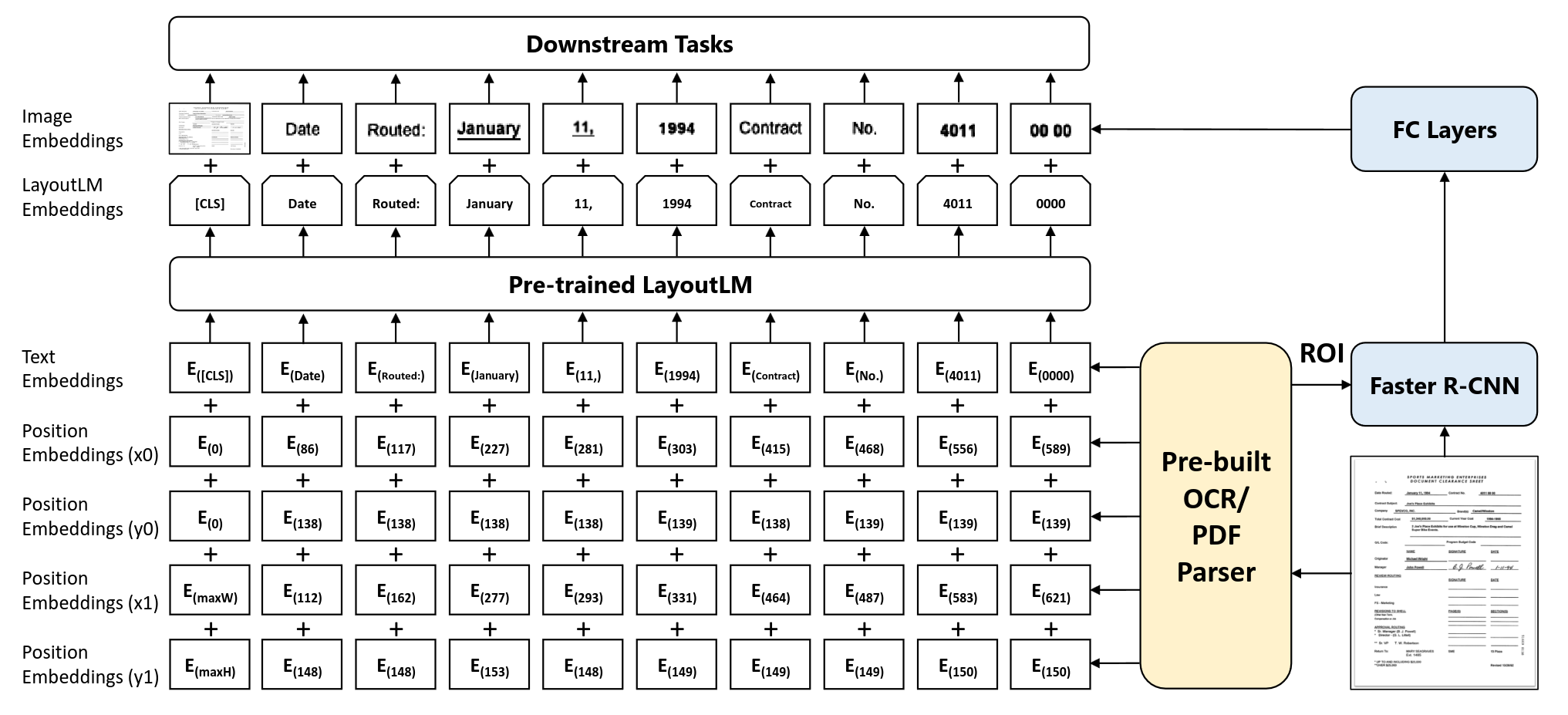
LayoutLM architecture. The Pre-built OCR extract: text, text position and text ROI. Text and text position are encoded by text encoder into LayoutLM embeddings. Text ROI is encoded by Faster R-CNN and FC layers into image embeddings. Text encoder is pre-trained. Image encoder can only be fine-tuned.
Architecture
- LLM Backbone: BERT
- BERT-base
- 12-layer
- 768 hidden sizes
- 12 attention heads
- ~113M parameters
- BERT-large
- Image embedding backbone: ResNet-101
- From Faster R-CNN pre-trained on the Visual Genome dataset
- Additional input embeddings
- 2-D position embedding: relative position of a token within a document
- Image embedding (fine-tuning only): scanned token images within a document
- Loss
- Masked Visual-Language Model (MVLM) loss
- Similar to Masked Language Model loss
- Mask the text embedding but keep positional embedding
- Predict masked token
- 15% of the input tokens for prediction
- Multi-label Document Classification (MDC) loss
- Masked Visual-Language Model (MVLM) loss
- Optimization
- 8 NVIDIA Tesla V100 32GB GPUs
- Batch size: 80
- Adam, lr=5e-5, linear decay
- BASE model: 80 hours to finish one epoch on 11M documents
Pre-training Dataset
- IIT-CDIP Test Collection 1.0
- [Building a Test Collection for Complex Document Information Processing, 2006]
- 6 million scanned documents
- Pre-processing
- Tesseract: obtain the recognition as well as the 2-D positions
- Store the OCR results in hOCR format (OCR + hierarchical representation)
Benchmark Dataset
- FUNSD
- Spatial layout analysis and form understanding
- SROIE
- Scanned Receipts Information Extraction
- RVL-CDIP
- Document image classification
Ablation
MVLM vs MVLM+MDC
- MVLM+MDC only performs marginal better than MVLM
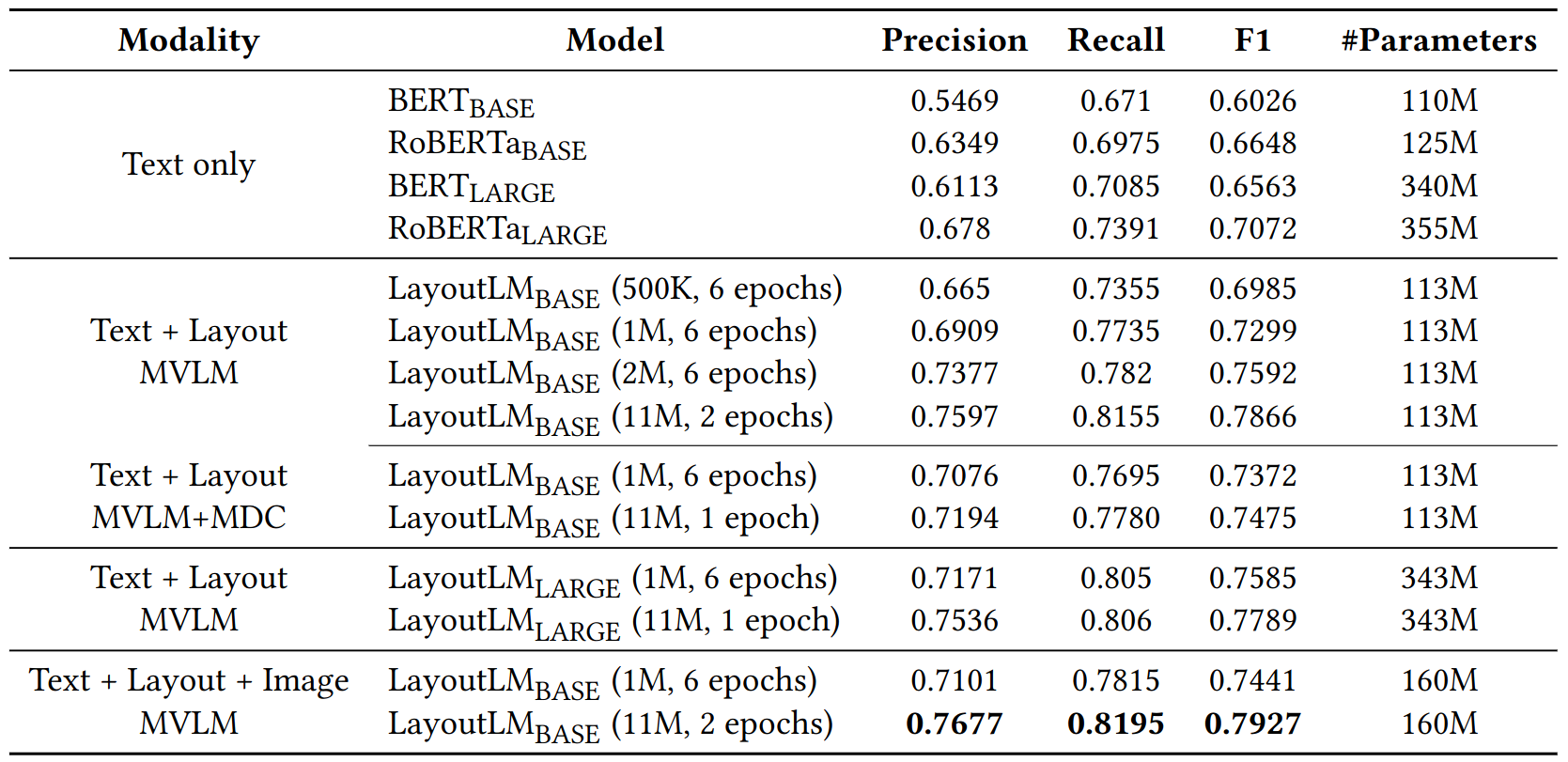
Model accuracy (Precision, Recall, F1) on the FUNSD dataset.
Different initialization of BERT
- Initialization has large impact
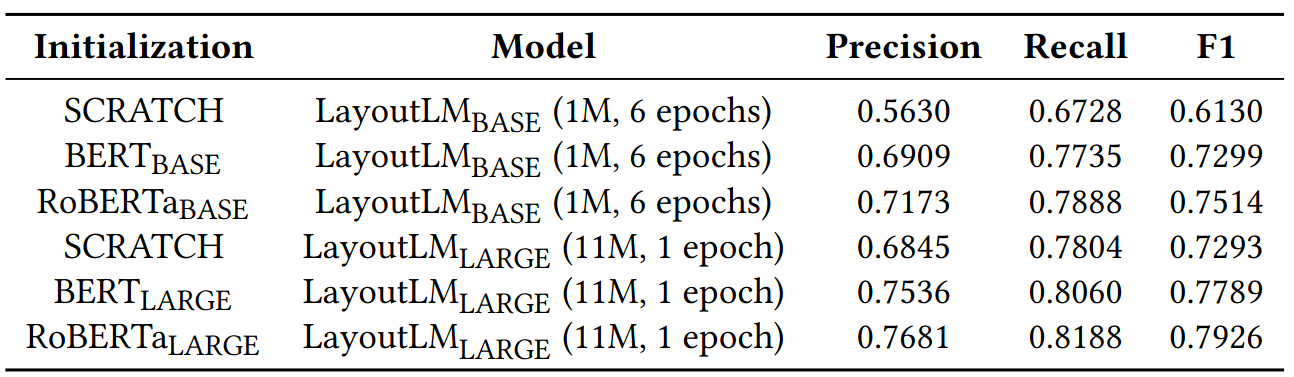
Different initialization methods for BASE and LARGE (Text + Layout, MVLM).
LayoutLMv2
- Spatial-Aware SelfAttention Mechanism: attention score $\alpha$ is modified by learnable bias
- Image encoder in pre-training + 2 new pre-training loss
- Significantly outperforms SOTA / LayoutLM
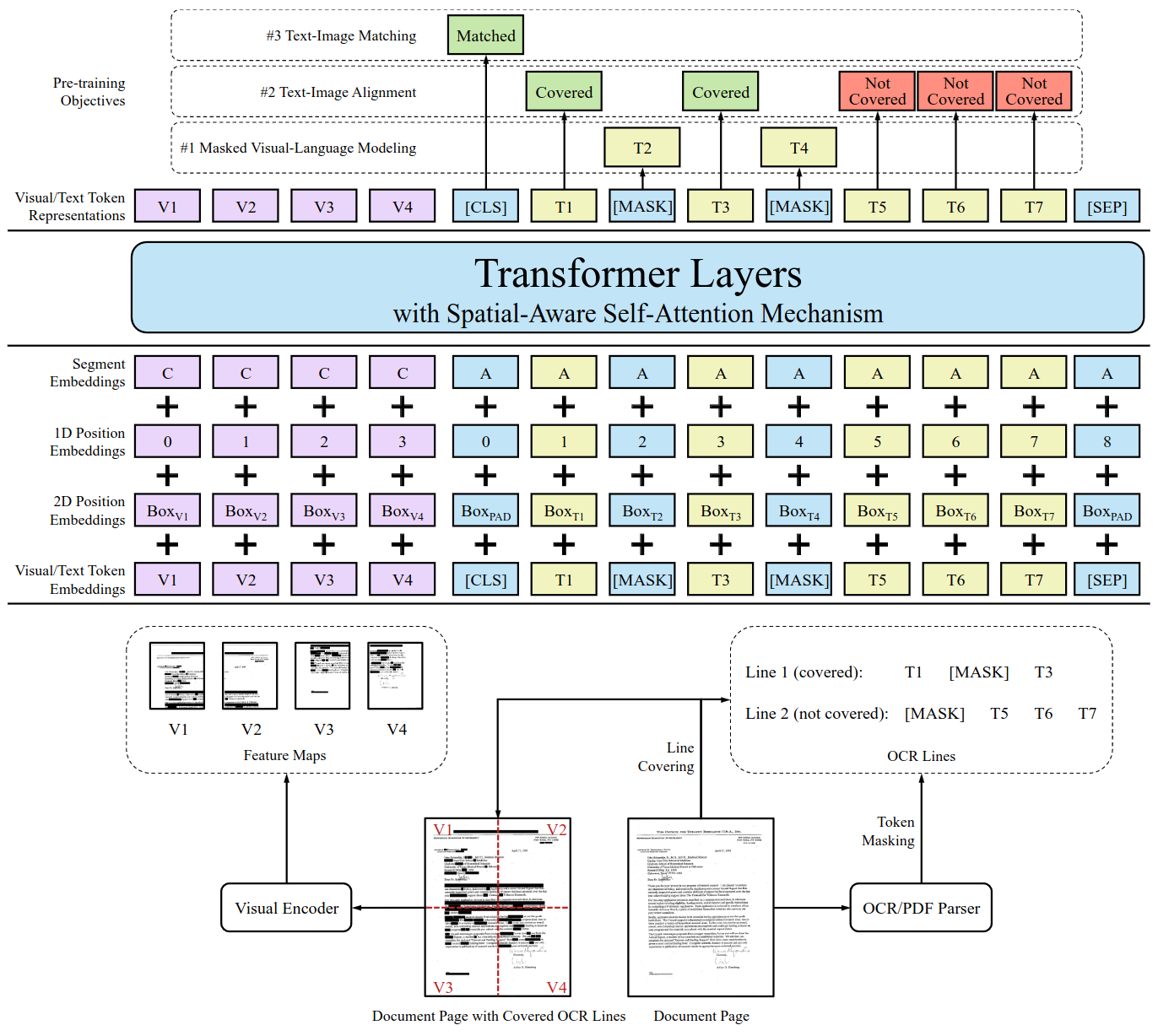
LayoutLMv2 architecture. Visual Encoder encoder patches into visual embedding. Visual Token Embeddings and Text Token Embeddings have same dimensions. Transformer Layers, text embedding and visual encoder are jointly pre-trained.
Architecture
- Text Embedding
- Token embedding $TokEmb(w_i)$
- 1D positional embedding $PosEmb1D(i)$: token index
- Segment embedding $SegEmb(s_i)$: distinguish different text segments
- $t_i = TokEmb(w_i) + PosEmb1D(i) + SegEmb(s_i)$
- Visual Embedding
- Converts the page image $I$ into a 224 x 224 fixed-length sequence
- Backbone CNN: ResNeXt-FPN
- Output feature map is average-pooled to dimension W x H (e.g., 2 x 2), then flattened into $VisTokEmb(I)$
- $VisTokEmb(I)$ is then projected into dimensionality of the text embeddings
- Also have 1D positional embedding and Segment embedding to indicate its location
- $v_i = Proj(VisTokEmb(I)_i)+PosEmb1D(i)+SegEmb([C])$
- $0 \leq i < WH$
- Layout Embedding
- Spatial layout information represented by axis-aligned token bounding boxes from the OCR result
- Normalize and discretize all coordinates to integers in the range [0, 1000]
- $l_i = Concat(PosEmb2D_x(x_{min}, x_{max}, width), PosEmb2D_y(y_{min}, y_{max}, height))$
- Combine
- Concatenates visual embeddings and text embeddings
- $X = { v_0, …, v_{WH−1}, t_0, …, t_{L−1} }$
- Spatial-Aware Self-Attention
- Let $\alpha_{ij}$ be the vanilla attention score between $x_i, x_j$
- $\alpha’{ij} = \alpha{ij} + b_{j-i}^{(1D)} + b_{x_j-x_i}^{(2D_x)} + b_{y_j-y_i}^{(2D_y)}$
- bias $b$ are learnable
Loss
- Masked Visual-Language Model (MVLM) Loss
- Same as LayoutLMv1 except mask OCR detected token region before pass to image encoder
- Text-Image Alignment (TIA) Loss
- Covering: some tokens lines are randomly selected, and their image regions are covered on the document image; covering operation is performed at the line-level
- Pre-training: a classification layer is built above the encoder outputs; for each token, predict if it is covered ([Covered] or [Not Covered], BCE loss)
- When MVLM and TIA are performed simultaneously, TIA losses of the tokens masked in MVLM are not taken into account (Due to [MASK] => [Covered])
- Text-Image Matching (TIM) Loss
- Feed the output representation at [CLS] into a classifier to predict whether the image and text are from the same document page (BCE loss)
- Positive samples: matched text-image
- Negative samples: image replaced by a page image from another document or dropped
- Perform the same masking and covering operations to images in negative samples to prevent the model from cheating by finding task features
Pre-training
- IIT-CDIP Test Collection
- Random sliding window of the text sequence if the sample is too long
- Maximum sequence length L = 512 and assign all text tokens to the segment [A]
- Output shape of the image encoder average pooling layer: W = H = 7 (49 tokens)
- Text encoder
- Architecture: BERT BASE or BERT LARGE
- Init: UniLMv2
- Image encoder
- Architecture: ResNeXt101-FPN
- 200M and 426M parameters due to different projection layers
- Init: Mask R-CNN trained from PubLayNet
- Loss
- MVLM: 15% masked (80% [Mask], 10% random, 10% unchange)
- TIA: 15% of the lines are covered
- TIM: 15% images are replaced, and 5% are dropped
Results
- Fine-tuning: task dependent fine-tuning, but limited by BERT architecture
- Baseline: text-only pre-trained models, LayoutLM
- Backbone: BERT Base & Large
- LayoutLMv2 outperforms baseline by a large margin / new SOTA on downstream tasks
Benchmark Dataset
- Form understanding: FUNSD
- Receipt understanding: CORD, SROIE
- Long document with a complex layout: Kleister-NDA
- Document image classification: RVL-CDIP
- Visual question answering: DocVQA
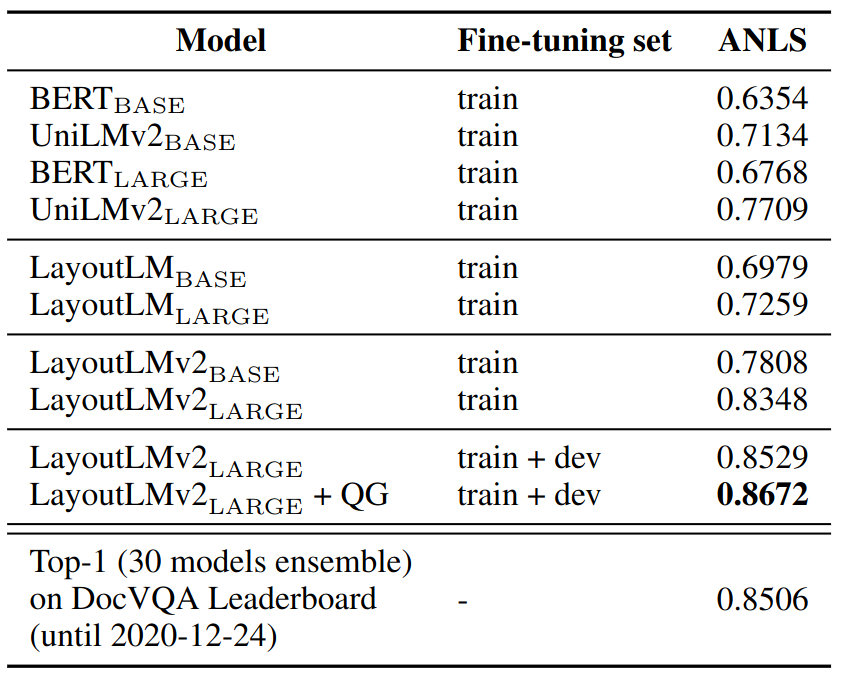
ANLS score on the DocVQA dataset, “QG” denotes the data augmentation with the question generation dataset.
Ablation

Ablation study on the DocVQA dataset, where ANLS scores on the validation set are reported. “SASAM” means the spatial-aware self-attention mechanism. “MVLM”, “TIA” and “TIM” are the three pre-training tasks. All the models are trained using the whole pre-training dataset for one epoch with the BASE model size.
Comments: ANLS of line 6 model in Table 5 doesn’t match ANLS of line 7 model in Table 4, which I believe to be the same model. Not sure why.
LayoutLMv3
- Pre-train multimodal Transformers with unified text and image masking
- Word-patch alignment objective: for cross-modal alignment learning
- SOTA on both text-centric and image-centric tasks
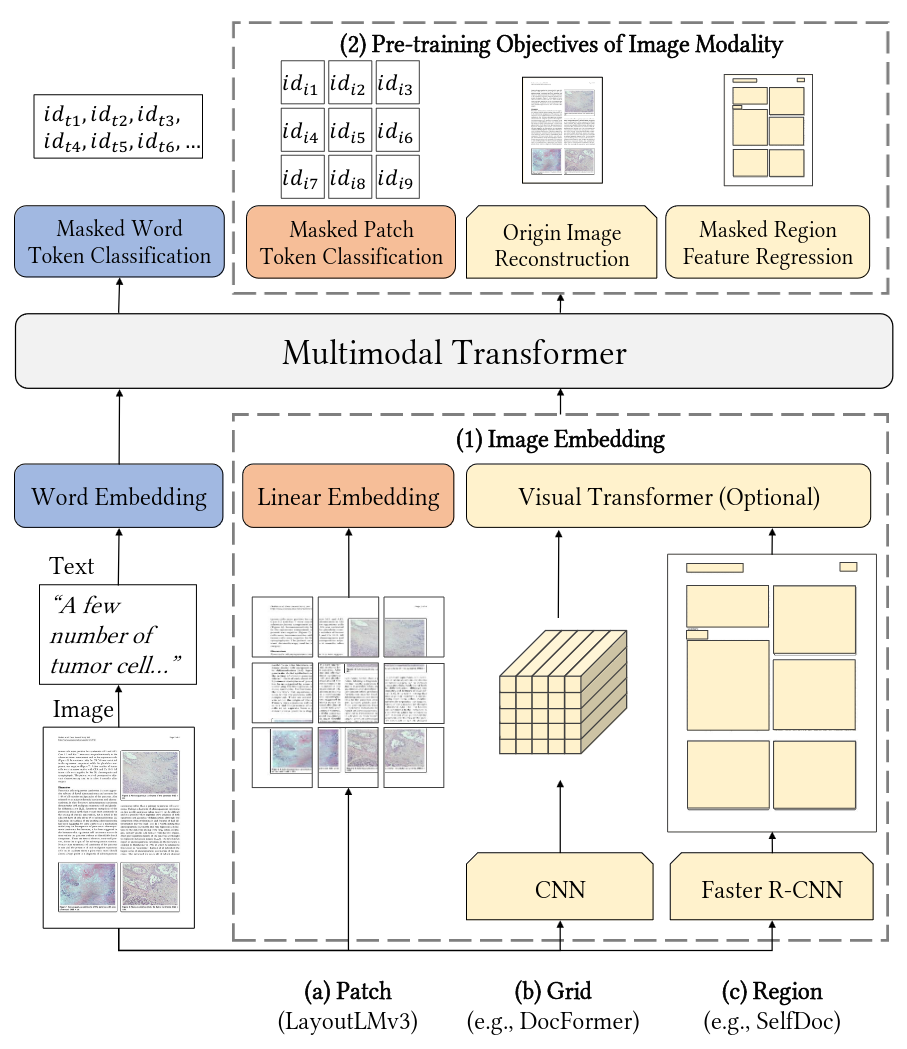
LayoutLMv3 vs DocFormer vs SelfDoc. Image embedding: linear patches reduce computational complexity. Image pre-training objectives: reconstruct image tokens instead of raw pixels or region features, capture high-level structures.
Architecture
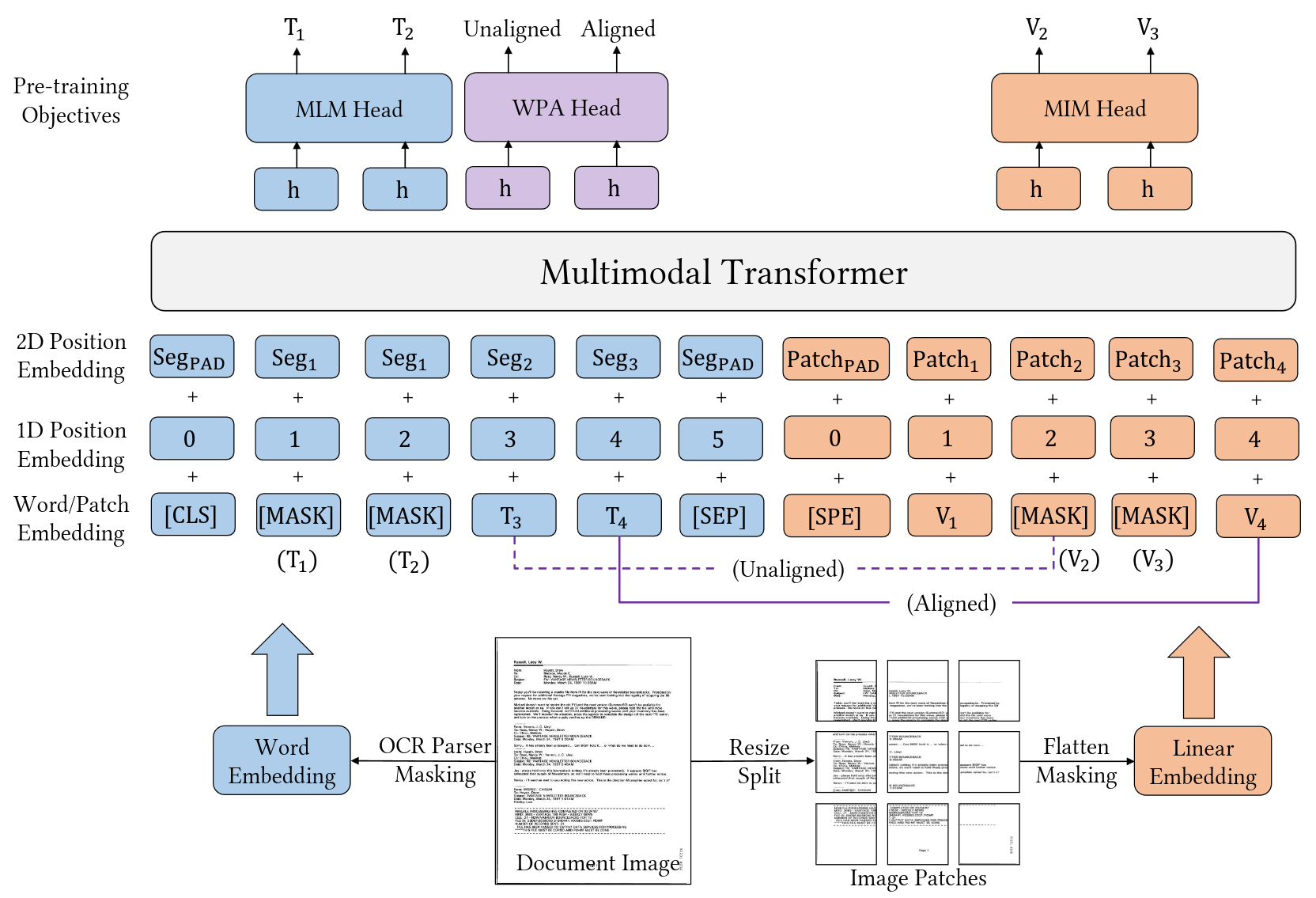
- Text embedding: $Y = y_{1:L}$
- OCR: text + bounding box
- Position embeddings: 1D position + 2D layout position
- Modification to 2D layout position embedding
- LayoutLM and LayoutLMv2: word-level layout position
- LayoutLMv3: segment-level layout positions (words in same segment usually express the same semantic meaning)
- Image embedding: $X = x_{1:M}$
- Linear Image Patches inspired by ViT and ViLT
- First multimodal pre-trained Document AI model without CNNs backbone as image encoder
- Reduce heavy computation bottleneck and remove the need for region supervision
- $I \in \mathbb{R}^{C \times H \times W}$ (channel size, width and height)
- Split the image into a sequence of uniform $P \times P$ patches
- Linearly project the image patches to $D$ dimensions, then flatten
- Length $M = HW/P^2$
- Learnable 1D position embeddings
Loss
- Masked Language Modeling (MLM)
- Mask 30% of text tokens with Span masking strategy
- Span lengths drawn from a Poisson distribution $\lambda = 3$
- Input include both image tokens $X$ and text tokens $Y$
- Masked Image Modeling (MIM)
- MIM pre-training objective in BEiT
- Mask 40% image tokens with the blockwise masking strategy
- Cross-entropy loss to reconstruct the masked image tokens based on surrounding text and image tokens
- Word-Patch Alignment (WPA)
- Since each word corresponds to an image patch, the goal is to learn the cross-modal alignment
- WPA objective
- Predict whether the corresponding image patches of a text word are masked
- Aligned: for an unmasked text token, corresponding image tokens are also unmasked
- Unaligned: for an unmasked text token, corresponding image tokens are masked
- Exclude the masked text tokens when calculating WPA loss
- Classification head: two-layer MLP, binary cross-entropy loss
Pre-training
- Tokenizer: BPE, with Max sequence length $L = 512$
- BERT Base or Large, init by DiT
- Image preproc
- $C \times H \times W = 3 \times 224 \times 224$, $P = 16$, $M = 196$
- Image encoder
- Init by RoBERTa
- Image tokens vocabulary size: 8192
- Optimizer
- Adam, batch size of 2048, 500000 steps
- Lr: BERT Base = $1e-4$, BERT Large = $5e-5$
- Distributed mixed-precision training + gradient accumulation + gradient checkpoint
- Modified softmax computation follow CogView, to stabilize training
- Dataset: IITCDIP Test Collection 1.0 (11 million docs, 42 million pages)
Results
Benchmark Dataset
- Form understanding: FUNSD
- Receipt understanding: CORD
- Visual question answering: DocVQA
- Document image classification: RVL-CDIP
- Document layout analysis: PubLayNet
Layout Parsing
- Use LayoutLMv3 as feature backbone in the Cascade R-CNN detector with FPN implemented using the Detectron2
- Extract single-scale features from layers 4, 6, 8, and 12 of the LayoutLMv3 base
- Resolution-modifying modules: convert the single-scale features into the multiscale FPN features
- PubLayNet: 335703 training, 11245 validation, and 11405 testing images
- Detailed fine-tuning config see paper Section 3.4
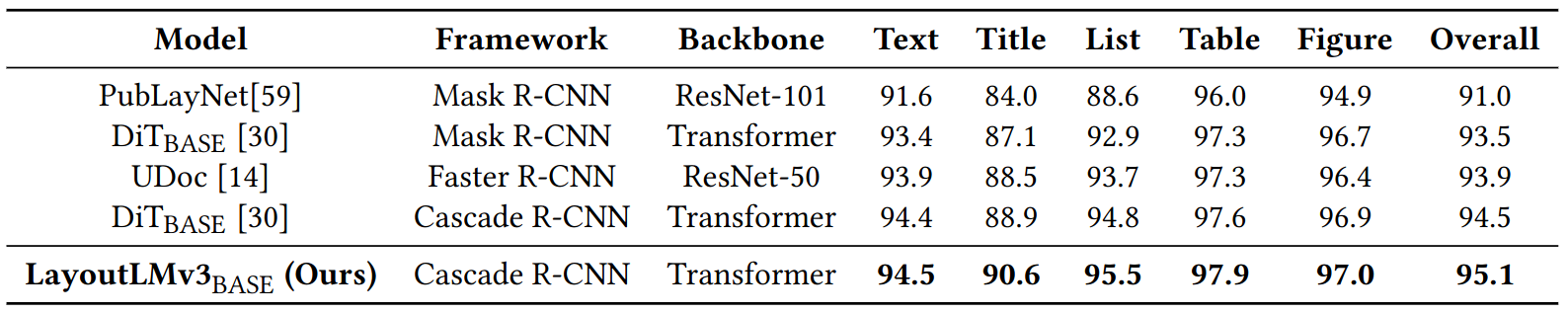
Document layout analysis mAP @ IOU [0.50:0.95] on PubLayNet validation set. All models use only information from the vision modality. LayoutLMv3 outperforms the compared ResNets and vision Transformer backbones.
Ablation Study
- MLM head
- 39.2M params
- Vocabulary size: 50265
- Benefit of Image Embedding on Text centric tasks are surprising low
- However, the authors argue that
- Computation overhead of image encoder is also low
- Linear: 0.6M params; ResNet-101: 44M params
- Note that $M=196$ increase input sequence length for transformer, this leads to increased computation
- However, the authors argue that
- MIM loss may assist learning features for Image centric tasks
- 6.9M params
- WPA loss leads to marginal improvements across all tasks
- 0.6M params
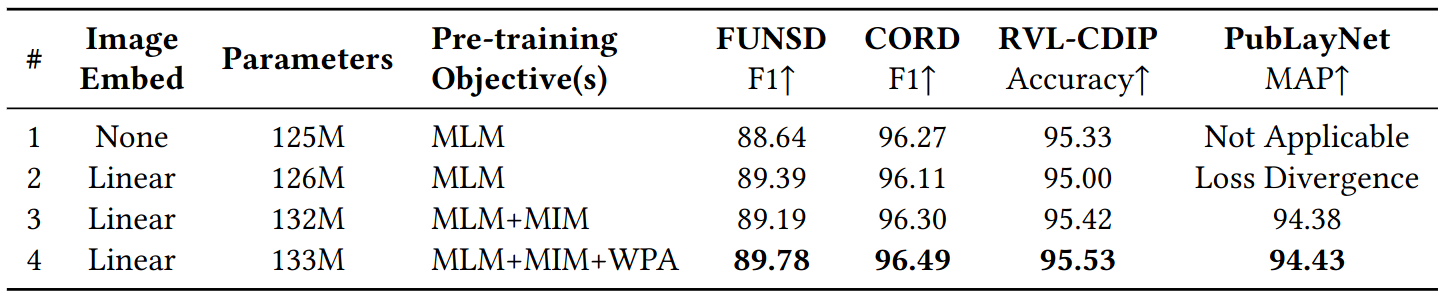
Ablation study on image embeddings and pre-training objectives on typical text-centric tasks (form and receipt understanding on FUNSD and CORD) and image-centric tasks (document image classification on RVL-CDIP and document layout analysis on PubLayNet). All models were trained at BASE size on 1 million data for 150,000 steps with learning rate 3e-4.