Vision Language Pre-Training
This post is mainly based on
CLIP
- Representation Learning: predicting caption-image pair is a scalable way to learn SOTA image representations
- 400 million (image, text) pairs dataset collected from the internet
- Natural language based zero-shot transfer to downstream tasks
- Results
- Evaluation on over 30 benchmarks, including: OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification
- Transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without fine-tuning
- Match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training
What is CLIP?
- Contrastive pre-training: jointly trains an image encoder and a text encoder to predict the correct (image, text) pair within each batch
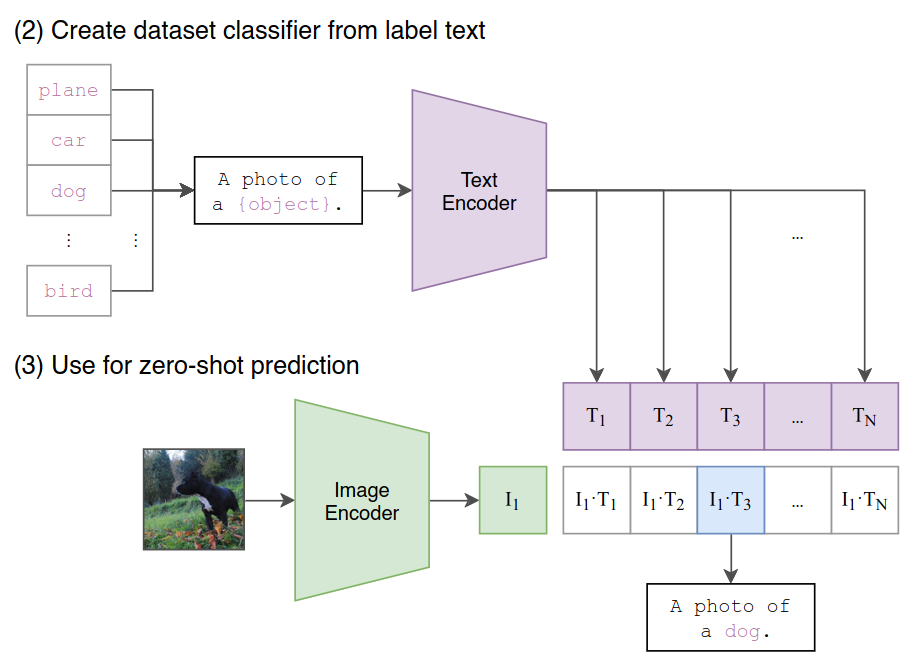
- Create dataset classifier from label text: convert classification labels to descriptive sentences
- Use for zero-shot prediction: select the class with highest logits
Background
- Previous work focus on weak supervision
- Learning from ImageNet-related hashtags
- Learning from a noisy JFT-300M dataset
- These methods navigates a trade-off between: learning image representation from
- A limited amount of supervised “golden-labels”
- Practically unlimited amounts of raw text
- However, their prediction is limited to 1000 and 18291 classes
Overview
- Collect a new dataset of 400 million (image, text) pairs
- Design CLIP Architecture (simplified ConVIRT)
- Study scalability of CLIP: observe that model transfer performance is a smoothly predictable function of compute
- Study zero-shot performance on over 30 Benchmarks
- Conduct linear-probe representation learning analysis: CLIP embedding outperforms SOTA while also being more computationally efficient
Approach
- Natural language can be used as a training signal for image representation
- Much easier to scale natural language supervision compared to crowd-sourced labeling
- Apart from learning the representation, it also connects the representation to language which enables flexible zero-shot transfer
- WebImageText dataset
- Common words: all words occurring at least 100 times in the English Wikipedia
- Construction 500,000 queries from common words
- Class balance: including up to 20,000 (image, text) pairs per query
- Total word count: ~ GPT-2 WebText dataset
Efficient training
- Previous approach
- ResNeXt101-32x48d: 19 GPU years
- EfficientNet-L2: 33 TPUv3 years
- both these systems were trained to predict only 1000 ImageNet classes
- Our approach
- Baseline: Bag of Words Prediction
- CNN learns to predict a bag-of-words encoding of the text
- Transformer Language Model
- Training 63 million parameter text transformer + ResNet-50 from scratch to predict the caption of an image
- Transformer uses twice the compute of CNN
- Learns to recognize ImageNet classes three times slower than Baseline
- Problems of the above approaches
- Trying to predict the exact words of the text accompanying each image is unnecessarily hard and prone to overfit (similar to predict each pixels in image generation)
- Contrastive Multiview Coding, 2019: contrastive objectives can learn better representations than their equivalent predictive objective
- Generative pretraining from pixels, ICML 2020: generative model require over an order of magnitude more compute than contrastive models to learn similar quality of representation
- Bag of Words Contrastive (CLIP)
- Inspired by contrastive learning
- Predict sentense as a whole, rather than exact individual words
- 4x efficiency improvement compared to baseline
- Baseline: Bag of Words Prediction
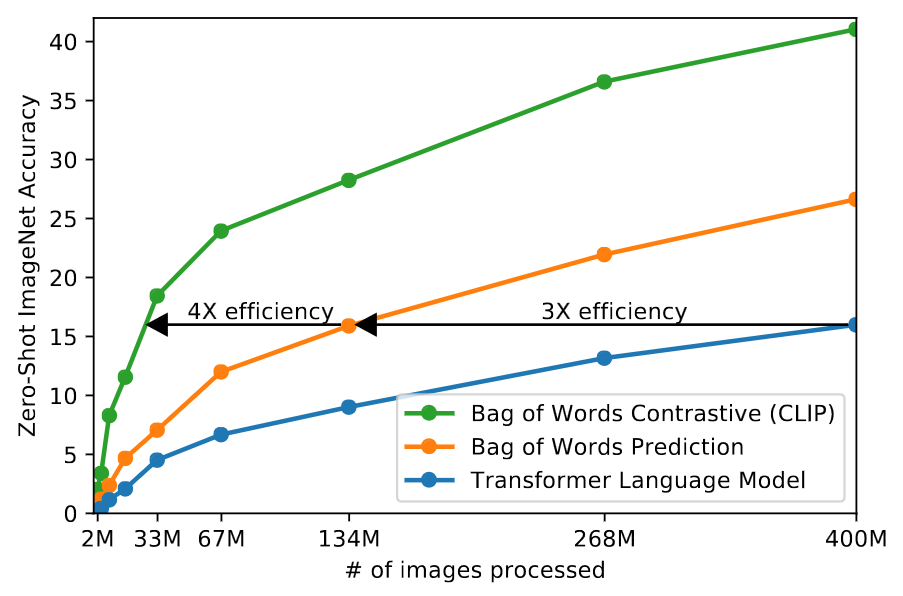
CLIP is much more efficient at zero-shot transfer than our image caption baseline. Blue: transformer-based language models learns 3x slower than the baseline (predicts a bag-of-words encoding of the text). Green: CLIP learns 3x faster than the baseline.
Architecture
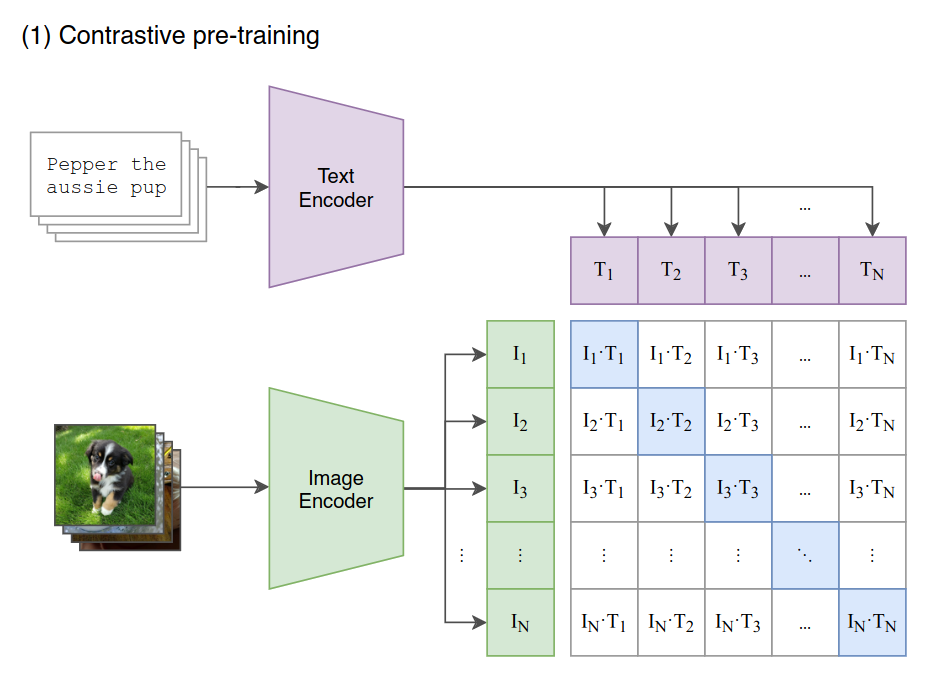
- Overview
- Given a batch of N (image, text) pairs
- Predict which of the $N \times N$ possible (image, text) pairings across a batch actually occurred
- CLIP learns a multi-modal embedding space by
- Jointly training an image encoder and text encoder
- Maximize the cosine similarity of the image embeddings and text embeddings of the N real pairs
- Minimizing the cosine similarity of the embeddings of the $N^2 − N$ incorrect pairings
- Pseudocode
- Paper Figure-3
- Encode a batch of image and text into 2 dimension $[n, d_i], [n, d_t]$ matrices using image and text encoder
- Map and normalize $[n, d_i], [n, d_t]$ into joint 2 multimodal embeddings of dim $[n, d_e]$ using a linear projection
- Compute pairwise similarity matrix $[n,n]$
- Compute loss in 2 axis direction
- Image encoder
- ResNet-50 + attention pooling
- ViT, with additional layer normalization and different initialization scheme
- Text encoder
- Embedding layer: BPE, 49152 vocab size
- Max sequence length: 76 (for efficiency)
- Special tokens: [SOS], [EOS]
- Base: 12-layer, 512-dim, 8-attention head, 63M-parameter
- Masked self-attention (can be init from a decoder LLM or add LML as auxiliary loss)
Optimization
- Train from scratch without initializing the image encoder or the text encoder
- Loss
- Cross entropy loss over these similarity scores
- Weight decay regularization to all weights that are not gains or biases
- Clip logits < 100 for stability
- Optimizer
- Adam
- Cosine learning rate decay
- Hyperparams
- Data augmentation: random square crop
- Softmax temperature parameter $\tau$ is directly optimized during training, init to 0.07
- Init: grid searches, random search, and manual tuning
- Mixed Precision Training
- Gradient checkpointing
- Half-precision Adam statistics
- Half-precision stochastically rounded text encoder weights
- Distributed Training
- Batch size: 32,768
- Embed similarity: only the subset of the pairwise similarities necessary for their local batch of embeddings
Ablations
- Image encoder
- 5 ResNets
- ResNet-50, ResNet-101
- RN50x4, RN50x16, RN50x64 (EfficientNet-style model scaling, using ~4x, 16x, and 64x the compute of a ResNet-50)
- RN50x64: 592 V100 GPUs, 18 days
- 3 Vision Transformers
- ViT-B/32, a ViT-B/16, and a ViT-L/14
- ViT-L/14: 256 V100 GPUs, 12 days
- ViT-L/14@336px: pre-train at a higher 336 pixel resolution for one additional epoch to boost performance
- 5 ResNets
- Text encoder
- Findings: CLIP’s performance is less sensitive to the capacity of the text encoder
- Train all models for 32 epochs
Experiments: Zero-Shot Transfer
- Problems of existing benchmarks
- Research benchmarks focus on synthetic problems, rather measuring performance on a specific task
- SVHN dataset: measures the task of street number transcription on the distribution of Google Street View photos
- CIFAR-10: unclear what “real” task the dataset measures
- When we evaluate zero-shot transfer of CLIP on CIFAR-10, it is more of an evaluation of CLIP’s robustness to distribution shift and domain generalization rather than task generalization
- CLIP on zero-shot classification
- Reuse ability learned in pre-training
- A batch of $n$ (image, text) pairs, where text is names of classes in the dataset, predict highest logit score
- Alternative view: comparing cosine-similarity of the image embedding vs $n$ text embeddings
- Text embedding of the $n$ classes only need to be computed once
- Image embedding need to be computed $1$ time for each image
- Results
- Improves accuracy on ImageNet from a proof of concept of 11.5% to 76.2%
- Top-1 accuracy 76.2%: matches the performance of the original ResNet-50 (without using 1.28 million labels)
- Top-5 accuracy 95%: matches the performance of Inception-V4
- Prompt engineering and ensemble
- Improve ImageNet accuracy by almost 5%, which is equivalent to 4x efficiency gain
- For details, see Section 3.1.4
- Performance Anlaysis on 27 datasets
- CLIP outperforms ResNet-50 on 16/27
- CLIP underperforms on specialized, complex, or abstract tasks
- Satellite image classification (EuroSAT and RESISC45)
- Lymph node tumor detection (PatchCamelyon)
- Counting objects in synthetic scenes (CLEVRCounts)
- Self-driving related tasks such as German traffic sign recognition (GTSRB)
- Recognizing distance to the nearest car (KITTI Distance)
- Zero-shot performance is correlated with linear probe performance but still mostly sub-optimal
- See paper Figure-8
Comparing zero-shot transfer image classification results of CLIP vs Visual N-Grams (proof of concept on zero-shot transfer).
Few-shot Linear Probe
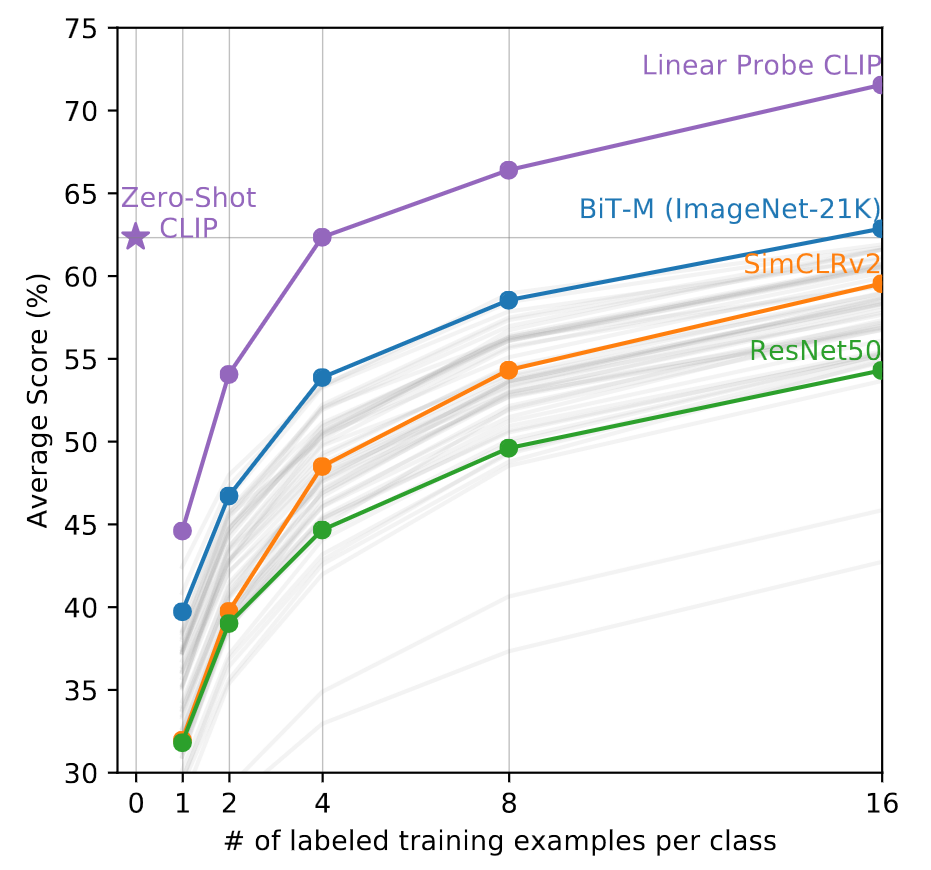
Zero-shot CLIP matches the average performance of a 4-shot linear classifier trained on the same feature space and nearly matches the best results of a 16-shot linear classifier across publicly available models. The 20 datasets with at least 16 examples per class were used in this analysis.
Scaling Law
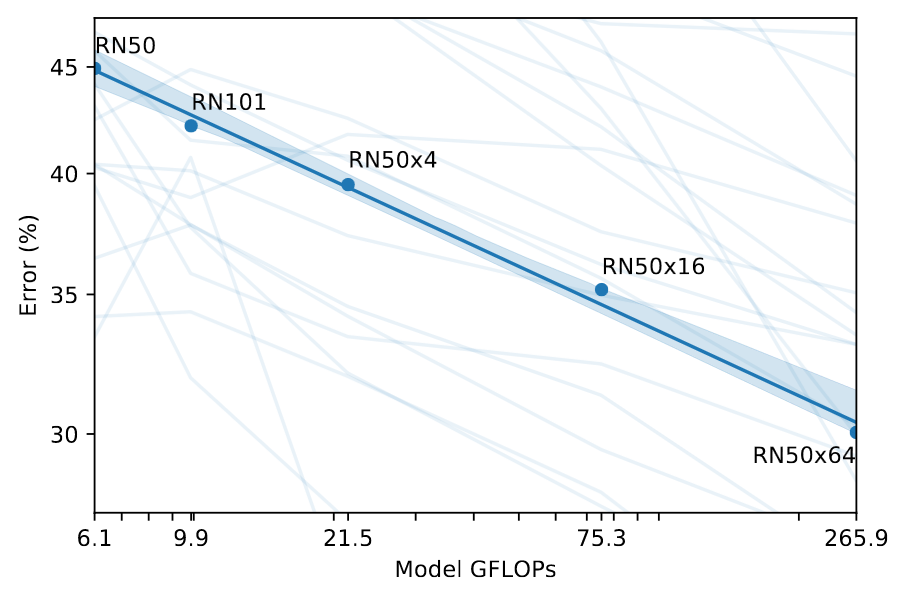
Zero-shot CLIP performance scales smoothly as a function of model compute. Across 39 evals on 36 different datasets, average zero-shot error is well modeled by a log-log linear trend across a 44x range of compute spanning 5 different CLIP models.
Representation Learning
- Scale of experiments: 66 different models on 27 different datasets requires tuning 1782 different evaluations
- Conclusions
- All CLIP models, regardless of scale, outperform all evaluated systems in terms of compute efficiency
- CLIP-Vit are about 3x more compute efficient than CLIP-ResNets
- CLIP’s features outperform the features of the best ImageNet model on a wide variety of datasets (paper Figure-11)
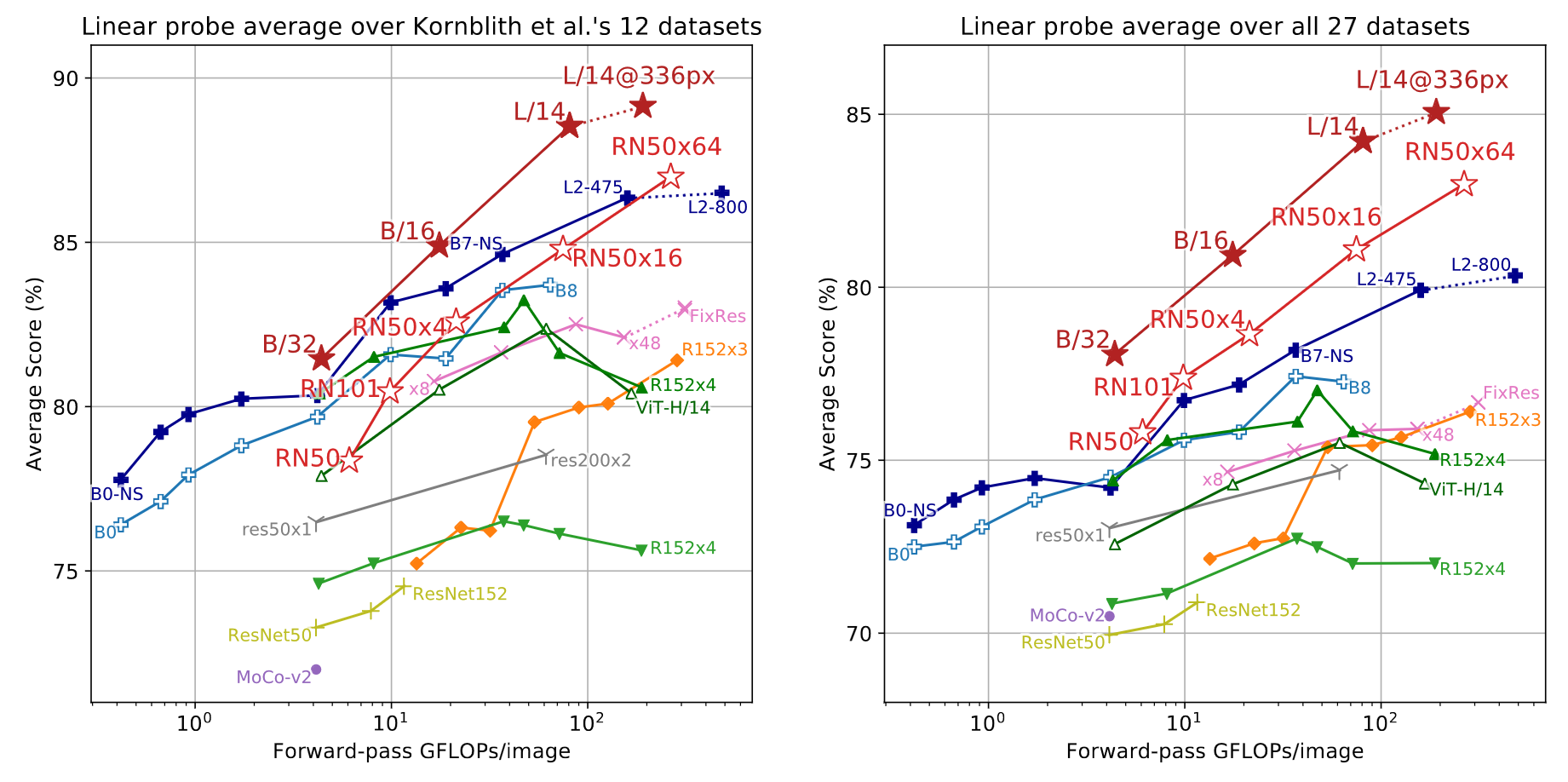
Linear probe performance of CLIP models in comparison with state-of-the-art computer vision models.
Performance of linear probe on learned representation. CLIP scale very well on large models.
Robustness to Natural Distribution Shift
- Natural distribution shifts datasets: ImageNet Sketch, ImageNet Adversarial, etc. (See example below)
- ResNet-101 makes 5x more mistakes when evaluated on these natural distribution shifts compared to the ImageNet validation set
- All zero-shot CLIP models improve effective robustness by a large amount and reduce the size of the gap between ImageNet accuracy and accuracy under distribution shift by up to 75%
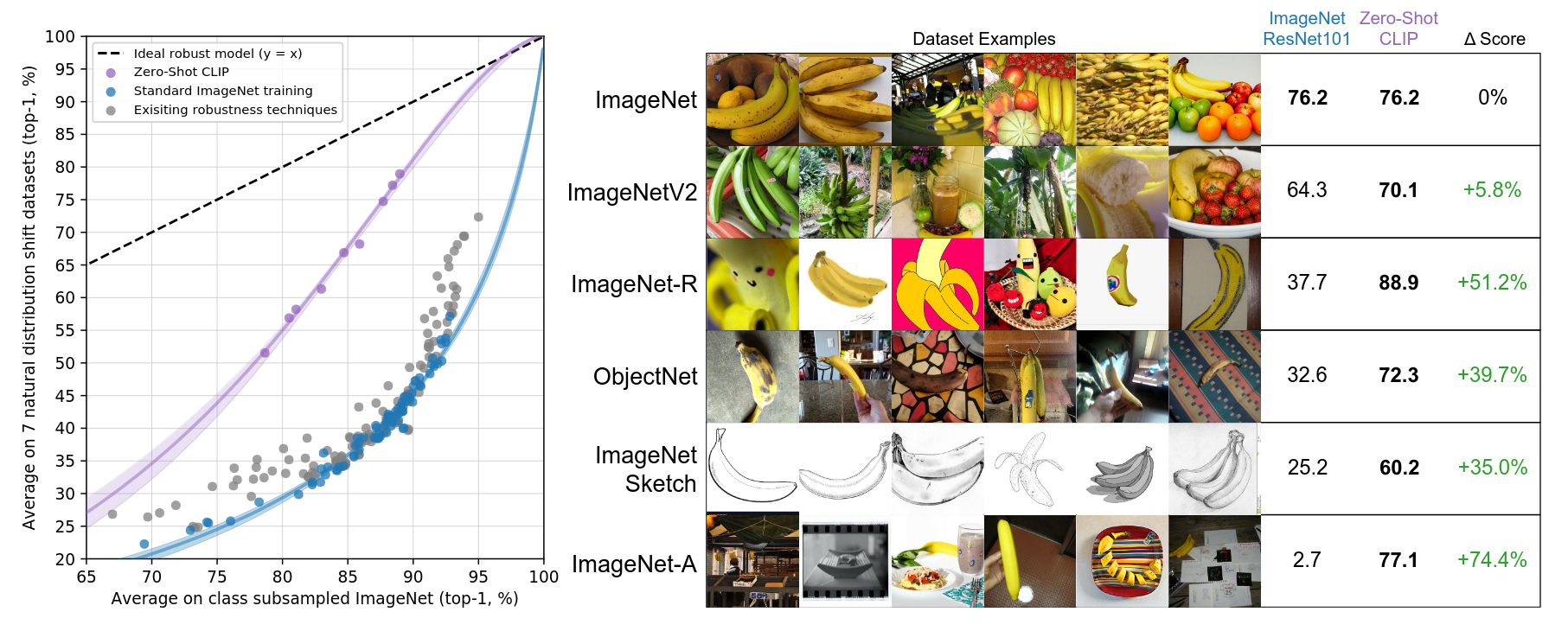
Zero-shot CLIP is much more robust to distribution shift than standard ImageNet models. Left: quantifying CLIP’s robustness gap against ImageNet trained model. Right: Visualizing distribution shift for bananas.
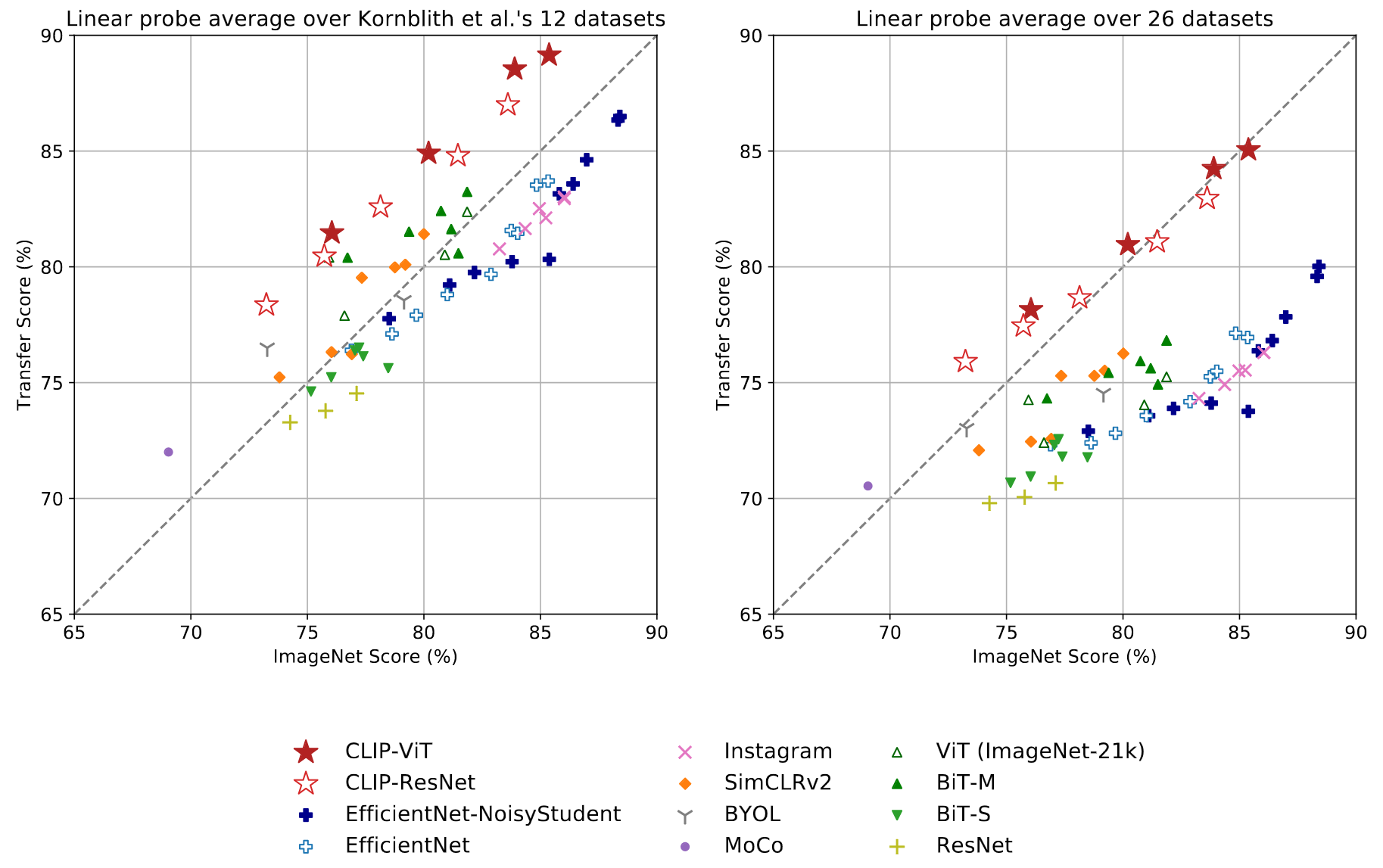
CLIP’s features are more robust to task shift when compared to models pre-trained on ImageNet. This suggests that the representations of models trained on ImageNet are somewhat overfit to their task.
Data Overlap Analysis
- See paper Section 5
Limitations
- Performance
- While CLIP is competitive against ResNet-50, it is well behind supervised SOTA
- Still needed to improve the data efficiency of CLIP, for better the task learning and transfer capabilities
- 1000x increase in compute is required for zero-shot CLIP to reach overall SOTA performance
- Robustness
- CLIP generalizes poorly to data that is truly out-of-distribution (e.g., OCR, MNIST)
- See paper Appendix E and Table 14
- This suggests CLIP does little to address the underlying problem of brittle generalization of deep learning models.
- Instead CLIP tries to circumvent the problem and hopes that by training on such a large and varied dataset that all data will be effectively in-distribution.
- Efficiency
- CLIP also does not address the poor data efficiency of deep learning.
- Instead CLIP compensates by using a source of supervision that can be scaled to hundreds of millions of training examples.
- Methodology limitations
- Repeatedly queried performance on full validation sets to guide the development of CLIP (against the goal of zero-shot transfer)
- Selection of evaluation datasets: lack of a benchmark task set
- Social biases: due to adopting training data from internet