Text Embeddings I
This post is mainly based on
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, 2019
- SimCSE: Simple Contrastive Learning of Sentence Embeddings, 2021
- Text and Code Embeddings by Contrastive Pre-Training, 2022
- Embedding Model Implementations: SentenceTransformers
Text Embeddings can be used for
- Sentence Similarity: e.g., Semantic Textual Similarity Dataset, STS-16
- Information Extraction: e.g., MSMARCO
Research on Sentence Similarity and Search/Information Extraction used to be separated: previous embedding search methods do not report performance on sentence similarity tasks, and previous sentence embedding methods do not evaluate on search tasks. While the 2 task appears to have connections, they might have contradicting definitions: A sentence and its negation could be considered as relevant during search, but not “similar” in sentence similarity tasks.
Sentence-BERT
- Goal: train compute efficient network to output sentence embedding
- Dataset: NLI dataset (entailment, neutral, and contradiction sentence)
- Supervise training from BERT
- Loss: triplet loss / cross entropy loss / MSE loss (cosine)
- Result: significantly outperform SOTA on 7 STS tasks
- +11.7 vs InferSent (siamese BiLSTM network with max-pooling over the output, trained on SNLI)
- +5.5 vs Universal Sentence Encoder (transformer + unsupervised learning, trained on SNLI)
Previous approach
- Compute inefficient
- BERT and RoBERTa can perform sentence-pair regression tasks, e.g., semantic textual similarity (STS)
- However, each comparison requires feeding sentence pair into the network / computational expensive
- Pooling
- Average the BERT output layer (BERT embeddings for each tokens) or by using the output of the first token (the [CLS] token)
- Yields rather bad sentence embeddings, often worse than averaging GloVe embeddings
- Training: does not initialize from pre-trained network
Dataset
- Stanford Natural Language Inference dataset (SNLI): 570,000 sentence pairs annotated with the labels contradiction, entailment, and neutral
- Multi-Genre NLI (MultiNLI): 430,000 sentence pairs and covers a range of genres of spoken and written text
Architecture
- Pooling layer over BERT embedding
- Ablation on 3 designs
- CLS-token
- MEAN-strategy: mean over all embeddings [Default]
- MAX-strategy: max over all embeddings
- Siamese Network vs Triplet Network: usage depending on training data
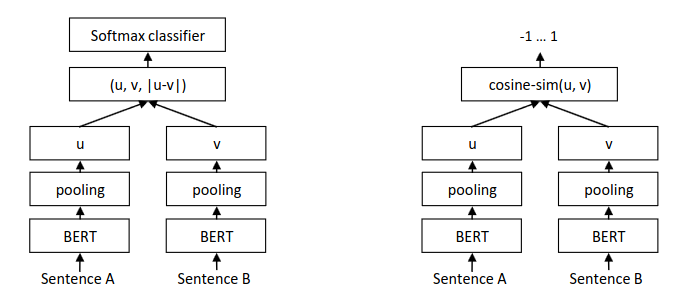
Left: architecture and type I loss (linear probe loss) in training. Right: similarity computation in inference.
Optimization
- Pre-trained BERT and RoBERTa network
- Fine-tuned in <20 minutes
- Optimizer: Adam
- Lr: 2e-5
- Warm-up: linear learning rate over 10% of the training data
- Batch-size: 16
Loss Functions
- Type I loss: Siamese Network + Classification Loss
- Trained on SNLI and MultiNLI
- Classification Head: $\text{softmax}(W_t(u, v, |u − v |))$
- $u,v$: pooled embeddings
- $W_t \in \mathbb{R}^{3n \times k}$
- Loss: Cross entropy loss
- Type II loss: Siamese Network + Regression Loss
- Trained on training set of the STS benchmark dataset
- Regression Head: $\text{cosine}(u,v)$
- Loss: MSE loss
- Type III loss: Triplet Network + Triplet Loss
- Trained on Wikipedia Sections Distinction dataset (Section 4.4)
- Head: pooled embeddings
- $s_a$: anchor sentence
- $s_p$: positive example
- $s_n$: negative example
- Loss: $\text{max}( | s_a - s_p | - | s_a - s_n | + \epsilon, 0)$, Euclidean distance
Some Personal Thoughts on Loss Functions
Strictly speaking, only the Type II and Type III loss could be recognized as contrastive loss, since minimizing them
- Pull embedding/representation of similar sentence together
- Push embedding/representation of different sentence apart
The Type I loss relies on matrix multiplication between $W_t$ and embedding. I don’t think this loss can build good representations theoretically
- In inference, we directly compute cosine similarity between 2 embeddings
- In training, we have the linear probe matrix $W_t$ “helping” before softmax
- This may result in mismatch between training objective and inference objective
Results
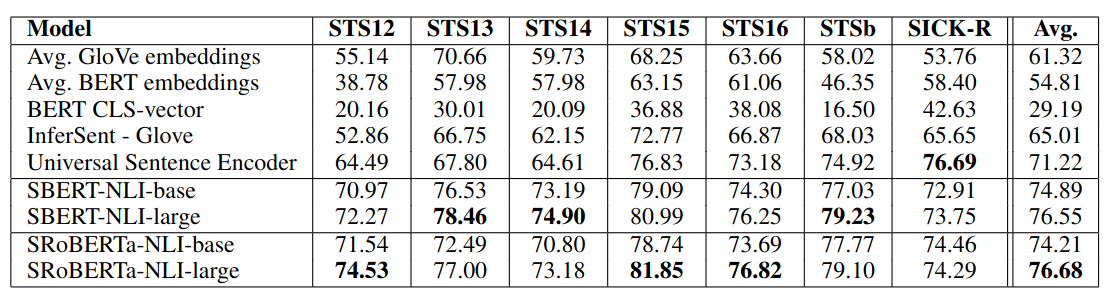
Spearman rank correlation $\rho$ between the cosine similarity of sentence representations and the gold labels for various Textual Similarity (STS) tasks.
SimCSE
- Contrastive Loss / in-batch negatives
- Unsupervised & Supervised training
- Results
- Evaluation on STS tasks
- Unsupervised: +4.2% SOTA (CT-BERT / DeCLUTR-RoBERTa)
- Supervised: +2.2% SOTA (CT-SBERT / SRoBERTa-whitening)
- Huggingface - sup-simcse-roberta-large
Dataset
- Unsupervised: $10^6$ randomly sampled sentences from English Wikipedia
- Supervised: 314k examples from MNLI and SNLI datasets
Architecture
- Backbone: pre-trained BERT or RoBERTa
Training
Contrastive Loss
- Unsupervised: Cross-entropy loss with in-batch negatives
- Supervised: Cross-entropy loss with hard negatives + in-batch negatives
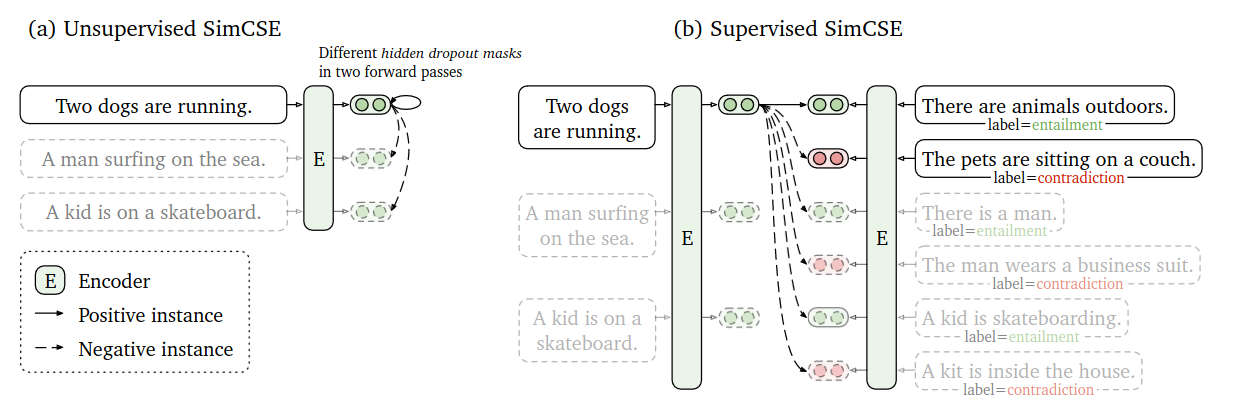
Left: SimCSE with in-batch negatives (see dashed arrow). Right: SimCSE with hard negatives and in-batch negatives (see dashed arrow).
Notations
- $\tau$: temperature hyperparameter
- $x_i, x_i^+, x_i^-$: anchor / positive / negative example
- $h_i$: representation of $x_i$ / $h = f_\theta(x)$
- $sim(\cdot, \cdot)$: cosine similarity
Unsupervised loss:
\[l = -\log \frac{ e^{sim(h_i, h_i^+) /\tau} }{ \sum_{j=1}^N e^{sim(h_i, h_j^+) /\tau} }\]Supervised loss:
\[l = -\log \frac{ e^{sim(h_i, h_i^+) /\tau} }{ \sum_{j=1}^N e^{sim(h_i, h_j^+) /\tau} + e^{sim(h_i, h_j^-) /\tau} }\]Contrastive Sample
- Unsupervised Training
- Anchor / Positive: same sentence pass through encoder twice with dropout (data augmentation)
- Negative: In-batch negatives
- Supervised Training
- Anchor / Positive: entailment from dataset
- Negative: hard negatives from dataset + in-batch negatives
Results
- Outperforms SOTA
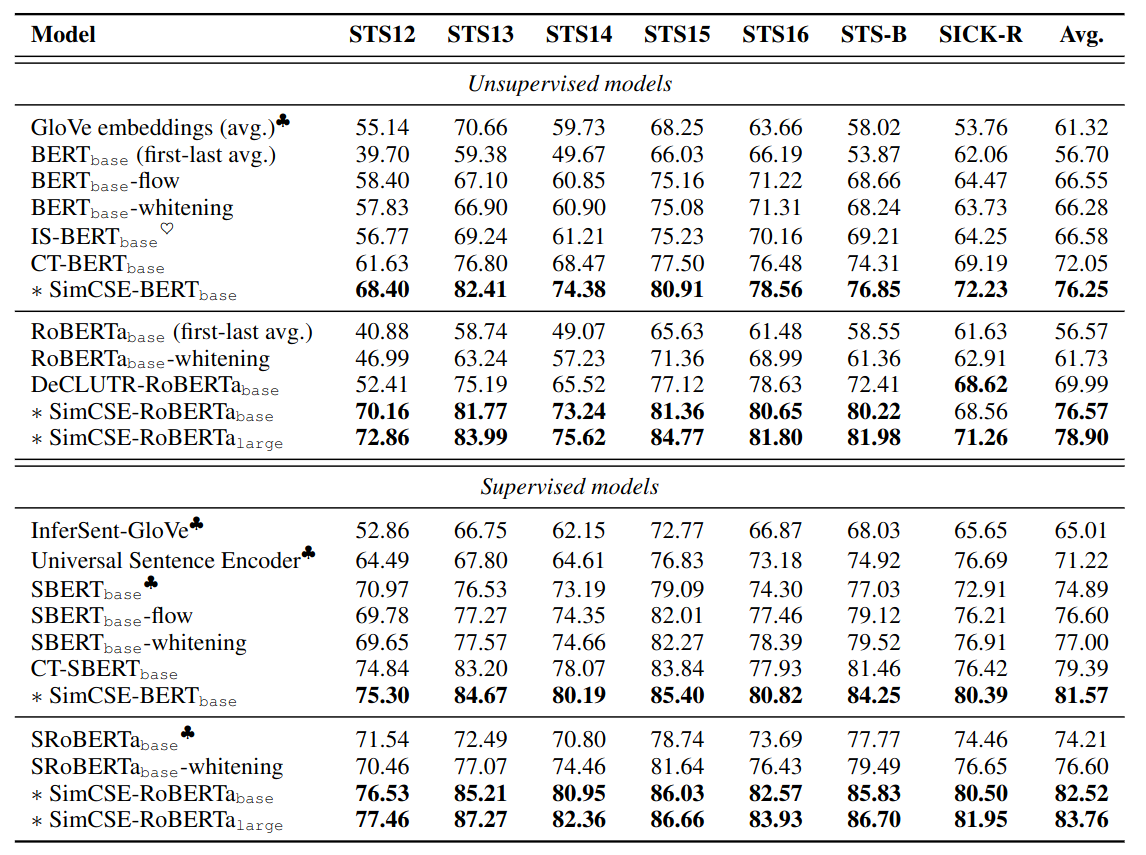
Sentence embedding performance on STS tasks.
Ablation
Data Augmentation
- For unsupervised training, how to construct positive pairs / similar sentence pairs
- Previous approach: word deletion, reordering, and substitution
- SimCSE: standard dropout on intermediate representations
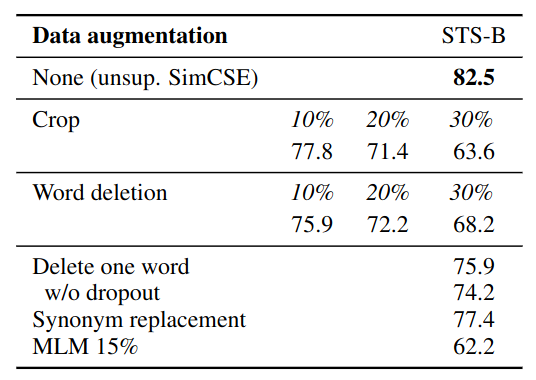
Comparison of data augmentations on STS-B development set (Spearman’s correlation).
There we could see data augmentation in NLP is very different from CV
- Cropping an image is not likely to change its meaning
- Word deletion, reordering, and substitution could change meaning of a sentence
Quality of Contrastive Embeddings
- Measuring embedding quality paper: Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere
- Quality of learned representations can be measured by alignment and uniformity
- Alignment: expected distance between positive embeddings pair
- Uniformity: distribution in embedding space
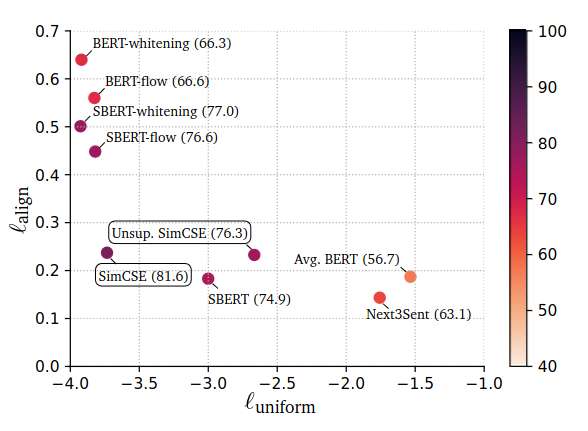
Embedding Alignment-Uniformity plot. Color of the points are based on STS performance (Spearman’s correlation).
OpenAI Text Embedding
- Results: outperforms SOTA on linear-probe classification accuracy averaging over 7 tasks
- Model-id
- This is NOT their
text-embedding-ada-002model - Embeddings Documentation
- Blog: 1st gen embedding model
- Blog: 2nd gen embedding model
- This is NOT their
Relationship to OpenAI Model Name
cpt-text-S/M/L/XLcorresponding to*-ada-*-001,*-babbage-*-001,*-curie-*-001,*-davinci-*-001- Cross reference of embedding dimension between: paper’s Table 1 and Model Documentation
text-embedding-ada-002- Apart from a OpenAI blog, there is no information on how
- According to their blog,
text-embedding-ada-002generally outperform all first generationcpt-models on various tasks - Dimension=1536 (between
ada-001’s dim=1024 andbabbage-001’s dim=2048)
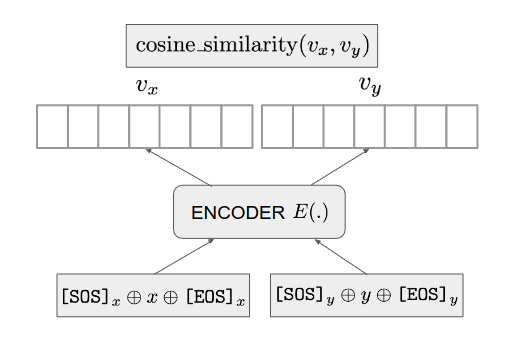
Architecture
- backbone: Transformer encoder
- Scale: 300M to 175B parameters
Training
- Data
- Text search: (text, text) pairs, Internet data
- Code search: (text, code) pairs, extracted from open source code
- Loss: contrastive loss with in-batch negatives
- Initialization: pre-trained GPT (
text-*orcode-*model) - Large batch size is crucial to achieve good performance with our setup
Results
- Tasks: linear-probe classification, sentence similarity, and semantic search
- Text search
- MSMARCO passage ranking task
- 23.4% relative improvement over SOTA unsupervised
- Code search
- CodeSearchNet: find most relevant code snippet given a natural language query
- 20.8% relative improvement over the SOTA
- No performance improvement on code search when increasing the number of parameters
- Outperforms SOTA
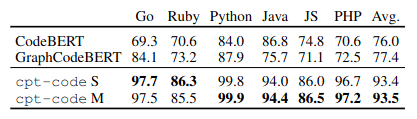
Comparison of cpt-code on code search across 6 programming languages with CodeBERT and GraphCodeBERT.
cpt-text underperform SimCSE on Sentence Similarity task. Refer to the discussion on difference between Sentence Similarity or Information Extraction at the beginning of the post.
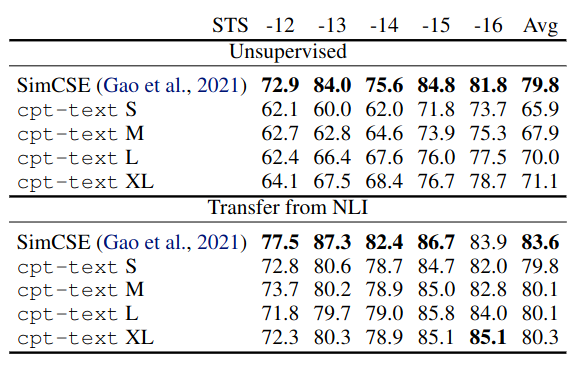
Ablation
- Effect of batch size
- Refer to Table 9
cpt-text-Strained with small vs large batch size 1536- Batch size=1536, MRR@10 = 71.4
- Batch size=12288, MRR@10 = 84.7
- A larger batch increases the chances of having hard negatives in a single batch
- Training Behavior
- As training step increase
- Performance on search and classification tasks increases
- Performance on sentence similarity tasks decreases
- May related to “sentence similarity is not a well defined task” issue discussed at the beginning
- As training step increase