Multi-Head Attention Variants
This post is mainly based on
- Multi-Query Attention: Fast Transformer Decoding: One Write-Head is All You Need
- Grouped-Query Attention: GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) are architectures optimized for inference.
During inference, transformer needs to repeatedly reload the large “keys” and “values” tensors to perform auto-regressive token generation, which is limited by GPU memory bandwidth. The goal of MQA and GQA is to reduce memory bandwidth cost by reducing number of keys $K$ and values $V$ in the Multi-Head Attention (MHA) architecture.
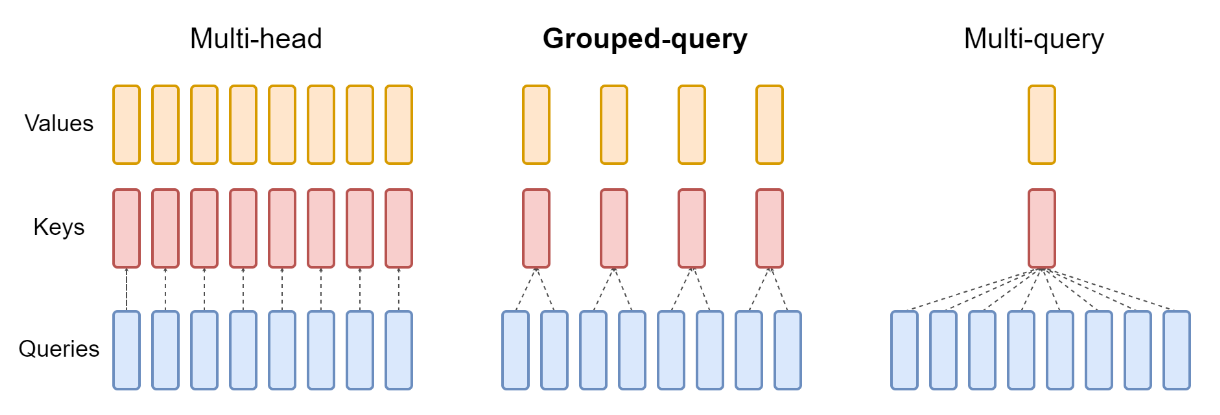
Let $H$ by number of query head. Multi-head attention has $H$ query, key, and value heads. Multi-query attention shares single key and value heads across all $H$ query heads. Grouped-query attention instead shares single key and value heads for each group of query heads, interpolating between multi-head and multi-query attention.
Comparing MQA and GQA-8 (T5-XXL backbone)
- Performance
- MQA: minor performance degradation
- GQA: competitive to MHA
- Speed
- MQA: 6x inference speed improvement
- GQA: 5x inference speed improvement
- Training
- MQA: training from scratch
- GQA: can be trained from a MHA checkpoint, using 5% of original pre-training compute resource
Multi-Query Attention
- High arithmetic intensity is required for high GPU utilization
- Measuring arithmetic intensity: Ratio of memory access to arithmetic operations ($Ratio$)
- An optimal ratio should be $Ratio <0.01$
Arithmetic Intensity Analysis
Notations
- $b$: batch size
- $n$: sequence length
- $d$: embedding dimension
- $k$: query-key dimension
- $k=\frac{d}{h}$
- $n \leq d$
MHA - Training
- Arithmetic: $O(bnd^2)$
- Memory: $O(bnd + bhn^2 + d^2)$
- $bnd$ term: I/O on $X, M, Q, K, V, O, Y$soa
- $Ratio$: $O(\frac{1}{k} + \frac{1}{bn})$
- $\frac{bnd}{bnd^2} = 1/d$
- $\frac{bhn^2}{bnd^2} = hn/d^2 = \frac{1}{k} \frac{n}{d} < 1/k$
- $\frac{d^2}{bnd^2} = 1/bn$
MHA - Inference
- Arithmetic: $\Theta(bnd^2)$
- Memory: $\Theta(bn^2d + nd^2)$
- Neglect small I/O on autoregressive $x, q, o, y$
- $bn^2d$ term: I/O on $n$ repeated load of $K, V$, each incur $O(bnd)$
- $nd^2$ term: I/O on $n$ repeated load of model parameters, each incur $d^2$
- $Ratio$: $\Theta(\frac{n}{d} + \frac{1}{b})$
- When context length grow, the above ratio will increase
- When batch size is small (e.g., just 1 user inference), the above ratio will increase
MQA - Inference
- Arithmetic: $\Theta(bnd^2)$
- Memory: $\Theta(bn^2k + nd^2)$
- For first memory term in MHA - inference: $bn^2d$, where $d = kh$, reduce to $h = 1$
- $Ratio$: $\Theta(\frac{n}{dh} + \frac{1}{b})$
- $\frac{n}{dh}$ is better $\frac{n}{d}$ by a factor of $h$
Experiment
- Baseline model: encoder-decoder Transformer for NMT
- 6 layers
- $d = 1024$
- $h = 8$
- $k = v = 128$
- Feedforward network: $d_{ff} = 4096$
- MQA implementation
- Feedforward network: $d_{ff} = 5440$
- To ensure the total parameter-count of MQA equal to MHA
- Config
- Dataset: WMT 2014 English-German translation
- Context length: 256
- Hardware: TPUv2
- Performance degradation
- Training Perplexity: $1.424 \rightarrow 1.439$
- Testing BLEU: $27.7 \rightarrow 27.5$
- Speed
- Training: similar
- Inference: MQA achieve 6x-10x speed increase, depending on if conducting Beam-Search decoding
Grouped-Query Attention
- Problems with Multi-Query Attention
- MQA can lead to quality degradation and training instability
- May not be feasible to train separate models optimized for inference
- Can be uptrained from a MHA model checkpoint with 5% of pre-training compute budget
- Grouped-Query Attention generalize Multi-Query Attention
Uptraining
- Step 1. converting the checkpoint
- The projection matrices $P_k, P_v$ for $h$ heads are mean pooled into single projection matrices
- Better than selecting a single key and value head or randomly initializing new key and value heads
- Step 2. additional pre-training
Experiments
- Baseline model: T5 XXL
- Comparing models
- Uptrained MQA and GQA
- MQA and GQA are applied to decoder self-attention and cross-attention, but not encoder self-attention
- Datasets
- Summarization: CNN/Daily Mail, arXiv, PubMed, MediaSum, and MultiNews
- NMT: WMT
- Question-answering: TriviaQA
- Models are fine-tuned for the above datasets
- Ablation
- Both MQA and GQA gain from 5% uptraining with diminishing returns from 10%
- Number of groups: $1 \rightarrow 8$ groups adds minor inference overhead
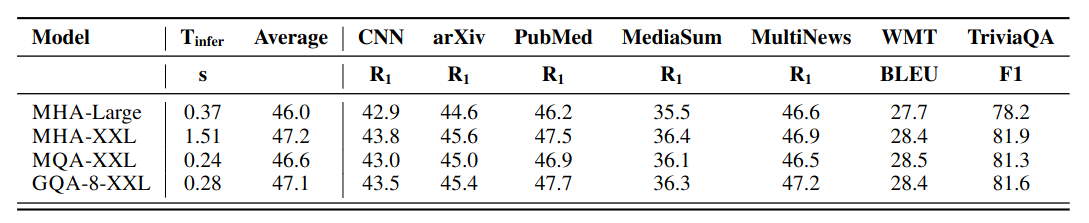
Inference time and average testing performance of T5-Large and T5-XXL, on multi-head/multi-query and grouped-query attention.