LLM: 2022 Jan - 2023 Jun
This post is mainly based on
- Models
| LLM | Developer | Scale | Year | Open Source |
| GPT-3 | OpenAI | 175B | 2020 | No |
| LaMDA | 137B | 2022 | No | |
| PaLM | 540B | 2022 | No | |
| LLaMA | Meta | 65B | 2023 | Non-commercial |
| Alpaca | Stanford | 7B | 2023 | Non-commercial |
LaMDA
- 137B parameters
- Specialized for dialog: pre-trained on 1.56T words of public dialog data and web text
- Goal: improve safety & factual grounding
- Safety: fine-tuning with annotated data
- Factual grounding: enabling the model to consult external knowledge sources
- Dialog evaluation metrics: sensibleness, specificity and interestingness
Dataset
- 2.97B documents, 1.12B dialogs, 13.39B dialog utterances. Total: 1.56T words
Architecture
- Activation: gated-GELU
- Attention: relative attention as described in T5
- Vocabulary: 32K tokens, from SentencePiece
Evaluation
- SSI
- Sensibleness: measures whether a model’s responses make sense in context and do not contradict anything that was said earlier
- Specificity: measure whether a response is specific to a given context
- Interestingness: measure whether the response “catch someone’s attention” or “arouse their curiosity”
- Rank by human
- Safety: see Appendix A.1
- Groundedness
- Groundedness: percentage of responses containing claims about the external world that can be supported by authoritative external sources
- Informativeness: percentage of responses that carry information about the external world that can be supported by known sources as a share of all response
- Citation accuracy: percentage of model responses that cite the URLs of their sources as a share of all responses with explicit claims about the external world
- Role-specific metrics
- Helpfulness: helpful responses are a subset of informative ones, which are judged by the user to be both correct and useful
- Role consistency: consistency with the definition of the agent’s role external to the conversation
PaLM
- 540B parameters
- Pathways: a new ML system for training across multiple TPU Pods
- PaLM was trained on 6144 TPU v4 chips using Pathways
- Achieving 57.8% in hardware FLOPs utilization
- Paper: Pathways: Asynchronous distributed dataflow for ML
Dataset
- Trained on a single pass over a 780B token corpus

Architecture
- SwiGLU Activation: $(Swish(xW) \cdot xV )$ for the MLP intermediate activations
- Parallel Layers
- Standard: $y = x + MLP(LayerNorm(x + Attention(LayerNorm(x)))$
- Parallel: $y = x + MLP(LayerNorm(x)) + Attention(LayerNorm(x))$
- 15% faster training speed, small degradation on small model
- Multi-Query Attention: [Fast transformer decoding: One write-head is all you need]
- RoPE Embeddings: [Roformer: Enhanced transformer with rotary position embedding]
- Shared Input-Output Embeddings (???)
- No Biases: in any of the dense kernels or layer norms / increase training stability
- Vocabulary: [SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing]
Optimization
- Weight initialization
- Kernel weights: $W \sim N(0, 1/\sqrt{n_in})$, $n_in =$ input dim
- Embedding weights: $E \sim N(0,1)$
- Optimizer: Adafactor
- Hyperparameters
- Lr: $10^{-2}$ for the first $k=10000$ steps, then decay at rate $1/\sqrt{k}$
- Modified $\beta_1, \beta_2$ for rate embedding tokens
- Gradient clipping: 1.0
- Loss: LM loss + Aux loss for stability
- Sequence length: 2048
- Batch size: 512 -> 1024 -> 2048
- Dropout: 0.1
- Determinism: training is fully reproducible via JAX + deterministic dataloader
- Instability
- ~20 loss spikes, despite gradient clipping
- Sometimes happening late into training
- Not observed when training the smaller models
- Mitigation: re-start training ~100 steps before spike + skip ~200-500 data batches
Memorization
- Evaluation
- Prompted the model with the first 50 tokens from the span, then greedy decoding
- Measure how often the model produced a 50-token continuation that exactly matches the training example
- Exactly reproduce: 2.4% of data
- Examples seen more than 500 times have a memorization rate of over 40%
- Breakdown by corpus: code has the highest memorization rate (15%)
LLaMA
- Possible to train SOTA models using publicly available datasets exclusively
- LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B
- LLaMA-13B outperforms GPT-3 on most benchmarks, despite being 10× smaller / can be run on a single GPU
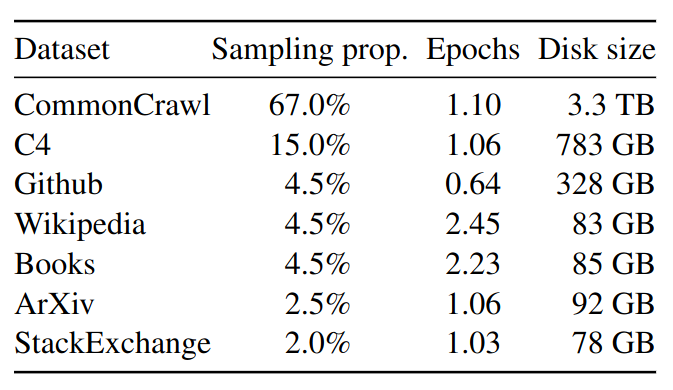
Dataset
- Preprocessing
- CommonCrawl 2017-2020: preprocess with CCNet pipeline, deduplicates the data at the line level
- C4: deduplication and language identification
- Github: public dataset from Google BigQuery
- ArXiv: removed everything before the first section, bibliography, comments and macros
- Stack Exchange: top 28 websites, removed the HTML tags + sorted answers by score
- ~1.4T tokens after tokenization
- For most training data, each token is used only once during training
- For Wikipedia and Books domains, each token is used twice
Architecture
- Pre-normalization
- RMSNorm normalizing
- Improve the training stability
- Normalize the input of each transformer sub-layer, instead of normalizing the output
- Acitvation: SwiGLU
- Rotary Embeddings
- Tokenizer: BPE implementation from SentencePiece
Optimization
- Optimizer: AdamW
- Lr: cosine learning rate schedule, final lr = 10% max lr
- Gradient clipping: 1.0
- Warmup: 2000 steps
- Implementation: xformers
- Not store/compute the masked part of the attention matrix
- reimplement .backward(): store the activations that are expensive to compute
- Compute time for 65B model
- ~380 tokens/sec/GPU on 2048 A100-80GB
- 1.4T tokens takes approximately 21 days
Evaluation
- 6 types of common evaluation benchmarks
- Instruction Finetuning
- Small improvement on MMLU (5-shots)
- LLaMA-I 68.9% vs code-davinci-002 77.4%
- Warning: paper’s MMLU (5-shots) result is different from Open LLM Leaderboard result
Alpaca
- Fine-tuned from LLaMA-7B
- Supervised learning on 52K instruction-following demonstrations generated from text-davinci-003
Data
- Generated instruction-following demonstrations based on self-instruct method
- Process
- Step 1: 175 human-written instruction-output pairs from the self-instruct seed set
- Step 2: text-davinci-003 generate more instructions using the seed set as in-context examples
- Simplified the generation pipeline: Github
- Results: 52K unique instructions and the corresponding outputs, (costed <$500)
Optimization
- Techiniques
- Fully Sharded Data Parallel
- Mixed precision training
- Fine-tuning
- Time: 3 hours on 8 A100-80GB
- Cost: <$100
- Hyperparameter
- Batch size: 128
- Lr: 2e-5
- Epochs: 3
- Max length: 512
- Weight decay: 0
- Addressing OOM
- Naively, fine-tuning a 7B model requires about 7 x 4 x 4 = 112 GB of VRAM
- Parameter sharding: no redundant model copy is stored on any GPU
- Turn on CPU offload for FSDP
- LoRA: reduce the total memory footprint from 112GB to about 7 x 4 = 28GB
Evaluation
- Human evaluation on: Self-instruct evaluation set
- Bind pairwise comparison: Alpaca wins 90 vs 89 comparisons against text-davinci-003
- Alpaca’s answers are typically shorter than ChatGPT, reflecting text-davinci-003’s shorter outputs
- Deficiencies: hallucination, toxicity, and stereotypes
- Can be used to generate well-written outputs that spread misinformation