Prompt Tuning
This post is mainly based on
- Prefix-tuning: Optimizing continuous prompts for generation, 2021
- The power of scale for parameter-efficient prompt tuning, 2021
Fine tuning (FT) requires modifying LLM’s parameter to better transfer to a task. It is resource intensive and may modify model behavior. Prompt tuning (PT) use optimization to find an optimal sequence of “soft tokens”, prepend to the task string, to steer the model to perform certain task. PT can outperform / is competitive to FT on large model (>10B parameters). Experiments show that PT is more robust to domain transfer.
However, PT could converge slower than FT according to this paper. I’m a little be skeptical about the scale of training time difference, since better PT requires larger model, but they choose to plot training time of RoBERTa-Large-350M, rather than T5-XXL-11B. Nevertheless, their result show that learned “soft prompt” can be transferred across tasks or across models (requires training a projector to project vectors between 2 embedding spaces), significantly reducing training time.
Prefix-Tuning
- Prefix
- A small continuous task-specific vector
- Allowing subsequent tokens to attend to this prefix as if it were “virtual tokens”
- Optimization
- Language model parameters is frozen
- Optimize prefix parameters (0.1% of the model parameters)
- Performance
- Competitive to full dataset fine-tuning
- Outperforms low dataset fine-tuning
- Generalize better to unseen data
Intuition
- How does prefix works?
- The downstream tokens can attend to the upstream prefix
- The contextualized embedding of downstream tokens is changed by prefix
- Prefix can steer the language model to certain task
- Hence, a single LM can be prefix-tuned to
- Support many tasks
- Support many users
- Perform inference based on input from different users/tasks in a single batch
Prefix-Tuning vs Other Methods
- Prompt
- Parameters of the prompt tokens are fixed
- Parameters of the LLM are fixed
- No optimization is required
- AutoPrompt
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
- Searches for a sequence of discrete trigger words
- Concatenates trigger words with each input
- Elicit LLM to output target sentiment or factual knowledge
- No optimization on embedding layer / LLM is required
- Prefix-Tuning
- Parameters of the prefix matrix are learnable
- Parameters of the LLM are fixed
- Optimize 0.1% of model parameters
- Light weight fine-tuning
- Does not require prompt
- Parameters of the LLM output layer are optimized
- Optimize 3.6% of model parameters
Model
- What is prefix
- Prefix is NOT tokens, it is a matrix / “virtual tokens”
- Prefix is NOT a representation of a sequence of tokens mapped by a custom embedding layer
- Prefix is a matrix that append to transformer activation across ALL layers
- The custom embedding layer / token approach results in significantly lower performance
- LLM notations
- Let $x$ be input sequence and $y$ be output sequence, $z = [x;y]$
- LLM decoder: $LM_\phi$
- Activation at decoder step $i$: $h_i = [h_i^{(1)}, … h_i^{(n)}]$, where $h_i^{(j)}$ is activation at layer $j$
- $h_i = LM_\phi(z_i, h_{<i})$
- Prefix
- Prefix matrix: $P_\theta \in \mathbb{R}^{len \times dim}$
- $len$ is prefix length and $dim$ is model dimension across all layers
- $\phi$ is fixed, $\theta$ is optimized
- Parametrization of $P_\theta$
- Directly update $\theta$ leads to unstable optimization
- Reparametrize $P_\theta$ by output of \(\operatorname{MLP}_\theta(P_\theta')\)
- Where \(\operatorname{MLP}_\theta\) is a large feedforward network and $P_\theta’$ is a small matrix
- Since model is uni-directional, once training is complete, we can just store $P_\theta$

Evaluation
- Datasets
- Table-to-text Generation
- Datasets: E2E, WebNLG and DART
- Competitive / outperform SOTA & fine-tuning in BLEU
- Summarization
- Datasets: XSUM
- Competitive to fine-tuning under ROUGE-1 and ROUGE-2, ROUGE-L
- Low-data Setting
- Datasets: E2E, XSUM (size = 50, 100, 200, 500)
- Consistently outperforms fine-tuning on all data size
- Extrapolation
- Datasets: WebNLG, XSUM (train on SEEN, eval on UNSEEN)
- Better extrapolation than fine-tuning under all metric
Ablation
- Prefix length
- Longer prefix => more trainable parameters
- Overfitting when prefix is too long (DART > 10, XSUM > 200)
- Full vs Embedding-only
- Full: optimize activation across all layers
- Embedding-only: special input token + optimize custom embedding layer
- Embedding-only leads to significantly reduced performance
- Tuning only the embedding layer is not sufficiently expressive
- Prefixing vs Infixing
- Prefixing: [PREFIX; x; y]
- Infixing: [x; INFIX; y]
- Since model is uni-directional, contextualized embedding of $x$ does not include Infixing information
- Infixing outperforms Embedding-only, but underperforms Prefixing
- Initialization
- Random initialization leads to low performance with high variance
- Initializing the prefix with activations of real words significantly improves generation
- Initializing with task relevant words such as “summarization” and “table-to-text” obtains slightly better performance
- [Question] How to initialize to activations of certain words with parametrization of $P_\theta$?
Prompt Tuning
- Simplification of Prefix-Tuning
- Learning “soft prompts” for multi-tasking
- Learned prompt outperforms GPT-3’s few-shot learning by a large margin
- Performance
- Prompt tuning is competitive to fine-tuned model
- Prompt tuning scales better with larger model
- Robust to domain transfer
- Efficient “prompt ensembling” (multiple prompts for the same task)
Intuition
- Freeze the entire pre-trained model
- A sequence of $k$ special tunable tokens, prepended to the input text
- The special tokens steer the language model to perform specific tasks
- No intermediate-layer prefixes (i.e., Embedding-only)
Model
- LLM
- Base model: T5 (encoder-decoder)
- Problem: T5 is trained on Span Corruption loss
- Solution: fine-tuning T5 with language model loss (steer its behavior to GPT-3)
- $P_\theta(y | x)$, where embedding layer is specified by $\theta$
- Prompt parameter: $\theta_P$
- Map the sequence of $k$ special tunable tokens to $k$ vectors
- “Expand” the embedding layer
- Notations
- Dimension of embedding space: $e$
- Input tokens: $X_e \in \mathbb{R}^{p \times e}$
- Input tokens: $P_e \in \mathbb{R}^{p \times e}$
- Length of prompt: $p$
- Prepend input: $[P_e, X_e]$
- Optimization: only applied to $\theta_P$
- Initialization of $P_e$
- Initialize by embeddings of the output classes
- Intuition: model should output these tokens, hence attention to they may be helpful
- Prompt length $p$
- $p = 100$
- Although $p=100$ is longer than prefix-tuning’s length=10, prompt tuning still use less parameters
- Prompt tuning only optimize embedding layer, as oppose to overwriting all activation layers
Optimization
- Optimizer: Adafactor
- Prompt tuning steps: 30,000
- Learning rate: 0.3
- Batch size of 32
- Early stopping on the development set
Evaluation
- Dataset: SuperGLUE
- Translate each SuperGLUE dataset into a text-to-text format
- Benchmark model
- Fine-tuning: Public T5.1.1 checkpoints with default hyperparameters
- Prompt design: GPT-3 few-shot, reported by Brown et al. (2020)
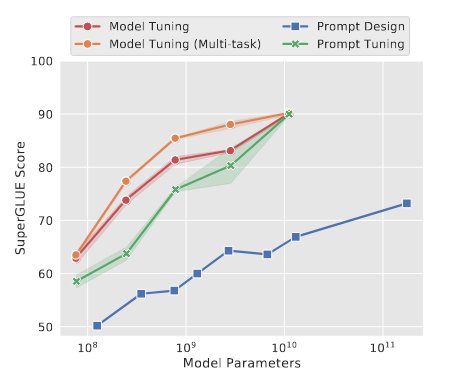
- Results
- Prompt tuning significantly outperforms Prompt design
- Prompt tuning is competitive to Fine-tuning on large LLM
- Prompt tuning becomes more competitive with scale
- Language model capacity is important
- Prompt Tuning Underperforms Prefix Tuning in Li and Liang (2021)
- Possible due to Prefix Tuning is based on GPT-2 (1.5B parameters)
Ablation
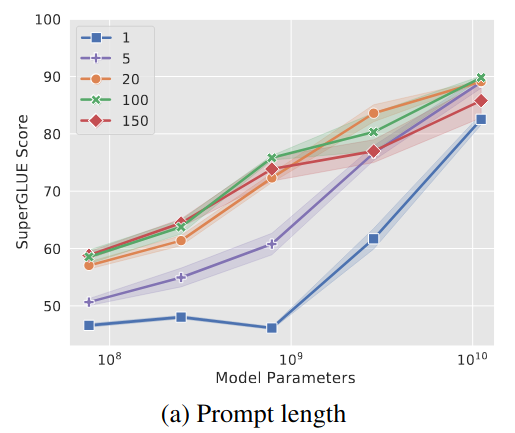
Prompt Length
- 5 model size
- 5 prompt length
- Larger model requires less conditioning signal / shorter prompt length
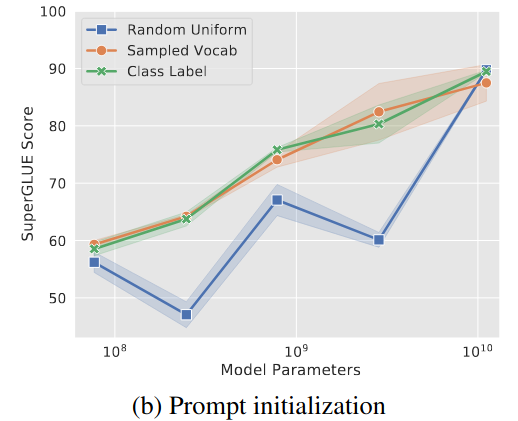
Prompt Initialization
- Random initialization: [−0.5, 0.5]
- Sampled vocabulary: 5,000 most “common” tokens in T5
- Class label: embeddings for the string representations of each class in the downstream task
- Gap between Random initialization and sampling approach shrink as model size grow
- No evidence that learned prompts are interpretable
Pre-training Objective
- “Span corruption” loss is not well-suited for in-context learning / conditioning by prompt
- Longer pre-training on language loss improves in-context learning across all model sizes

Resilience to Domain Shift
- Freezing the core language model prevent overfitting the training dataset
- Question answering
- Training: SQuAD
- Testing: 6 out-of-domain dataset from MRQA
- Prompt tuning outperforms model tuning on the majority of out-of-domain datasets
- Paraphrase detection
- Dataset 1: QQP, if 2 questions on Quora are “duplicates”
- Dateset 2: MRPC, if 2 sentences drawn from news articles are paraphrases
- Test transfer performance in both directions
- Prompt tuning outperforms or competitive to model tuning
Prompt Ensembling
- Model ensemble is expensive for LLM (e.g., 42G for T5-XXL)
- Prompt ensemble: training $N$ prompts on the same task
- Inference
- Execute a single forward pass with a batch size of $N$
- Equivalent to, replicating the example across the batch and varying the prompt
- Simple majority voting to predict class
- Performance: outperform oracle best prompt