Prompt Engineering
This post is mainly based on
- Few-shot CoT: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, 2022
- Zero-shot CoT: Large Language Models are Zero-Shot Reasoners, 2022
- Self-Consistency Decoding: Self-Consistency Improves Chain of Thought Reasoning in Language Models, 2022
- Extract Knowledge: Generated Knowledge Prompting for Commonsense Reasoning, 2021
Additional Resource
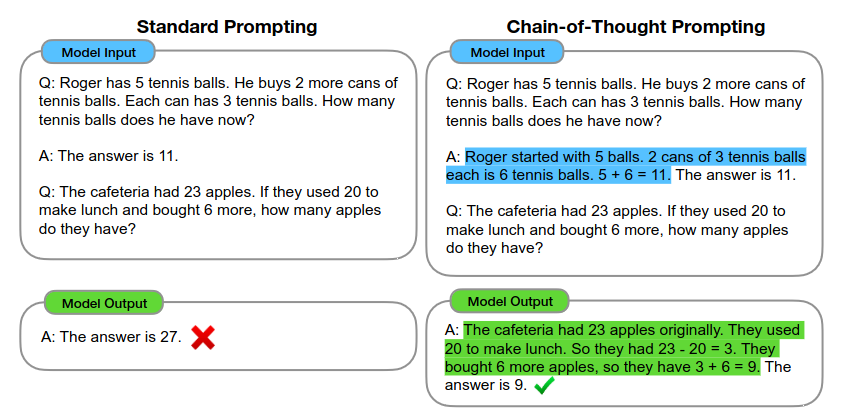
Chain-of-Thought Prompt
- Requires: sufficiently large language models (e.g., PaLM 540B)
- Scaling up model is NOT sufficient for logical tasks (arithmetic and symbolic reasoning)
- Add a series of intermediate reasoning step in few-shot examples
- Performance
- Outperforms standard prompting, sometimes to a striking degree
- SOTA accuracy on the GSM8K benchmark of math word problems
- Outperforms finetuned GPT-3 with a verifier
Advantage
- Decompose one problem into intermediate steps => additional computation can be allocated to each step
- Interpretable: possible to debug where the reasoning path went wrong
- Applicable to any task that humans can solve via language
Evaluations
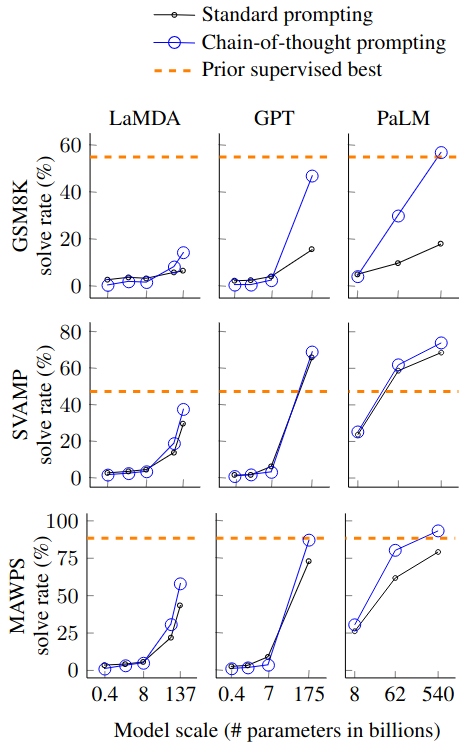
Arithmetic Reasoning
- Datasets
- GSM8K math word problems
- SVAMP math word problems
- ASDiv math word problems
- AQuA algebraic word problems
- MAWPS
- Models: LaMDA-137B, GPT-3-175B, PaLM-540B
- Performance
- Outperform / competitive to SOTA
- Model size
- Small model: fluent but illogical chains of thought
- Performance jump with model >100B parameters
- Problem complexity
- Larger performance gains for more-complicated problems (e.g., GSM8K)
- Ablation
- Equation only: minor performance gain
- Variable compute only: perform at same level as standard prompt
- Chain of thought after answer: perform at same level as standard prompt
- Robustness: to linguistic style, to annotators, to language models
Commonsense Reasoning
- Datasets: 5
- Models: LaMDA-137B, GPT-3-175B, PaLM-540B
- Performance
- Outperform / competitive to SOTA
- Outperform standard prompt
Symbolic Reasoning
- Tasks
- Last letter concatenation: e.g., “Amy Brown” => “yn”
- Coin flip: heads up after people either flip or don’t flip the coin
- Performance
- Significantly outperform standard prompt
- Larger gain on more complex problem (4 flips vs 2 flips)
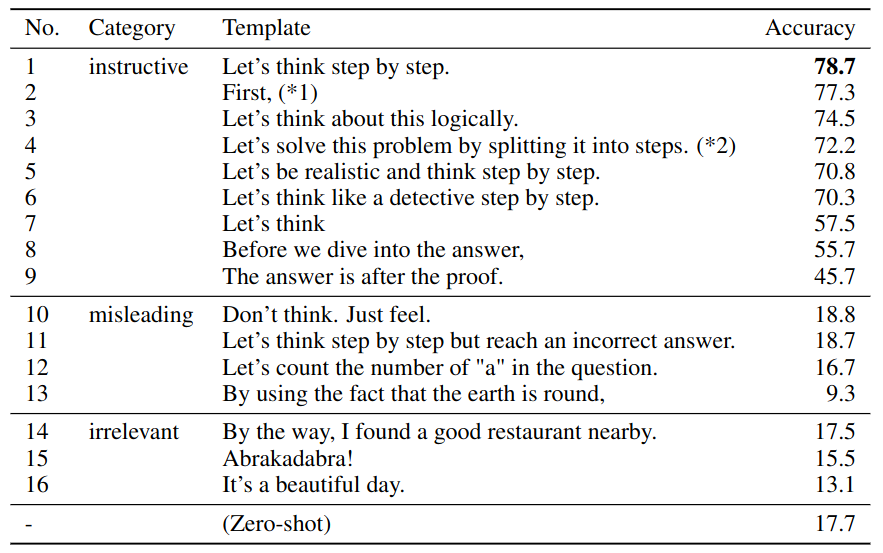
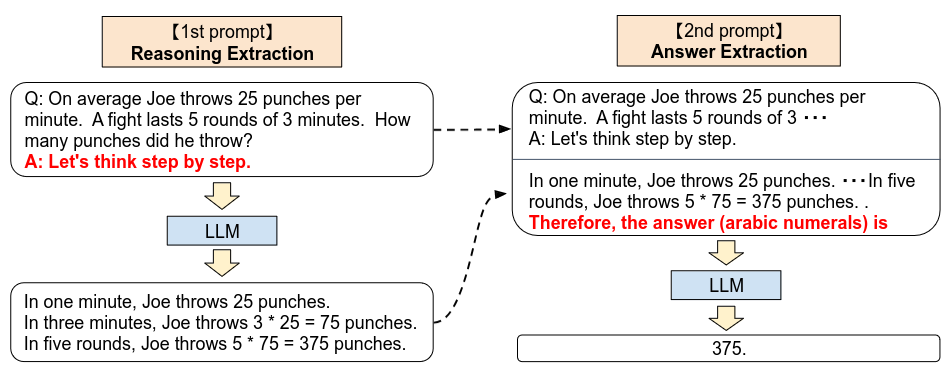
Zero-shot CoT
- Two stage prompt
- Stage 1: Add “Let’s think step by step” before each answer
- Stage 2: Concat LLM’s reasoning and extract answer
- Performance
- Significantly outperform zero-shot standard prompt
- Accuracy on MultiArith: 17.7% => 78.7% (InstructGPT)
- Accuracy on GSM8K: 10.4% => 40.7% (InstructGPT)
- Highlight the importance of carefully exploring and analyzing the enormous zero-shot knowledge hidden inside LLMs before crafting finetuning datasets or few-shot exemplars
Model
Evaluation
- Datasets
- Arithmetic reasoning: 6
- Commonsense reasoning: 2
- Symbolic reasoning: 2
- Models
- 17 models in total
- Main experiments: GPT3, Instruct-GPT3, PaLM
- Baseline
- Standard Zero-shot prompt
- Few-shot
- Few-shot-CoT
- Answer cleansing
- Part of the answer text that first satisfies the answer format
- e.g., “probably 375 and 376” => 375
- Results
- Arithmetic reasoning: significant gain vs standard Zero-shot prompt
- Commonsense reasoning: no performance gain
- Symbolic reasoning: 2
- Analysis
- Larger model has higher zero-shot CoT gain
- Often produces reasonable CoT even when the final prediction is incorrect
- Often output multiple answer choices when the model cannot narrow down to one answer
- Zero-shot CoT is versatile and task-agnostic
- Zero-shot CoT underperforms well engineered Few-shot-CoT, but is more robust
Robustness of Prompt Selection
- Zero-shot CoT > Few-shot-CoT
- Few-shot-CoT performance deteriorates if prompt example question types and task question type are unmatched