LLM: CodeGen and FLAN
This post is mainly based on
- CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis, ICLR 2023
- FLAN: Finetuned Language Models Are Zero-Shot Learners, ICLR 2022
Relationship between GPT and its open source approximates
- Codex $\approx$ CodeGen
- InstructGPT $\approx$ FLAN
CodeGen
- Multi-step paradigm for program synthesis
- A single program is factorized into multiple prompts specifying subproblems
- Multi-Turn Programming Benchmark (MTPB) repo
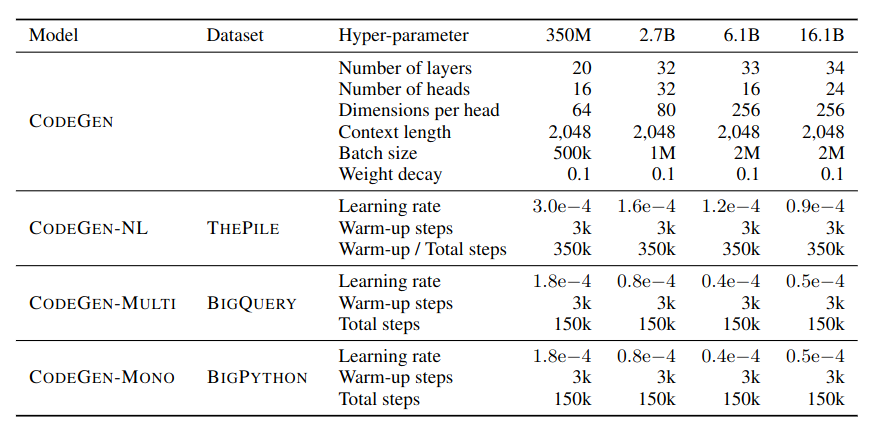
- Model size: 250M - 16.1B
- Trained on natural language and programming language data
- Competitive with SOTA zero-shot Python code generation on HumanEval
Key challenges in code generation
- Intractability of the search space
- Difficulty of properly specifying user intent
Dataset
- CodeGen-NL: ThePile
- 825.18 GiB English text corpus from 22 datasets
- Content: academic, internet, prose, dialogue, code, math
- Code: GitHub repositories with over 100 stars (7.6% of the dataset)
- CodeGen-Multi: BigQuery
- A subset of Google’s BigQuery dataset
- 6 programming languages: C, C++, Go, Java, JavaScript and Python
- CodeGen-Mono: BigPython
- Public GitHub code
- Preprocessing
- Filtering, deduplication, tokenization, shuffling and concatenation
- Sequential training
- First train CodeGen-NL on ThePile
- Initialize CodeGen-Multi from CodeGen-NL and train on BigQuery
- Initialize CodeGen-Mono form CodeGen-Multi and train on BigPython
Model
Evaluations
Single Turn Program Synthesis
- Dataset: HumanEval
- CodeGen-Mono-16.1B outperforms Codex-12B on pass@1, 10 and 100
- CodeGen-Mono-16.1B significantly underperforms code-davinci-002
- Understanding of user intention
- Perplexity of problem prompts provides a proxy for the system’s understanding of user intent specification
- A low perplexity prompt indicates user intention is compatible with the knowledge learned by the model
- Findings: pass problems prompts have lower perplexity than non-pass problems prompts

Average prompt perplexity (± standard error) of CodeGen-Mono models on pass and non-pass problems
Multi Turn Program Synthesis
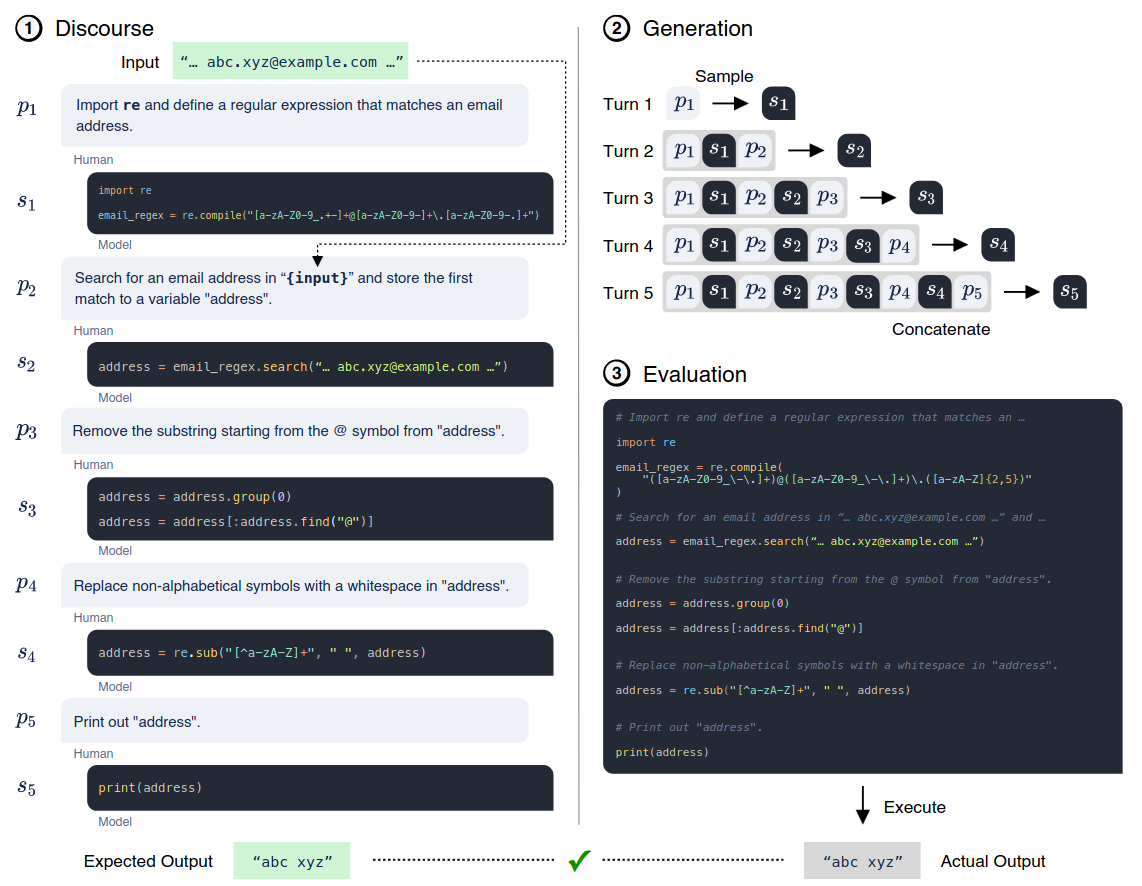
Dataset: MTPB (Multi-Turn Programming Benchmark)
- 115 problems written by experts
- Multi-step descriptions in natural language (prompt)
- Model needs to synthesize functionally correct subprograms, which
- Following the description at the current step
- Considering descriptions and synthesized subprograms at previous steps
- Knowledge: math, array operations, string manipulations, algorithms, data science
- Data: (multi-turn prompts $P$, test case inputs $I$, and test case outputs $O$)
- Each problem has 5 test cases
Hypothesis
- Multi-turn factorization enhances the model’s understanding of user intention
- To test his hypothesis, we form a single-turn counterpart of multi-turn specifications by concatenating each specification into a single turn
- Findings
- Multi-Turn Prompts have lower perplexity
- Pass rate increased with multi-turn prompt

FLAN
- Instruction tuning
- Fine tuning on a collection of datasets described via instruction
- Combines advantage of pretrain-finetune and prompting
- Substantially improves the performance
- Zero-shot of fine tuned 137B LaMDA-PT surpasses 175B GPT-3 on 20 of 25 datasets
- Outperforms GPT-3 by a large margin on
- Natural language inference: ANLI, RTE
- Reading comprehension: BoolQ, OpenbookQA
- Closed-book QA: AI2-ARC
- Commonsense reasoning: StoryCloze
- Findings
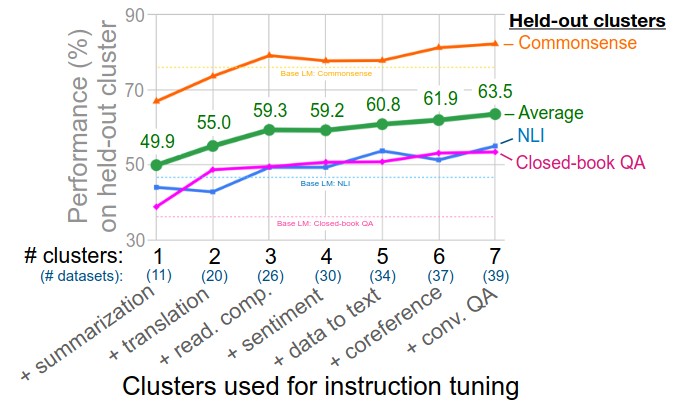
- Increasing the number of task clusters in instruction tuning improves performance on unseen tasks
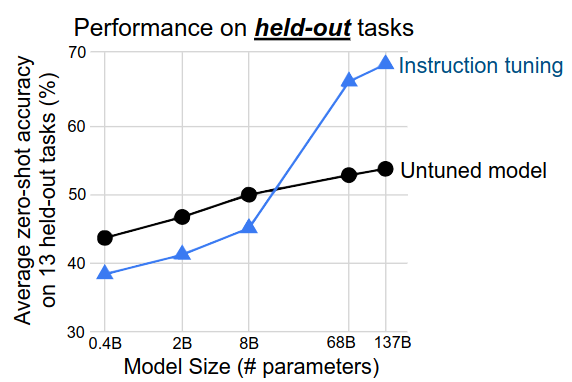
- Benefits of instruction tuning emerge only with sufficient large model
Motivation
- Problems of GPT-3
- Zero-shot performance is much worse than few-shot performance on some tasks: reading comprehension, question answering, and natural language inference
- One potential reason: without few-shot exemplars, it is harder for models to perform well on prompts that are not similar to the format of the pretraining data
- NLP tasks can be described via natural language instructions
- Is the sentiment of this movie review positive or negative?
- Translate ‘how are you’ into Chinese
- FLAN
- Abbreviation for: Finetuned Language Net
- Fine tune LLM on 60 NLP datasets expressed via natural language instructions
Dataset
- 62 publicly available text dataset
- Cluster into 12 tasks
- Instruction tuning
- For each dataset, 10 templates that use natural language instructions to describe the task
- For each dataset, up to 3 templates for inverse task (e.g., sentiment => movie review)
Model
- LaMDA-PT
- Dense decoder-only transformer language model
- 137B parameters
- LaMDA-PT is pre-training LaMDA (not fine tuned for dialog)
- Pretrained on a collection of web documents (with code), dialog data, and Wikipedia
- Tokenizer: BPE (32k vocabulary ) => 2.49T tokens
Optimization
- Instruction for task is randomly sampled
- Dataset size balancing
- Limit to 30k examples per dataset
- Examples-proportional mixing scheme
- Optimizer: Adafactor
- Learning rate: 3e-5
- Fine tune for 30k gradient steps
- Batch size: 8,192 tokens (???)
- Input: 1024 token / Output: 245 tokens
- Packing: combine multiple training examples into a single sequence
- 60 hours on a TPUv3 with 128 cores
Evaluation
- Zero-shot performance of FLAN on unseen tasks
- Group NLP datasets into clusters based on their task types
- Hold out each cluster for evaluation while instruction tuning FLAN on all other cluster
- Findings: Instruction tuning is
- Very effective on tasks naturally verbalized as instructions (e.g., NLI, QA, translation, struct-to-text)
- Less effective on tasks directly formulated as language modeling, where instructions would be largely redundant (e.g., commonsense reasoning and coreference resolution tasks that are formatted as finishing an incomplete sentence or paragraph)
- Increasing the number of task clusters in instruction tuning improves performance on unseen tasks
- Hold out clusters: NLI, closed-book QA, commonsense reasoning
- Average performance increase 13% (11 => 39 datasets)
- Benefits of instruction tuning emerge only with sufficient large model
- 2 large models: improve performance
- 3 small models: hurt performance
- Prompt tuning
- Prefix-tuning: Optimizing continuous prompts for generation
- The power of scale for parameter-efficient prompt tuning
- Train continuous prompts for each of the SuperGLUE tasks in accordance with the cluster splits
- Instruction tuning improves prompt tuning performance (32 training examples)