Early Open Source LLM
This post is mainly based on
- GPT-NeoX-20B: An Open-Source Autoregressive Language Model
- OPT: Open Pre-trained Transformer Language Models, 2022
- BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Model scale:
- GPT-3 (OpenAI): 175B
- GPT-Neo (EleutherAI): 2.7B
- GPT-NeoX (EleutherAI): 20B
- OPT (Meta): 175B (research-only) / 66B (open source)
- BLOOM: 176B
- StableLM: 3-7B (open source) / 15-66B (pending)
GPT-NeoX
- GPT-Neo Repo
- GPT-NeoX Repo
- Dense transformer
- Hardware
- Training: 12x clusters, each with 8x A100-40G
- Fine-tuning: 4x A100-40G
- Inference: 2x 3090 Ti or 1x A6000-48G
- Evaluation
- Competitive to similar size GPT-3 on language modeling benchmarks
- Better arithmetic performance
OPT
OPT (Open Pre-trained Transformer) is an open-source GPT-3 approximate. The paper and repo provide a detailed account of the training process, including: compute power, human overhead and ad-hoc optimization designs.
- “Open source”
- Small models (125M - 66B) are released
- 175B model is for non-commercial / research only
- Detailed description over model training
- Dataset / data cleaning
- Optimization challenges (e.g., hardware failures, loss divergence)
- Hardware intensive
- Pre-training: 992 80GB A100 GPUs
- Fine-tuning / deploy: 16 V100 GPUs
- Repo and training log
Dataset
- RoBERTa dataset
- BookCorpus
- Stories
- CCNews v2
- The Pile dataset
- CommonCrawl
- DM Mathematics: repo
- Project Gutenberg: ebooks
- HackerNews
- OpenSubtitles: database of movie and TV subtitles
- OpenWebText2: enhanced version of the original OpenWebTextCorpus scraped from Reddit
- USPTO: US patent and trademark research datasets
- Wikipedia
- PushShift.io Reddit dataset
- Pushshift.io corpus: historical Reddit data
- Processing
- Deduplication: Min-hashLSH with a Jaccard similarity > 0.95
- Ad-hoc whitespace normalization
- Reddit: convert the conversational trees into documents / keep only the longest chain of comments in each thread
Model
Largely based on GPT-3 architecture:
- Tokenizer: BPE
- Dropout: 0.1 (no dropout to embedding)
- Activation: ReLU
- Token length: 2048
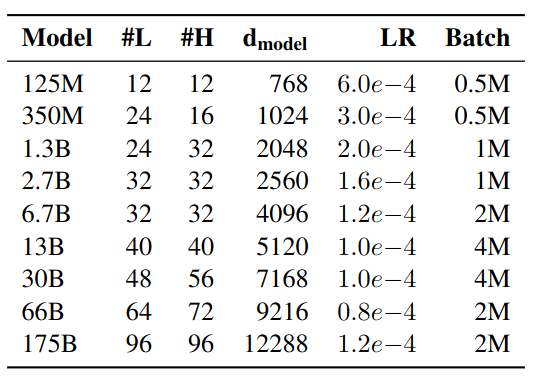
#L: number of layers, #H: number of attention heads
Optimization
- Weight initialization
- Follow Megatron-LM
- $\sim N(0, 0.006)$
- Output layers Standard deviation: scale by $1.0/\sqrt{2L}$, where $L$ is the # of layers
- Bias initialization: 0
- Optimizer
- AdamW(0.9, 0.95)
- Weight decay of 0.1
- Learning rate
- OPT-175B warm up: 0 to the maximum LR over the first 2000 step
- Smaller model warm up: 0 to the maximum LR over 375M tokens
- Decaying down to 10% of the maximum LR over 300B tokens
- Clip gradient norms at 1.0
- Gradient pre-divide factor
- Reduce the risk of over/underflows
- Splitting one division by $N$ into two divisions by $\sqrt{N}$
- Hardware
- OPT-175B is trained on 992 80GB A100 GPUs
- Adam state: FP32 (due to sharding across all hosts)
- Model parameters: FP16
- Dynamic loss scaling from Mixed Precision Training
Training Processes
- Training takes over 2 month
- Hardware Failures
- At least 35 manual restarts and 70+ automatic restarts
- During manual restarts, a series of diagnostics tests were conducted to detect problematic node
- Flagged nodes were taken offline and training was resumed from the last saved checkpoint
- Over 100 hosts were cycled out
- Loss Divergences
- Lowering the learning rate and restarting from an earlier checkpoint
- Correlation between
- Loss divergence
- Dynamic loss scalar crashing to 0
- L2-norm of the activations of the final layer spiking
- Hence, earlier checkpoint is picked s.t., dynamic loss scalar was still in a “healthy” state (>1.0)
- Reducing Loss Divergences
- Lowering gradient clipping from 1.0 to 0.3
- Switching to vanilla SGD (after optimization plateaued reverted back to AdamW)
- Resetting the dynamic loss scalar
- Switching to a newer version of Megatron-LM (repo for distributed transformer)
Evaluations
- Multi-tasking: by prompt, following GPT-3
- Aimed to re-implement GPT-3 evaluation setting
- Model scale vs Average Zero-shot and Multi-shot performance is similar to GPT-3
- Dialogue dataset: perplexity is competitive to open-source supervised SOTA
- Hate Speech Detection: outperforms GPT-3-Davinci
- Intrasentence level biases: competitive to GPT-3-Davinci
- Stereotypical bias: competitive to GPT-3-Davinci
- Respond to toxic language prompt
- Higher toxicity rate than PaLM or Davinci
- All 3 models have increased likelihood of generating toxic continuations as the toxicity of the prompt increases
- Dialogue Safety
- SaferDialogues: Ability to recover from explicit safety failures (graceful vs defensive response)
- Safety Bench Unit Tests: Generating offensive content, Responding inappropriately to offensive conten, Responding inappropriately in safety-critical situation
Limitations
- Following instructions
- OPT-175B does not work well with declarative instructions
- Model tends to output a dialogue beginning with such an instruction, rather than an execution of the instruction
- Possible solution: fine-tuning similar to InstructGPT
- Repetitive behavior
- OPT-175B also tends to be repetitive and can easily get stuck in a loop
- Possible solution: unlikelihood training, or best-first decoding
- Factually incorrect statement
- Possible solution: retrieval-augmented models
- Summary: premature for commercial deployment