GPT Variants: Codex and InstructGPT
This post is mainly based on
- Codex: Evaluating Large Language Models Trained on Code, 2021
- InstructGPT: Training language models to follow instructions with human feedback, NIPS 2022
- How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources
- OpenAI: Model index for researchers
GPT-3 was trained on language model loss and not explicitly fine-tuned for downstream tasks. Codex and InstructGPT are fine-tuned GPT-3 for code completion and following human instructions. Detailed description of the relationship between GPT-3, Codex, InstructGPT and GPT-3.5 can be found in Yao Fu’s blog
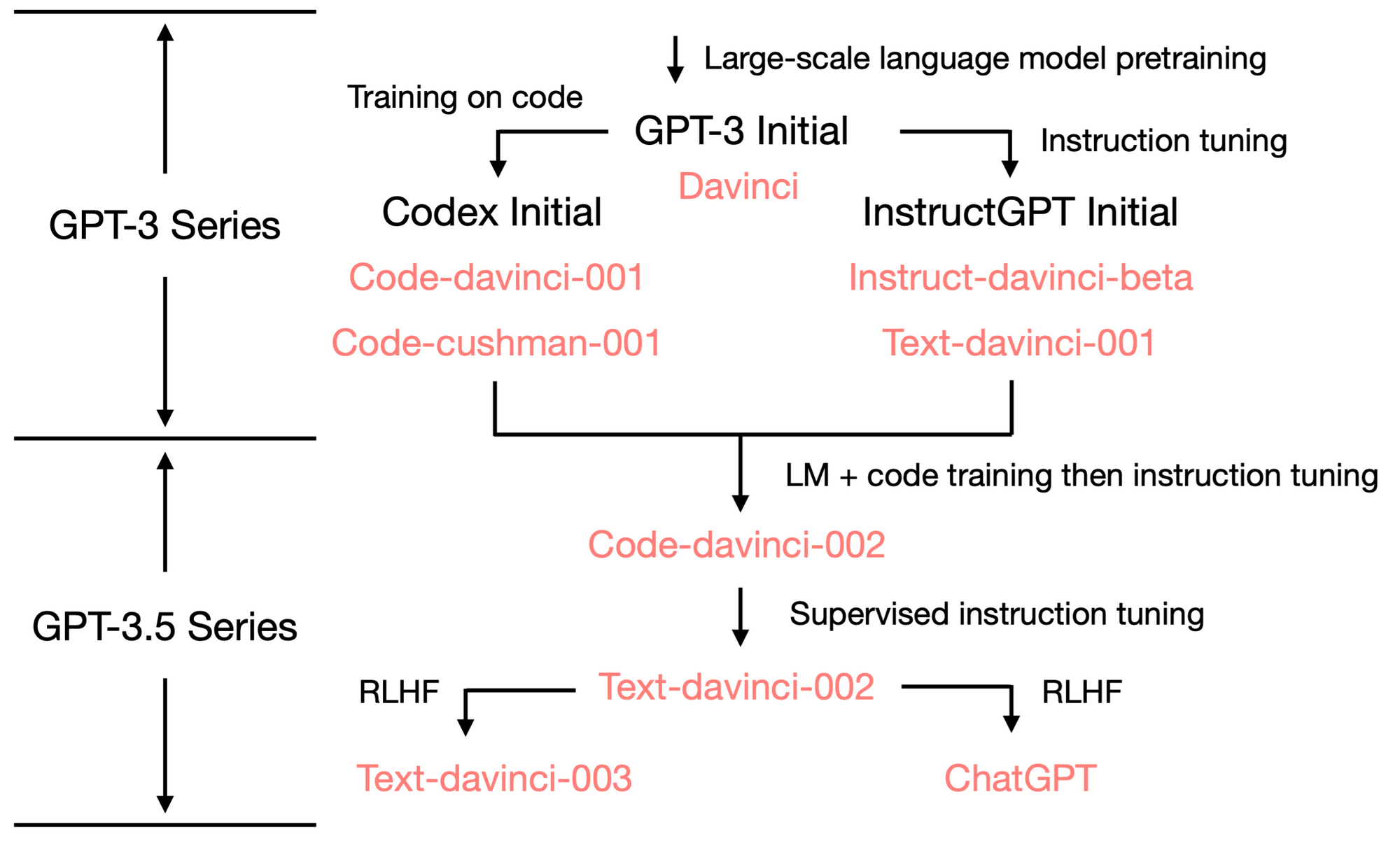
Image from Yao Fu’s blog. Red font are OpenAI’s model index.
Codex
- Fine tuned from GPT-3-12B
- Generate standalone Python functions from docstrings
- Function correctness is evaluated by unit tests
- Result
- New testing dataset
- GPT-3 solves 0% of the problems
- Codex solves 28.8% of the problems
- Codex-S solves 37.7% of the problems (generating 1 solution)
- Codex-S can solve 44.5% of the problems (generating 100 solutions, selecting highest mean log-probability)
- Codex-S can solve 77.5% of the problems (generating 100 solutions, at least 1 is correct)
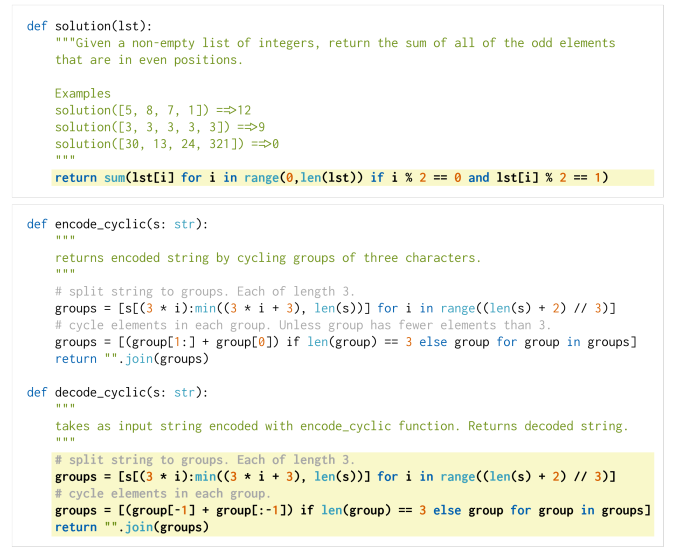
Generated samples from HumanEval dataset. The probabilities that a single sample from Codex-12B passes unit tests are 0.17 and 0.005
Training Dataset
- 54 million public software repositories hosted on GitHub, up to May 2020
- Raw data size: 179 GB of unique Python files under 1 MB
- Data cleaning / Filter out
- Likely auto-generated code
- Average line length greater than 100
- Maximum line length greater than 1000
- Contained a small percentage of alphanumeric characters
- Final data size: 159 GB
Testing Dataset: HumanEval
- Hand written 164 original programming problems with unit tests, to avoid overlapping with training set
- Problems aim to assess language comprehension, algorithms, and simple mathematics
- Each problem includes a function signature, docstring, body, and several unit tests, with an average of 7.7 tests per problem
- HumanEval dataset repo
Model
- Base model
- Does not observe improvements when training from a pre-trained GPT
- Converge more quickly from a pre-trained GPT
- Tokenizer
- GPT-3 text tokenizer + additional set of tokens (e.g., whitespace runs of different lengths)
- The BPE tokenizer apply merges based on the distribution of words
- Due to code and natural language has very different distribution, GPT-3’s tokenizer is not very effective for representing code
- The additional set of tokens reduced token count by 30%
- Codex: fine-tuned on training dataset
- Codex-S: further fine-tuned on correctly implemented standalone functions
- For 100 pass@k benchmark, samples are generated with temperature 0.8
Discussion
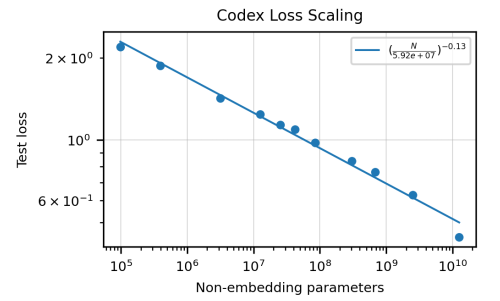
Scaling Performance
- Testing loss follows a power law in model size
- Scaling Laws for Neural Language Models
- Higher temperatures are optimal for larger sample k in pass@k, due to higher diversity
Generating Docstring
- Codex-D: produce a docstring from Python functions
- Motivation: safety, such a model can be used to describe the intent behind generated code
- Not effective due to poor data quality
- Often generates incorrect unit tests along with a docstring
- Produces docstrings like “I just found this function online” and “This test is not correctly written and it’s not my solution
InstructGPT
- Goal: solve the alignment problem
- Reinforcement learning from human feedback
- In human evaluations, outputs from the InstructGPT-1.3B are preferred than the GPT-3-175B, despite having 100x fewer parameters
- Improvements in truthfulness and reductions in toxic output generation
Alignment Problem
- Large language models (LLMs) can be “prompted” to perform a range of NLP tasks, but models often express unintended behaviors
- Making up facts
- Generating biased or toxic text
- Not following user instructions
- Alignment problem: aligning model output with user intent
- GPT-3 is pre-trained on language model loss (predicting the next token), which is different from the objective “follow user instructions helpfully and safely”
- Goal: model output should be
- Helpful (Should help the user solve their task)
- Honest (Should not fabricate information or mislead the user)
- Harmless (Should not cause physical, psychological, or social harm to people or the environment)
3-Stage Process
- SFT: Supervised Fine Tuning
- Bootstrap dataset: labelers provide demonstrations of the desired behavior on the input prompt distribution
- Fine-tune a pretrained GPT-3 model on this data using supervised learning
- RM: Reward Modelling
- Comparison data: labelers indicate which output they prefer for a given input
- Train a reward model to predict the human-preferred output
- Contrastive loss: $\log \sigma \left[ r(x, y_w; \theta) - r(x,y_l; \theta) \right]$
- Reward model: $r(x,y; \theta) \rightarrow \mathbb{R}$; win/loss output: $y_w, y_l$
- RL: Reinforcement Learning
- Optimize a policy against the reward model using PPO
Dataset
- Dataset is based on human labeler and text prompts submitted to the OpenAI API
- Labeler prompt requirement
- Task is most often specified directly through a natural language instruction (e.g. “Write a story about a wise frog”)
- Task is specified by few-shot examples (e.g. giving two examples of frog stories, and prompting the model to generate a new one)
- Task is specified by implicit continuation (e.g. providing the start of a story about a frog)
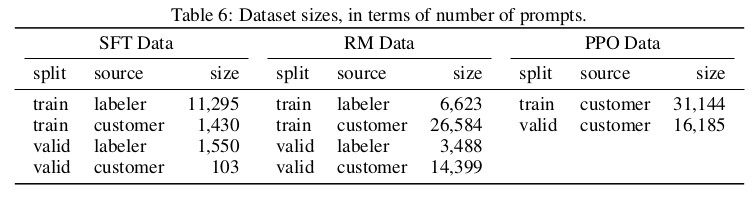
Scale of the dataset
Model Optimization
- SFT
- Model is trained for 16 epochs
- SFT models overfit on validation loss after 1 epoch
- However, despite overfitting, training for more epochs helps both the RM score and human preference ratings
- RM
- Base model: GPT-SFT-6B
- Classification head: output numeric reward
- Labelers are presented with K = 4 to K = 9 responses to rank (K choose 2 comparisons for each prompt)
- RL
- Bandit environment: presents a random customer prompt and expects a response to the prompt
- Reward determined by the RM and ends the episode
Results
- Labelers significantly prefer InstructGPT outputs
- InstructGPT shows improvements in truthfulness
- InstructGPT shows small improvements in toxicity, but not bias
Sample 1: describe code
- InstructGPT can follow instructions while GPT-3 requires more careful prompting
- InstructGPT can summarize and answer questions

Sample 2: overly hedge
- Simple mistakes in the PPO-ptx-175B
- Model output overly hedged answers, rather than directly answering simple questions
