Learning Rate vs Batch Size
This post is mainly based on
- Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour, Facebook Research
- Don’t Decay the Learning Rate, Increase the Batch Size, ICLR 2018
- TBD: Large Batch Training of Convolutional Networks
Researchers observed that large batch size lead to performance deterioration in distributed training and this leads to fundamental problem with distributed training: to utilize large dataset, model needs to be trained on larger batches, but this lead to unreliable optimization. The theory around learning rate, batch size, gradient noise and local minima is not new. A formal discussion can be found in Section 4.1 of Lecun’s 2012 paper Efficient BackProp.
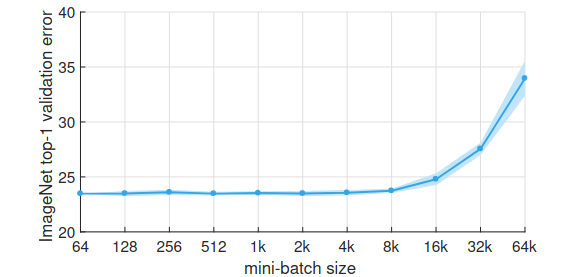
ImageNet top-1 validation error vs. minibatch size
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
This is an empirical paper. The goal is to use large batch size while maintaining training and validation accuracy. The core finding is relationship between learning rate and batch size:
Linear Scaling Rule: When the minibatch size is multiplied by k, multiply the learning rate by k.
Their interpretation for the inverse relationship is as follow: consider $k$ gradient update size with a small batch size $n$
\[w_{t+k}=w_{t}-\eta \frac{1}{n} \sum_{j<k} \sum_{x \in \mathcal{B}_{j}} \nabla l\left(x, w_{t+j}\right)\]And $1$ gradient update size with a large batch size $kn$
\[\hat{w}_{t+1}=w_{t}-\hat{\eta} \frac{1}{k n} \sum_{j<k} \sum_{x \in \mathcal{B}_{j}} \nabla l\left(x, w_{t}\right)\]They argue that setting $\hat{\eta} = k \eta$ makes $w_{t+k} \approx \hat{w}_{t+1}$. If taking $1$ gradient step with a large batch approximate taking $k$ gradient steps with a small batch, they can potentially avoid performance deterioration issue with large batch size.
The authors validated their assumption as follow. First they show that changing learning rate result in different loss curves:
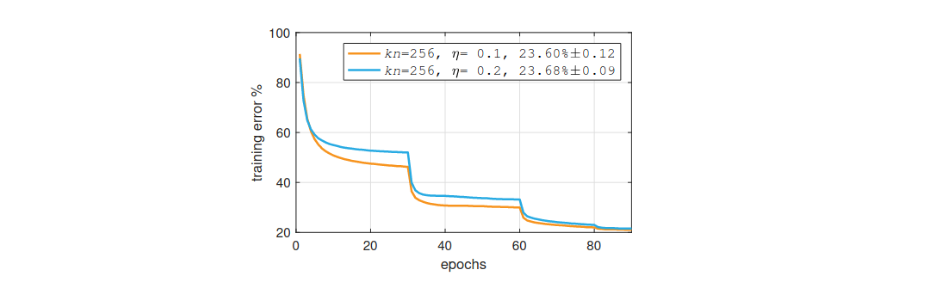
Then, they show that by following Linear Scaling Rule, they can produce almost identical loss curves up to batch size = 8k:
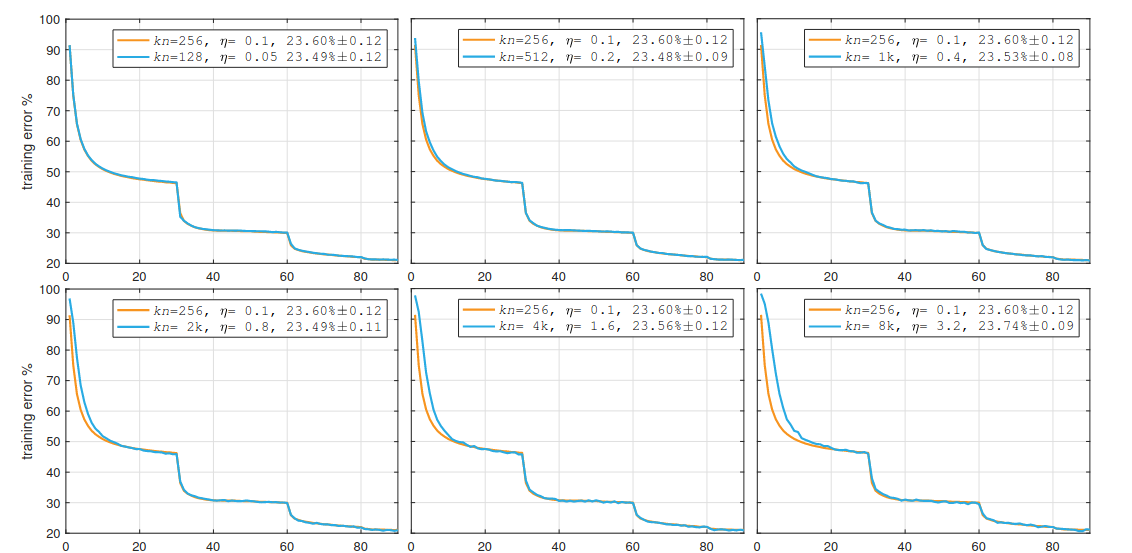
Warmup
A large batch size requires high learning rate and the authors noticed that high learning rate could cause some instability during the first few epochs of training. Previous method is using a small learning rate at the first few epoch (constant warmup) for stability. The authors show that they can achieve better result by gradually increase the small learning rate to the target rate (gradual warmup):
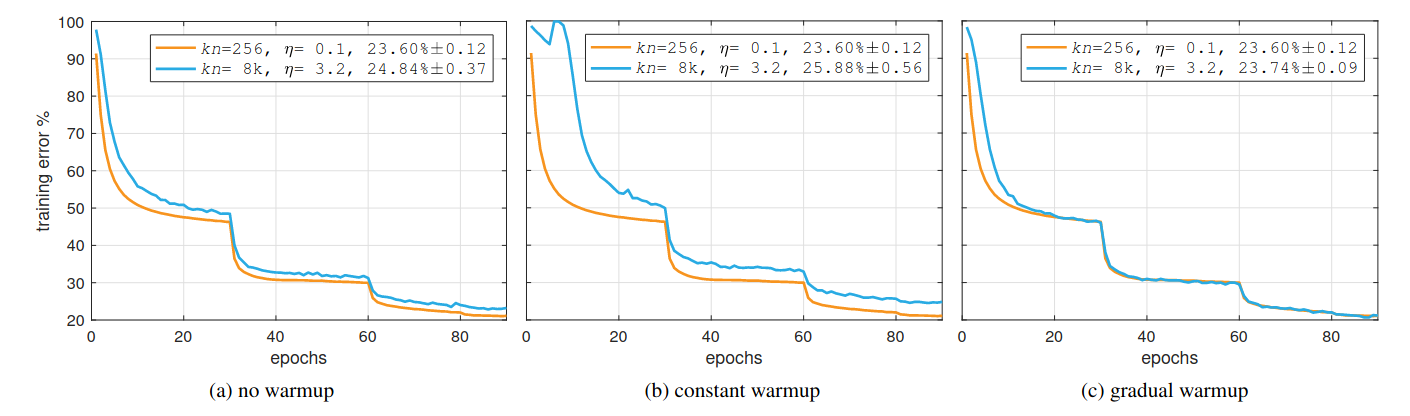
Apart from distributed training with high learning, warmup are used in some “fragile” training, for example: The Annotated Transformer
They also discussed details on batch normalization, momentum correction and gradient aggregation with distribution training. Interested reader please refer to the paper for details.
Don’t Decay the Learning Rate, Increase the Batch Size
The 2018 paper works further on the first paper’s finding: (1) The first paper reduced the base learning rate by 1/10 at the 30-th, 60-th, and 80-th epoch. If reducing learning rate is equivalent to increasing batch size, the latter should be preferred since it saves training time. Using the their training schedule, the achieve the same validation accuracy of 76.1% in under 30 minutes (compared to 1 hour in previous paper). (2) They show that Linear Scaling Rule also holds on Adam. (3) They show that scaling batch size $B$ and momentum $m$ with $B \propto 1/(1 − m)$ lead to even faster convergence, but also result in reduction in testing accuracy (their hypothesis on the reason is discussion in Section 4).
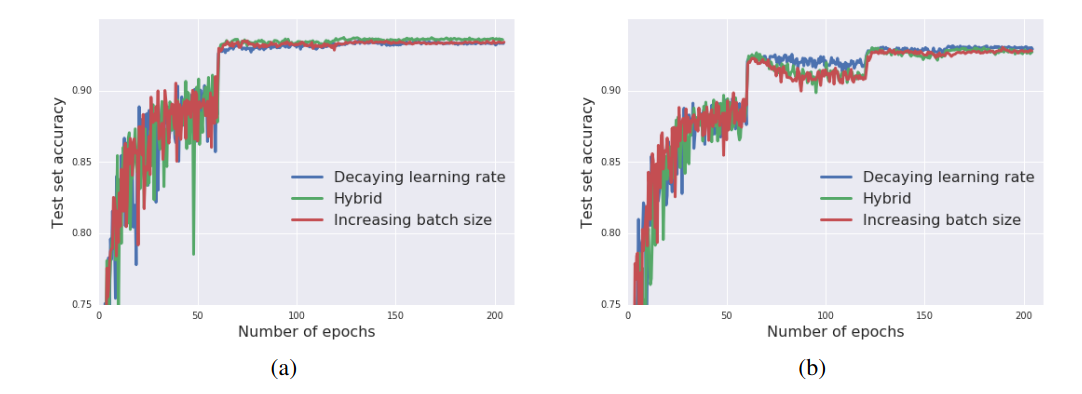 Wide ResNet on CIFAR10. The test set accuracy during training, for vanilla SGD (a) and Adam (b). Three schedules result in equivalent test set performance
Wide ResNet on CIFAR10. The test set accuracy during training, for vanilla SGD (a) and Adam (b). Three schedules result in equivalent test set performance
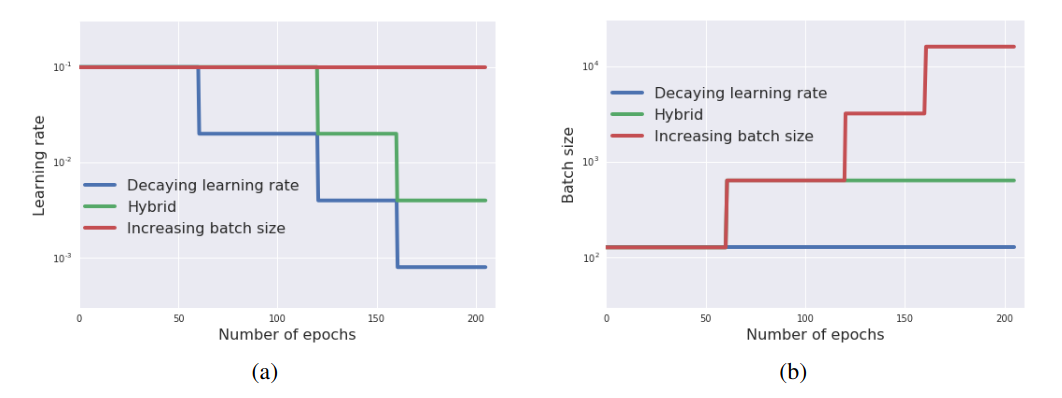 Schedules for the learning rate (a) and batch size (b), as a function of training epochs
Schedules for the learning rate (a) and batch size (b), as a function of training epochs
Afterthoughts
Distributed training is a complex problem. Many factors could be involved and we may discuss them in future posts:
- Parameter server (PS) based Synchronization / Stale Gradient Problem
- Model Parallelism / Data Parallelism
- Reduction Topologies (single vs ring)
- Scaling efficiency / Communication overhead
- Optimus (Training loss/Resource-speed modeling)
Why large batch size cause problems
I came through some preliminary works on relationship between learning rate vs batch size in this paper. The idea is to decompose the SGD gradient into expectation and noise generated by sampling:
\[\alpha \nabla_{SGD}(\theta)=\underbrace{\alpha \nabla \ell(\theta)}_{\text {gradient }}+\underbrace{\frac{\alpha}{|B|} \sum_{i \in B}\left(\nabla \ell_{i}(\theta)-\nabla \ell(\theta)\right)}_{\text {error term }}\]where SGD gradient is $\nabla_{SGD}(\theta) = \sum_{i \in B} \nabla \ell_{i}(\theta)$ and $\nabla \ell_{i}(\theta)$ is gradient from i-th training example. $\alpha$ is learning rate and $B$ is batch size. Note that we are optimization over parameters of the network $\theta$. Obviously $\nabla \ell_{i}(\theta)$ is an unbiased. Assume variance of gradient on 1 training example $\mathbb{E}[ || \nabla \ell_{i}(\theta)-\nabla \ell(\theta) ||^2 ]$ is $C$, they show that variance of SGD is determined by both learning rate $\alpha$ and batch size $B$:
\[\mathbb{E}\left[\left\|\alpha \nabla \ell(\theta)-\alpha \nabla_{SGD}(\theta)\right\|^{2}\right] \leq \frac{\alpha^{2}}{|B|} C\]Note that we are interested in the relationship between $\Delta \ell(\theta)$ vs $\alpha, B$. Although the above equation does not tell much about what we what, it give us some intuition:
- Loss surface is non-convex and optimizer could stuck in local minima, resulting in high error
- A high learning rate $\alpha$ induce noisy gradients, which possibly help the optimizer to escape sharp minima
- A high batch size $B$ induce accurate gradients, which possibly get the optimizer stuck in sharp minima