SGLang
This post is mainly based on
Intro
- SGLang: Structured Generation Language for LLMs
- Complex LLM tasks require: multiple chained generation calls, advanced prompting techniques, control flow, and interaction with external environments
- What’s in SGLang
- An efficient LLM programming language, that incorporates primitives for common LLM programming patterns
- Components: An interpreter, a compiler, and a high-performance runtime
- Optimizations: parallelism, batching, caching, sharing, and other compilation techniques
- RadixAttention
- Maintains a Least Recently Used (LRU) cache of the KeyValue (KV) cache for all requests in a radix tree
- Automatic KV cache reuse across multiple generation calls at runtime
- Findings
- Simplify LLM programs
- Boosts execution efficiency /speed up common LLM tasks by up to 5x
Primitives for Common LLM Programming Patterns
- Primitives: the basic, fundamental operations or functions that the language provides to directly support common tasks involved in LLM programming
- Prompts / generations manipulation:
extend,gen,select - Control of parallelism:
fork,join
Existing Frameworks
- Front-end oriented
- Examples: LangChain, LMQL, Guidance, and DSPy
- Developed for easy managemant of prompt templates and program pipelines
- Problems: Compromised runtime performance
- Back-end oriented
- Examples: TensorRT-LLM, Hugging Face TGI, Orca, and vLLM
- Developed for low latency and high throughput
- Problems: Design largely remains anchored in traditional single generation call interfaces, where a user prompt is processed and a response is returned in a stateless manner
This Paper
- Co-designing both the frontend language and the back-end runtime
- Create a language that is suitable for LLM programming and ecosystem integration
- Runtime Optimization: automatic parallelism, batching, caching, and sharing across multiple calls and multiple programs
- Compiler Optimization: code movement and prefetching annotations
Background
- KV Cache: in autoregressive generation, previously computed $K = W_Kx$ and $V = W_Vx$ can be stored
- Programming use of LLMs usually involves multiple shareable parts (e.g., Few-shot examples, chat history in Multi-turn chat), which could be optimized by KV Cache
- A good system should help a programmer be productive, offering an intuitive and expressive interface for common programming tasks, including LLM state management, decoding process control, and smooth integration with external tools
Language, Interpreter, and Compiler
Syntax and Primitives
Example 1
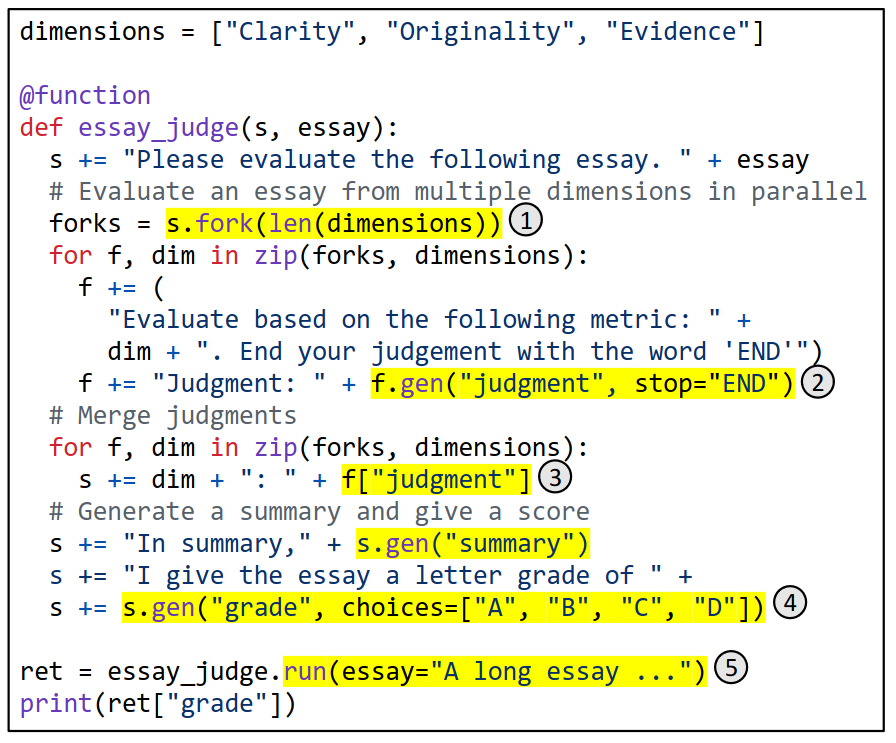
The function essay_judge takes two arguments: s and essay. The variable s manages the state of a prompt, allowing new strings and SGLang primitives to be appended using +=.
Workflow
- First adds the
essayto the prompts - Then forks the prompt into 3 copies in parallel, generating judgments from different dimensions
- Finally, merges 3 judgments, generates a summary, and assigns a letter grade to the essay
Example 2

It employs two functions:
expand: elaborates a short tip into a detailed paragraphtip_suggestion: orchestrates the entire process
Workflow
- First generates two short tips
- Then calls
expandto elaborate them in parallel - Finally generates a summary
SGLang primitives
gen: calling LLM generationselect: letting the LLM choose the option with the highest probability from a list+=orextend: extending the current promptfork: forking the current prompt statejoin: rejoining the forked prompt states
Users can interleave these primitives with arbitrary Python control flow and libraries.
Interpreter vs Compiler
- Interpreter: the most basic way to execute a SGLang program
- Compiler: compile code as computational graphs and run with a graph executor (more optimizations)
Interpreter
- Asynchronous execution / submission calls are non-blocking
- launching CUDA kernels to CUDA streams asynchronously
- Each prompt is managed by a stream executor in a background thread, enabling users to achieve parallelism
- When fetching the generation results from a prompt, the fetch action will be blocked until the desired generation results are ready
Compiler
Compile SGLang programs as computational graphs and run them with a graph executor.
Tracing and Graph Executor
The graph includes nodes for primitive operators and edges for dependencies. The graph is also called an intermediate representation (IR).
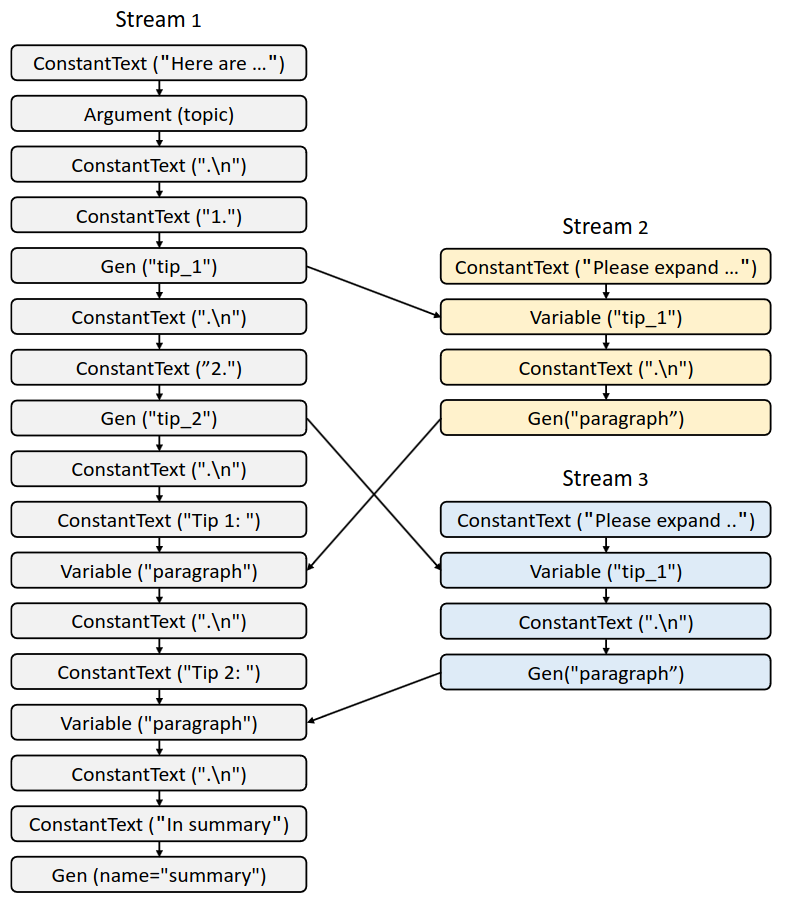
Computational Graph corresponding to the program in Example 2. The three streams correspond to three function calls.
Nodes
- Each operand of
+=and+in a SGLang program is represented by an IR node. - These operand include:
ConstantText,Argument,Gen,Select,Variable,Fork,GetForkItem, andJoin
Dependencies
- Intra-stream dependency
- Operations submitted into a stream using
+=must be executed after all preceding operations in that stream
- Operations submitted into a stream using
- Interstream dependency
- Occurs when one stream needs to fetch variable values from another stream, requires synchronization
- Operations like fork manipulate multiple streams and thus introduce inter-stream dependencies
To generate the graph, we use tracing to run the program with abstract arguments and construct the graph dynamically.
Once constructed, the graph can be executed through a graph executor, eliminating the need to reinterpret the original Python program. For execution, stream executors are launched for each data stream, dispatching IR nodes to the streams in topological order.
Compilation Optimizations
Optimization 1. Code Movement for Improving Prefix Sharing
- Improve prefix sharing by reordering nodes in the graph to increase the length of the constant prefix
- Aggressive optimization: does not strictly preserve the original computation
- Example
- Changing the prompt from “Here is a question + {question}. Please act as a math expert and solve the given question”
- To “Please act as a math expert and solve the given question. Here is a question + {question}.”
- This results in a longer sharable prefix
- GPT-4 assisted Optimization
- Traditional program analysis cannot achieve this kind of optimization
- Prompt GPT-4 to reorder graph nodes
- The authors find that GPT-4 can successfully apply this optimization for some simple SGLang programs
Optimization 2. Prefetching Annotations
- Automatically adding prefetching nodes to the graph, signaling the runtime to move the cached KV cache from the CPU to the GPU if the cache exists for a long prompt
- This can reduce the latency for pipelines with long prompts
Runtime with RadixAttention
Primary challenge of optimizing SGLang program execution: reusing the KV cache across multiple calls and programs.
Overview
- Automatic KV cache reuse during runtime
- Instead of discarding the KV cache after finishing a generation request
- Retains the KV cache for both prompts and generation results in a radix tree
- Enables: prefix search, reuse, insertion, and eviction
- Techniques to increase cache hit rate
- Least Recently Used (LRU) eviction policy
- Cache-aware scheduling policy
- Compatible with existing techniques like continuous batching and paged attention
RadixAttention
- Radix tree
- Space-efficient alternative to a trie (prefix tree)
- Why Radix tree? GPU memory is limited, need space-efficient data structure
- Radix tree is used to manage a mapping
- Mapping is between key and value
- Key: sequences of tokens
- Value: corresponding KV cache tensors of tokens
- LRU eviction policy
- Eviction policy is required due to limited GPU memory
- Evict nodes that are NOT being used by the currently running batch
- Each node maintains a reference counter indicating how many running requests are using it
- A node is evictable if its reference counter is zero
- Prompt
- The front end always sends full prompts to the runtime
- The runtime will automatically do prefix matching, reuse, and caching
- The tree structure is stored on the CPU and the maintenance overhead is small
- Cache-Aware Scheduling: sort the requests by matched prefix length, as opposed to adhering to a first-come-first-serve schedule
Evaluation
- Models: Llama 2 chat, CodeLlama, LLaVA
- Hardware: A10G, A100
- Baseline: Guidance, LMQL, vLLM
- Metrics: throughput, latency
Few-Shot In-Context Learning
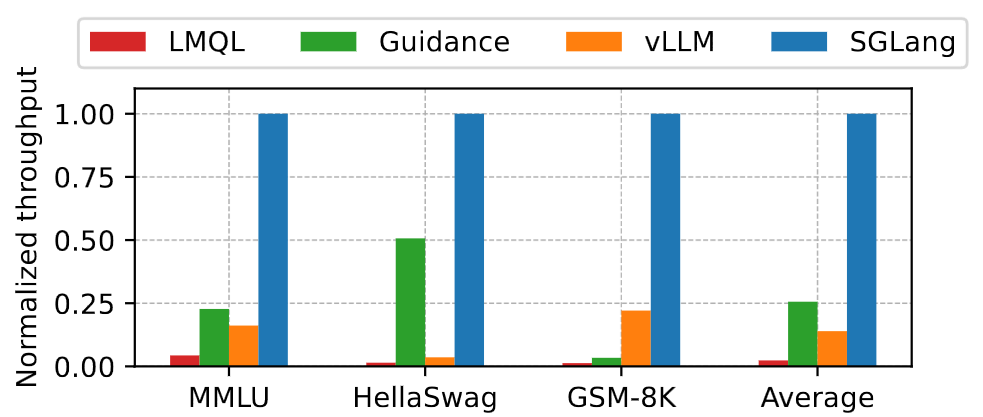
SGLang attains a throughput that is 2x-4.5x higher than its closest competitor in 3 benchmarks.
LLM-Based Agents
- ReAct agent: processes tasks in an interleaved manner by chaining multiple LLM calls with actions like web search
- Generative agent: gaming environment / agents interact with each other and make decisions by invoking LLMs
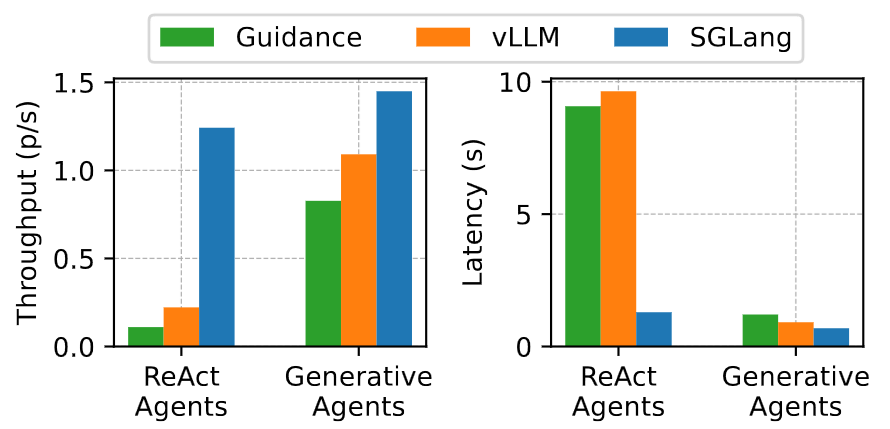
SGLang attains a throughput that is 1.3x-5.6x higher than its closest competitor in 2 benchmarks.
In ReAct agent, the improvement primarily results from the agent’s process of appending current states (thoughts, actions, and observations) to the prompt for subsequent LLM calls. RadixAttention effectively identifies and minimizes redundant computations. RadixAttention also significantly reduces memory usage, allowing more questions to be addressed by a greater number of agents, enhancing throughput.
Reasoning
- Multi-chain reasoning
- Generating several solutions to one question and using meta-reasoning across these solutions for the final answer
- For each solution generation, we use various eliciting prompts (e.g., “Think step-by-step”, “Take a deep breath”)
- The improvement in throughput is not as substantial as few-shot learning, due to the zero-shot setting having a shorter shareable prefix
- Tree-of-thought
- Incorporates LLMs into the breadthfirst tree-search algorithm
- The LLMs must propose the next steps for branch exploration, execute these proposals, and evaluate the solutions
- Requires complex sharing patterns
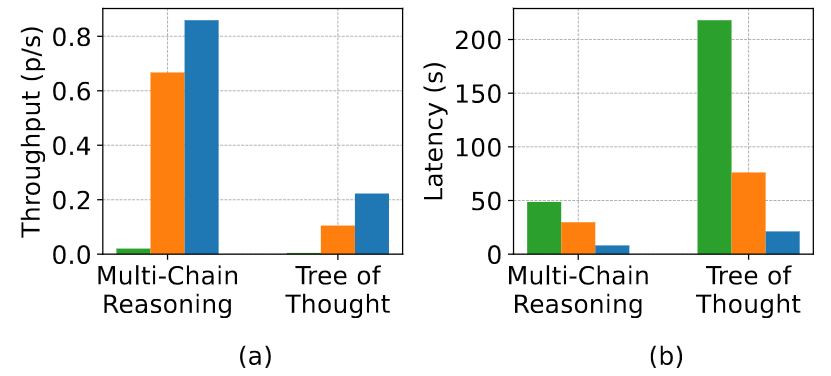
(a) Throughput on reasoning tasks. (b) Latency on reasoning tasks. Green: Guidance, Orange: vLLM, Blue: SGLang.