Long Sequence Pretraining
This post is mainly based on
- Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors, ICLR 2024
- OpenReview.net
Overview
- Notations
- TFS := Train from scratch
- SPT := Self pretraining
- Findings
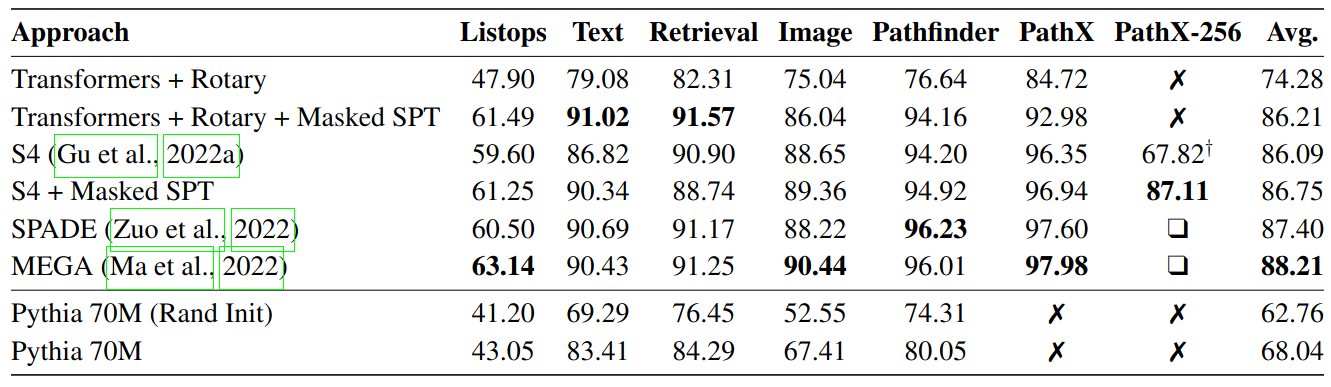
- Vanilla Transformers can match SSM on Long Range Arena with properly SPT
- SPT to also benefit S4 with performance gains in 5 out of 6 LRA tasks
- SPT leads to biases that are as effective as manual designed inductive bias across several architectures
- With denoising objectives, SPT solely on downstream training data often leads to gains comparable to pretraining on large corpora
- With proper procedure, inductive bias can be learned from data itself
- Implications on Eval Benchmarks
- SPT should be considered for a fair comparison between sequence model
LRA
- ListOps
- A nested list, with each sublist describing an operation (e.g. MAX, MEAN) to be applied on a set of tokens
- Task:
INPUT:[MAX 4 3[MIN 2 3]1 0[MEDIAN 1 5 8 9 2]] OUTPUT: 5
- Text
- A character-level version of the IMDb reviews dataset
- Task: binary classification with sequence length of up to 2048
- Retrieval
- A character-level version of the AAN dataset for predicting similarity scores of two documents
- Task: binary classification with sequence length of up to 4K, requiring to process 8K tokens for evaluation
- Image
- Grayscale CIFAR10 images are flattened as 1D sequences
- Any explicit 2D inductive bias cannot be used
- Task: 10-way classification, with sequence length 1024
- Pathfinder, PathX
- Synthetic 2D visual tasks treated as 1D sequences for testing tracing capabilities
- Sequence length: PathX=1024, Pathfinder=16384
- Task: binary classification
PathX-256: with sequence length $256^2 = 65536$ (Not part of LRA, due to too chanllenging)
Self Pretraining (SPT)
- Loss
- Causal/autoregressive sequence modeling objective
- Cross-entropy (CE) or L1 loss
- Masking ratio
- Visual tasks (Image, Pathfinder, Path-X): 50%
- Language tasks (Text, Retrieval): 15%
- ListOps: 10%
Experiments
Experiment Details
- Normalization layer for Transformers: LayerNorm in the PreNorm setting
- Finetuning a pretrained model
- Use checkpoint with highest validation accuracy for CE loss and $R^2$ score loss
- Perform a search over a small grid of log learning rates / batch sizes
- e.g. (1e-3 5e-4 1e-4) and (8 32 128)
- Hardware
- RTX 3090 or V100 GPUs
- Most models were trained for 200 epochs or 24h on a single GPU for pre-training and fine-tuning
- Transformers on PathX & Speech Commands were trained for a maximum of 5 days on 4 GPUs
- Pythia were trained for a maximum of 2 days on 4 GPUs
TFS vs SPT on Transformer
- No architectural change
- Strictly follows Long range arena paper’s configuration
- Results
- Avg score improves from ~50 to ~80
- SOTA competitive to SSMs
- Takeaways
- Performance difference can be attributed to the priors learned during SPT
- TFS severely underestimate transformer’s model capacity
- A proper training procedure is important for benchmarking
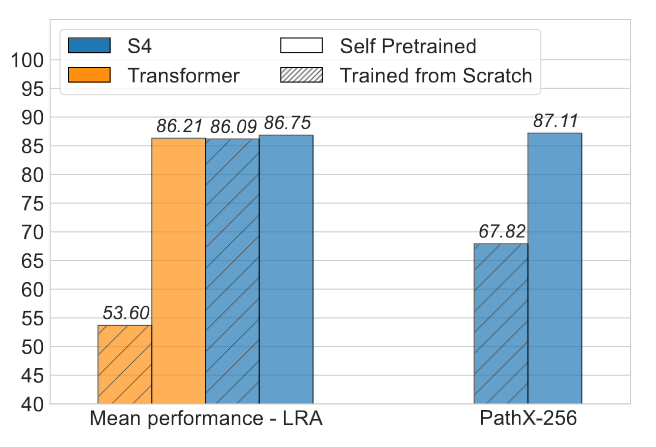
Evaluation of Transformers and S4 on Long Range Arena, TFS vs SPT.
SSM vs Transformer
- Modifications on Transformer
- Scale up model size
- Adopt rotary embeddings
- Only train bidirectional models
- Results on LRA (without PathX-256)
- Transformers with SPT see 8-15% performance gain across tasks
- S4 with SPT see <1% gain
- SPT Transformers surpass S4 on 3 out of 6 tasks
- Results on PathX-256
- S4 with SPT see 20% gain (without addtional data)
SSMs and Transformers with SPT or TFS on Long Range Arena.
Note that SPT use compute compared to the TFS. To ensure SPT’s performance gains are not an artifact of additional computational resources, we allocate additional compute resource to TFS.
TFS Training Procedure
- Train until training accuracy is almost perfect and validation performance stopped improving for multiple epochs
- Train until training loss stopped reducing
Results: Transformer on PathX
- TFS
- Result: $\leq$ 52% training accuracy
- Computation: 8 epochs (equivalent to 2 days on 4 V100 GPUs)
- SPT
- Result: $\geq$ 78% training accuracy
- Computation: 1 day SPT, 1 day finetuning
- Conclusion: performance gains can be attribute to improved generalization
SPT vs TFS Under Same Compute Budget
- Motivation: Compare SPT and TFS under strict compute budget
- Procedure: Total number of epochs is fixed, but the SPT/TFS ratio of epochs varies.
- Results: SPT leads to significant gains, even in the setting where the same amount of compute is used for SPT and TFS.
Comparison of SPT and TFS models in a compute-tied setting. A modest amount of SPT outperforms or closely matches the TFS baseline.
Explicit Priors
- Motivation
- S4’s high performance can be attribute to HiPPO theory and carefully designed matrix $A$
- Various simplifications are proposed (e.g., S4D) while roughly maintains S4 performance
- Question: can SPT enable an even simpler model to match S4 performance
- Simpler model: diagonal linear RNN (DLR)
S4 hidden state update
\[x_n = A x_{n-1} + Bu_n\]where $A = \Lambda - PQ^*$
DLR hidden state update
\[x_n = \Lambda x_{n-1} + \mathbb{1} u_n\]Initializations
- Random initialization: state space parameters are initialized from a normal distribution with a small standard deviation
- Structured initialization: initialization recommended by the respective authors to model long-range dependencies
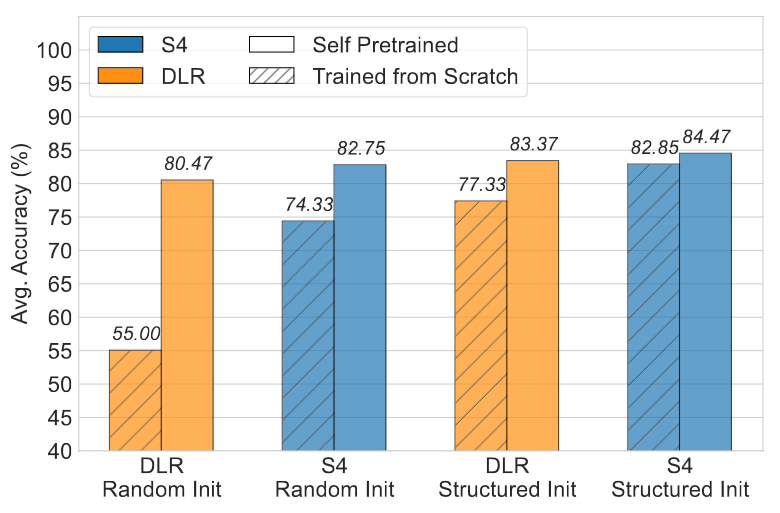
Avg performance when TFS vs SPT, for different sets of initializations.
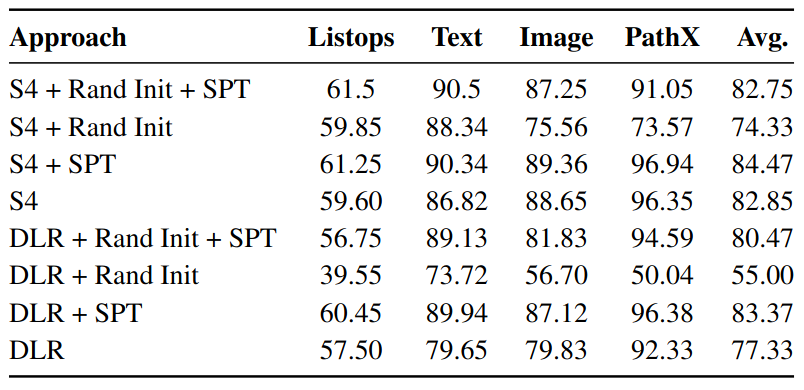
Per task performance when TFS vs SPT, for different sets of initializations.
Results
- Without SPT
- With both random and structured initializations, DLR lags behind S4
- Indication: specific initialization and parameterization used in S4 are critical to performance
- With SPT
- DLR outperforms TFS S4 and is only slightly behind SPT S4
- Indication: data-driven priors learned through SPT are almost as effective as the S4’s theory-dirven biases
- First instance where vanilla diagonal linear RNNs have been shown to achieve competitive performance on LRA
- Implies explicit steps are less significant when models are self pretrained
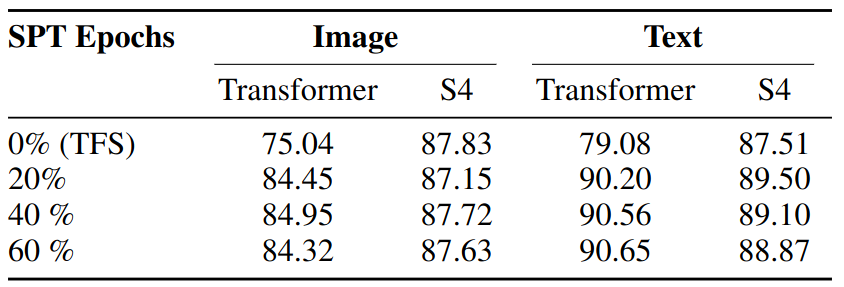
SPT is Effective Across Data Scales
- Motivation
- Priors learned via SPT are data-driven
- Hence, SPT efficacy is dependent on the training set itself
- Question: what is SPT’s performance gains across different the dataset size
- Procedure
- Given a downstream task, randomly sample a subset of the training set
- Restrict SPT to a fixed number of update steps across all experiments, then finetune until convergence
- Results
- SPT improves S4 performance across data scales
- Relative gain is most significant (~30%) on smaller data scales
- Conclusion
- Priors from pretraining are especially effective when training data is scarce
- Incorporation of the pretraining is important for model evaluation regardless of dataset size
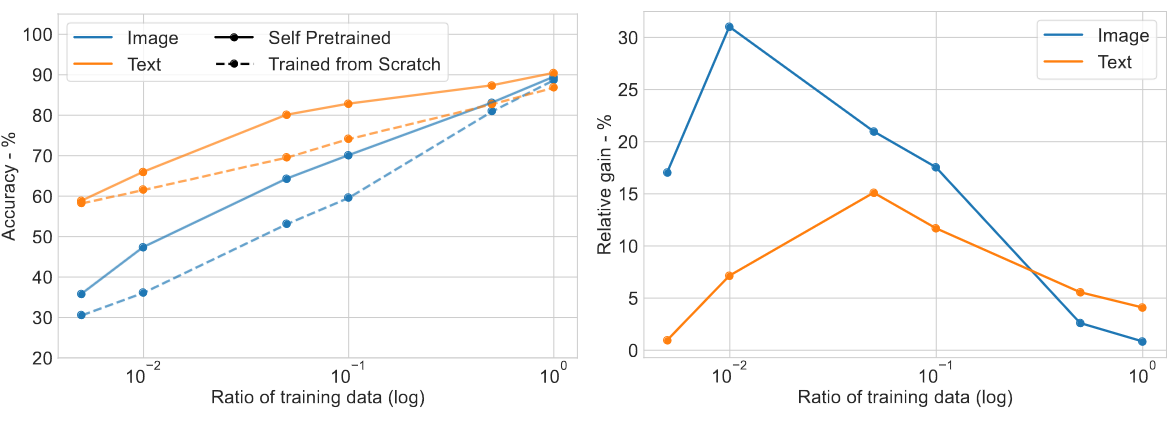
SPT and TDS on Image and Text tasks from LRA, originally containing 45K and 25K samples respectively. Left: absolute performances gain; Right: relative performances gain.
SPT is Effective Across Model Scales
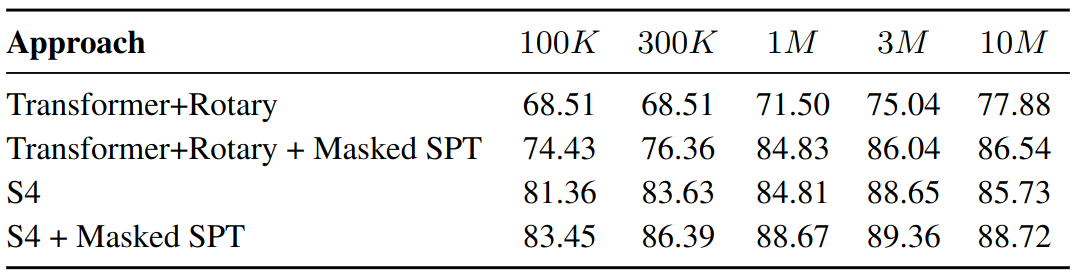
Performance on Image task across model sizes with SPT & trained from scratch. First Row: model sizes. SPT is effective across model scales.
Theory-Driven vs Data-Driven Kernels
- Theory-Driven Kernels (S4, S4D, S5)
- Manually-crafted priors to bias the model towards long range dependencies
- HiPPO measure determines the decay rate of the convolution kernels over time
- Data-Driven Kernels (SPT)
- Memory decay solely depend on the input distribution and the pretraining objective
- Motivation: compare the structure of Theory-Driven vs Data-Driven Kernels
Given channel $c$ and timestep $k$, consider the convolution operator in SSMs:
\[y_{c,k} = \sum_{l=0}^k K_{c,l} x_{c, k-l} = \sum_{l=0}^k \bar{C}^\top_c \bar{A}^l_c \bar{B}_c x_{c, k-l}\]For channel $c$, we can estimate the degree of dependence between current and $l$-shift back element as:
\[\text{Dependency} = | K_{c,l} |\]To estimate the degree of dependence on $l$-shift back element across all channels:
\[\text{Dependency} = | K_{\max,l} | = \max_c | K_{c,l} |\]For a fixed shift $l$, $K_{\max,l}$ bounds the norm of the derivative of $y_{c,k}$ w.r.t $x_{c,k−l}$ for all positions $k$ and channels $c$.
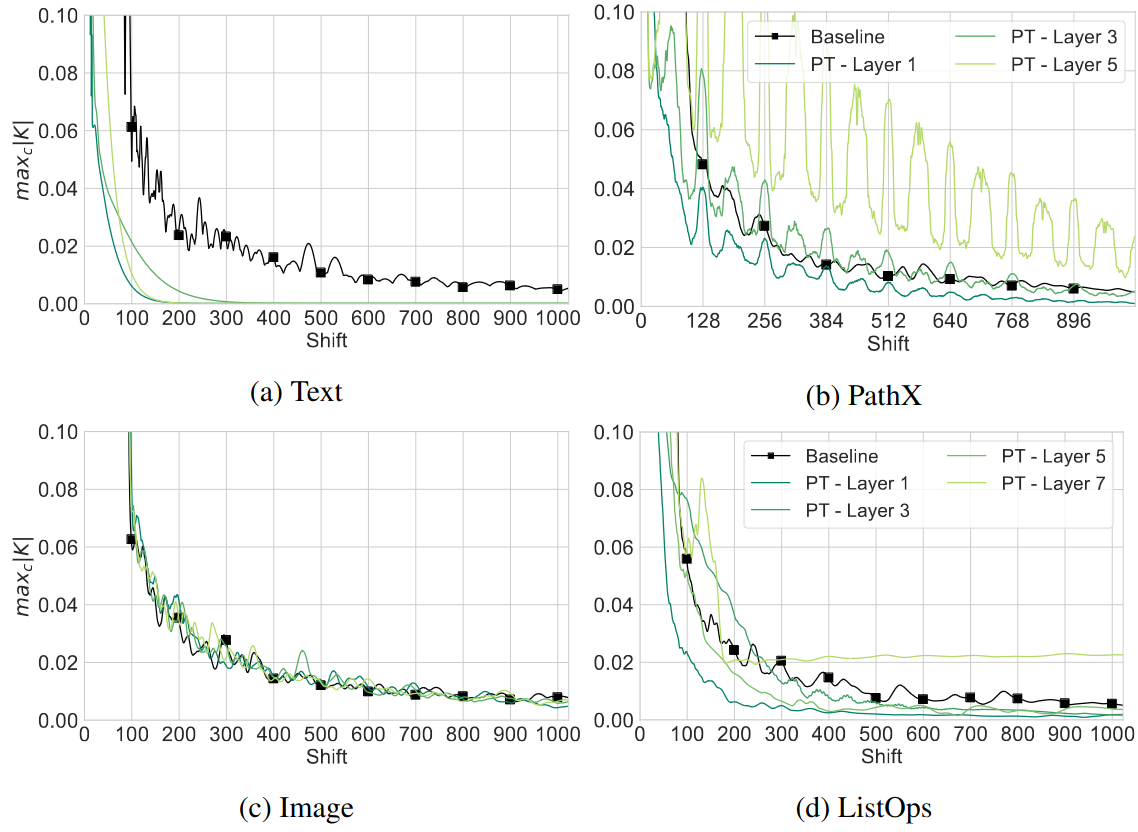
The figure below visualize $K_{\max,l}$ at different shift $l$, on Image, Text, PathX and ListOps datasets
- Compare
- Fixed HiPPO kernels ($B,C$ are learned, $A$ is fixed)
- Data driven kernels learned by SPT
- Results
- Learned kernels exhibit variable decay rates across the tasks and model layers
- Text: the learned kernels are more local compared to HiPPO
- PathX
- Shifts are correspond to different pixels in an 128 $\times$ 128 image
- Dependency between different shifts show patterns
- High correlation between the underlying 2D structure of the data and the kernel peaks
- Conclusion
- Data-Driven Kernels: adapt to a local or global structure in a task distribution
- Theory-Driven Kernels: more data-agnostic / cannot adapt
SPT on Real-World Datasets
- SPT masking
- SC, BIDMC: 25% masked, causal denoising objective
- sCIFAR: 50%
- Transformer modification
- To tackle length / VRAM usage
- For 16k-length SC sequences, split the input to non-overlapping blocks of size 4000 and allow each block to attend to itself and its neighbours
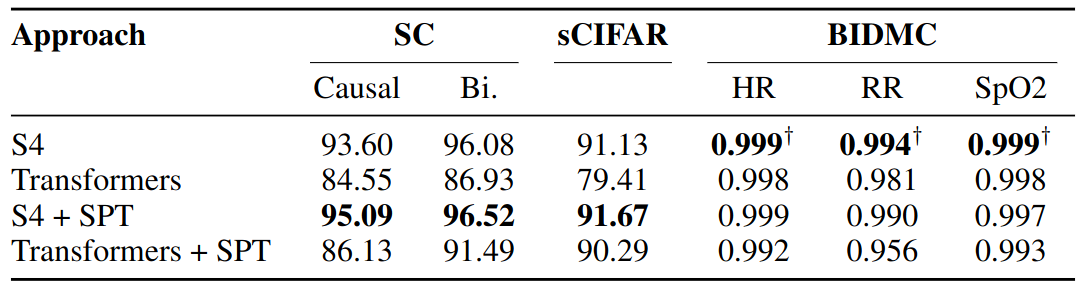
Results
- The authors do not emphasize this part, but I think these are also quite important findings
- On discrete signal dataset (sCIFAR)
- SPT significantly improves Transformer performance (~10%).
- On continuous signal datasets (SC and BIDMC)
- SSMs still hold considerable advantage over Transformer
- SPT hurt Transformer performance on BIDMC and only provide marginal gain on SC